[논문리뷰] Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sanket Badhe, Deep Shah
1. Key Terms & Definitions (핵심 용어 및 정의)
- Prompt-Level Distillation (PLD): Teacher 모델의 추론 패턴을 추출하여 Student 모델의 System Prompt에 주입하는 비파라미터 방식의 지식 전이 프레임워크입니다.
- DBSCAN: 추출된 미세 지시사항(micro-instruction)들을 의미론적 유사도에 따라 군집화하고 노이즈를 제거하기 위해 사용된 밀도 기반 클러스터링 알고리즘입니다.
- Closed-Loop Conflict Resolution: 모델이 추론 과정에서 범한 오류를 분석하여, System Prompt 내 상충하는 논리 규칙을 수정하고 정제하는 반복적인 피드백 루프입니다.
- System Prompt: Student 모델이 Zero-shot 환경에서도 Teacher 모델 수준의 추론 능력을 발휘할 수 있도록, 도출된 논리적 휴리스틱이 집약된 핵심 프롬프트 영역입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 복잡한 추론을 위해 필수적인 Chain-of-Thought (CoT)가 초래하는 높은 Latency와 연산 비용 문제를 해결하기 위해 고안되었습니다. 기존의 Knowledge Distillation (KD) 방식인 모델 Fine-tuning은 파라미터 업데이트에 따른 유지보수 부채와 리소스 소모, 그리고 추론 과정의 불투명성이라는 한계를 가집니다. 따라서 저자들은 파라미터 업데이트 없이도 Zero-shot 성능을 극대화할 수 있는 새로운 추론 전이 프레임워크가 필요하다고 정의합니다 [Figure 1].
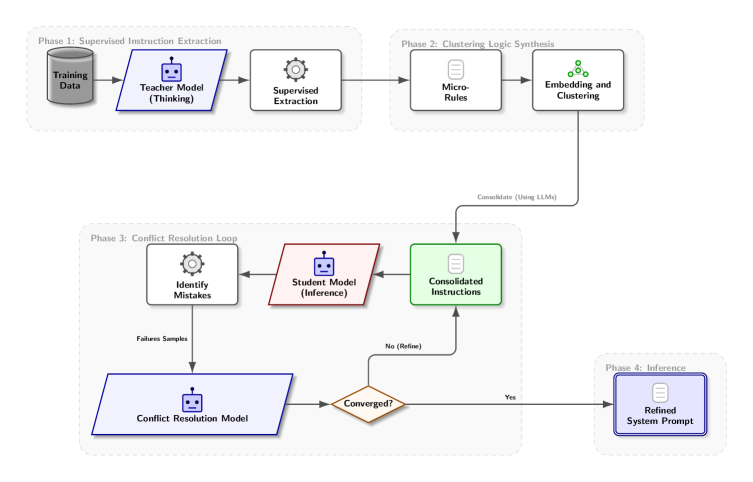
Figure 1 — PLD 프레임워크 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Supervised Instruction Extraction, Clustering Logic Synthesis, Closed-Loop Conflict Resolution으로 구성된 4단계 파이프라인인 PLD를 제안합니다 [Figure 1]. Teacher 모델을 활용해 학습 데이터에서 명시적인 의사결정 규칙을 추출하고, 이를 DBSCAN으로 군집화하여 일반화된 논리 집합을 생성합니다. 이후, 모델 성능을 검증하며 상충하는 규칙을 제거하는 Conflict Resolution 과정을 거쳐 최종 System Prompt를 완성합니다. 실험 결과, Gemma-3 4B 모델에 PLD를 적용했을 때 StereoSet 데이터셋에서 Macro F1 점수가 0.57에서 0.90으로, Contract-NLI에서는 0.67에서 0.83으로 크게 향상되었습니다. 또한, 해당 방식은 Mistral Small 3.1과 같은 다양한 아키텍처에서도 일관된 성능 향상을 보이며, 대형 모델 대비 Latency와 연산 효율성 측면에서 압도적인 우위를 확보했습니다 [Table 1].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 추론 역량을 모델 가중치가 아닌 System Prompt로 내재화하는 PLD 프레임워크를 통해, 효율적인 경량 모델의 성능을 frontier 수준으로 끌어올릴 수 있음을 입증했습니다. 이 접근법은 파라미터 업데이트를 제거하여 유지보수 비용을 획기적으로 줄이고, 의사결정 과정을 가시화하여 신뢰성이 중요한 법률 및 금융 분야에서 강력한 대안으로 작용할 것입니다. 향후 본 연구는 복잡한 논리 제약이 요구되는 산업계의 Edge device 및 고성능 추론이 필요한 다양한 환경에서 핵심적인 역할을 할 것으로 기대됩니다.
Part 2: 중요 Figure 정보

Figure 1 — PLD 프레임워크 전체 아키텍처
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- [논문리뷰] Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
- [논문리뷰] Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
- [논문리뷰] Implicit Reasoning for Large Language Model-based Generative Recommendation
Review 의 다른글
- 이전글 [논문리뷰] PhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions
- 현재글 : [논문리뷰] Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
- 다음글 [논문리뷰] Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
댓글