[논문리뷰] A Gradient Perspective on RLVR Stability and Winner Advantage Policy Optimization
링크: 논문 PDF로 바로 열기
저자: Prasanth YSS, Zhichen Ren, Rasa Hosseinzadeh, Ilan Gofman, Yuqi Chen, Zhaoyan Liu, Guangwei Yu, Jesse C. Cresswell, Satya Krishna Gorti
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 논리적 추론이나 계획 수립을 개선하기 위해 검증 가능한 보상 체계를 사용하는 강화학습 기법입니다.
- GRPO (Group Relative Policy Optimization): 오프라인 샘플을 활용하여 롤아웃 그룹 내에서 상대적인 이점을 계산하고, 이를 통해 정책을 업데이트하는 효율적인 RL 기법입니다.
- WAPO (Winner Advantage Policy Optimization): 저자들이 제안하는 기법으로, 양의 이점(Positive-advantage)을 가진 completions만을 사용하여 정책 업데이트를 수행하는 최적화 방법입니다.
- C(p): 토큰 확률 분포에서 'Peak' 토큰과 'Valley' 토큰을 구분하는 적응형 참조 레벨(Adaptive reference level)입니다.
- Collapse: 강화학습 과정 중 모델이 정답이 아닌 반복적이거나 무의미한 패턴으로 수렴하여 학습 성능이 저하되는 현상입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 RLVR 학습 과정에서 발생하는 빈번한 모델 Collapse 문제를 토큰 단위의 경사(Gradient) 역학 관점에서 분석합니다. 기존의 GRPO 스타일 최적화 기법들은 오프라인 샘플을 재사용하는 과정에서 정책 드리프트나 비대칭적인 경사 업데이트로 인해 학습이 불안정해지는 한계가 있습니다. 특히, 기존의 신뢰 영역(Trust-region) 기반의 클리핑 기법들은 모든 발산(Divergent) 토큰을 단순히 억제하려 시도하지만, 이는 오히려 학습 안정성을 저해하거나 성능을 정체시키는 원인이 됩니다. 저자들은 이러한 현상을 해결하기 위해 토큰의 경사가 로컬 확률 분포에 미치는 영향을 이론적으로 규명하고자 합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 토큰의 확률 분포 내에서 'Peak'와 'Valley'를 정의하고 보상의 부호에 따라 4가지의 업데이트 영역(Quadrant)을 구분하는 새로운 분류법을 제시합니다. 이 이론에 따르면, 양의 보상을 가진 Peak 토큰과 Valley 토큰에 대한 업데이트만이 학습을 안정적으로 유도하며, 음의 보상을 가진 업데이트는 종종 모델의 급격한 성능 저하를 초래함을 확인했습니다. 이를 바탕으로 고안된 WAPO는 양의 이점(Positive-advantage)만을 선택적으로 마스킹하여 업데이트함으로써, 복잡한 제약 없이도 안정적인 학습 성능을 보장합니다 [Figure 4]. 주요 실험 결과, WAPO는 OTT-QA 데이터셋에서 기존 최상위 안정 모델 대비 Qwen3-4B 기준 9.9%, Gemma3-4B 기준 10.6% 의 성능 향상을 기록했습니다. 또한, 다양한 모델 패밀리 및 데이터셋에서 DAPO, GRPO, GSPO 대비 일관된 학습 안정성과 우수한 pass@k 결과를 입증했습니다 [Table 4].
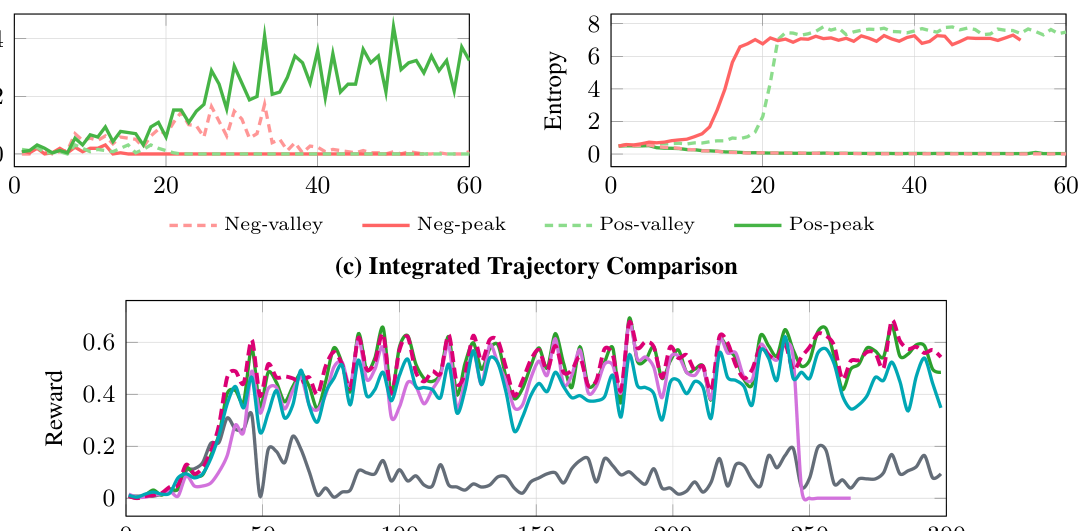
Figure 4 — 제안하는 토큰 분류 체계(Peak-Valley)에 따른 학습 역학 비교 및 검증
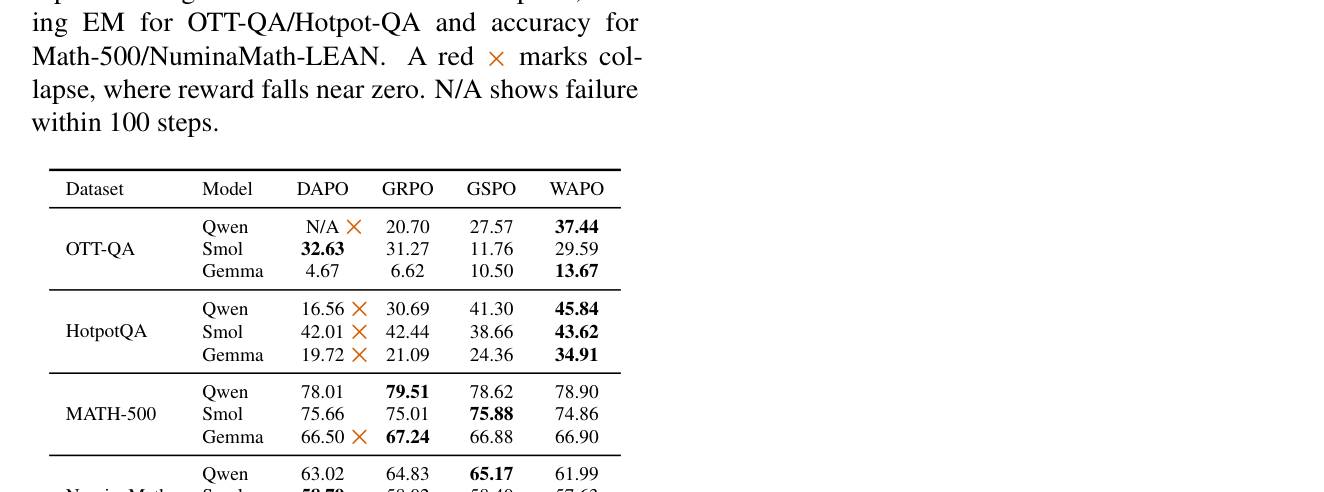
Table 4 — 다양한 모델 및 데이터셋에 대한 WAPO의 성능 비교 및 안정성 우위 입증
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 토큰 레벨의 경사 분석을 통해 RLVR의 근본적인 불안정성 원인을 밝혀내고, 이를 효과적으로 제어하는 WAPO 최적화 기법을 제시합니다. 제안된 방법론은 복잡한 하이퍼파라미터 튜닝 없이도 기존 RLVR 방법론이 가진 Collapse 문제를 해결하며, 더 안정적인 탐색과 수렴을 가능하게 합니다. 이 연구는 강화학습을 활용한 언어 모델의 추론 능력 향상 과정에서 성능과 안정성 사이의 트레이드오프를 개선하는 데 중요한 이론적 토대를 제공합니다. 향후 MoE(Mixture of Experts) 아키텍처나 더 큰 규모의 모델로 확장 적용할 가능성을 제시한다는 점에서 학계 및 산업계에 기여할 바가 큽니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
- [논문리뷰] Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
- [논문리뷰] Heterogeneous Agent Collaborative Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] Who Should Lead Decoding Now? Tracking Reliable Trajectories for Ensembling Masked Diffusion Language Models
- 현재글 : [논문리뷰] A Gradient Perspective on RLVR Stability and Winner Advantage Policy Optimization
- 다음글 [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
댓글