[논문리뷰] ReMMD: Realistic Multilingual Multi-Image Agentic Verification for Multimodal Misinformation Detection
링크: 논문 PDF로 바로 열기
저자: Chenhao Dang, Dantong Zhu, Jun Yang, Conghui He, Weijia Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- ReMMDBench: 다국어, 다중 이미지, 복합적인 왜곡(distortion) 상황을 포함하는 실제 운영 환경 기반의 Multimodal Misinformation Detection 벤치마크입니다.
- ReMMD-Agent: Atomic Representation과 Memory-Augmented Retrieval을 활용하여 신뢰할 수 있는 evidence 기반의 구조적 판단을 수행하는 에이전트 프레임워크입니다.
- Atomic Representation: 긴 소셜 미디어 게시물을 검증 가능한 수준의 작은 단위(클레임, 이미지 바인딩, 관찰 데이터)로 분해하는 표현 기법입니다.
- Memory-Augmented Retrieval: 검증 과정에서 확보된 evidence를 지속 가능한 메모리 뱅크에 저장하여, 이후 다른 atomic point 검증 시 재사용함으로써 효율성을 극대화하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실제 소셜 미디어 환경의 복잡한 다중 모달 허위 정보(misinformation)를 탐지하기 위한 기존 벤치마크와 모델들의 한계를 해결하고자 합니다. 기존 연구들은 주로 단일 이미지-텍스트 쌍이나 짧은 캡션 위주의 정적인 환경에 국한되어 있어, 실제 운영 환경에서 발생하는 긴 다국어 서사, 다중 이미지 provenance, 그리고 세밀한 왜곡 등을 처리하는 데 어려움이 있습니다 [Figure 1, Table 1]. 이러한 현실적인 격차를 해소하기 위해 저자들은 다각적인 검증 압박이 실시간으로 발생하는 Agentic Verification 기반의 평가 환경을 구축하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 게시물을 Atomic Representation으로 분해하고, Memory-Augmented Retrieval을 통해 evidence를 누적 관리하는 ReMMD-Agent를 제안합니다 [Figure 3]. 제안된 에이전트는 검색된 evidence를 persistent memory에 저장하여 검증 효율을 높이고, 이를 기반으로 구조화된 L1/L2/L3 출력을 생성합니다. 실험 결과, ReMMD-Agent는 GPT-5.2 백본을 사용했을 때 41.80%의 Accuracy와 39.12%의 macro-F1으로 최상의 5단계 veracity 성능을 기록하였습니다 [Table 4]. 특히, 기존 모델 대비 검색 비용을 MMD-Agent 대비 17.5%, T^2^-Agent 대비 79.9%까지 절감하며 높은 경제성을 입증하였습니다 [Table 6]. 이러한 성능 향상은 복잡한 긴 게시물에서도 안정적으로 작동하며, 다양한 언어와 왜곡 유형에 걸쳐 높은 전이 능력을 보여줍니다 [Figure 5].
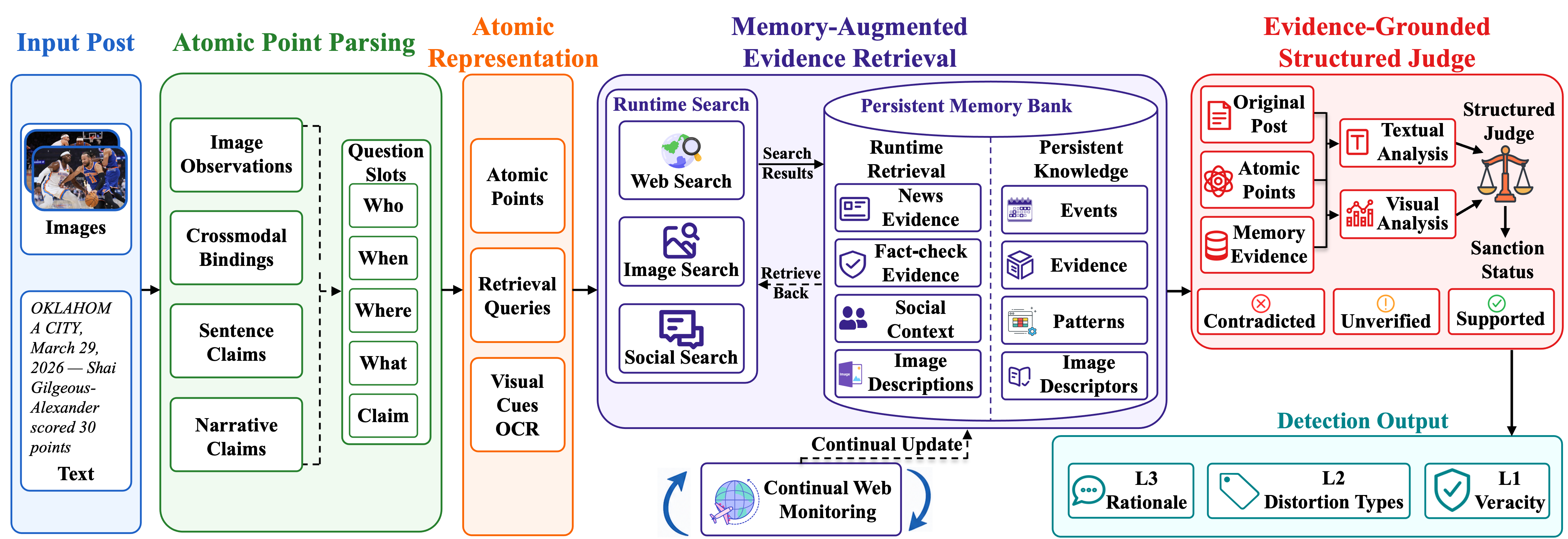
Figure 3 — ReMMD-Agent 프레임워크
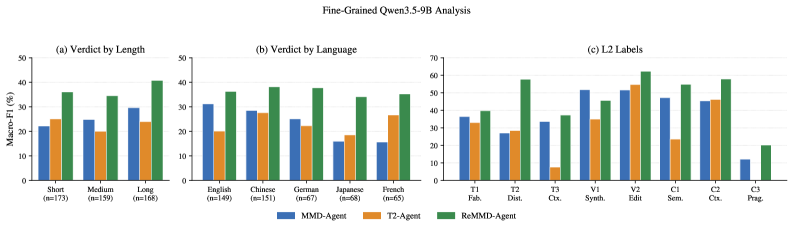
Figure 5 — 세부 성능 분석 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 다중 모달 허위 정보 탐지가 단순히 인식(perception)의 문제가 아니라, evidence의 선택, 근거 확인(grounding), 그리고 설명 가능한 관리(management)의 문제임을 강조합니다. 제안된 ReMMDBench와 ReMMD-Agent는 실제 운영 환경에서 요구되는 복잡한 검증 조건을 성공적으로 모사하고 해결책을 제시합니다. 이 연구는 학계의 평가 기준을 보다 현실적인 환경으로 고도화하고, 산업계의 자동화된 허위 정보 방어 시스템을 위한 효율적이고 신뢰할 수 있는 방법론을 제공한다는 측면에서 중요한 의의를 갖습니다.
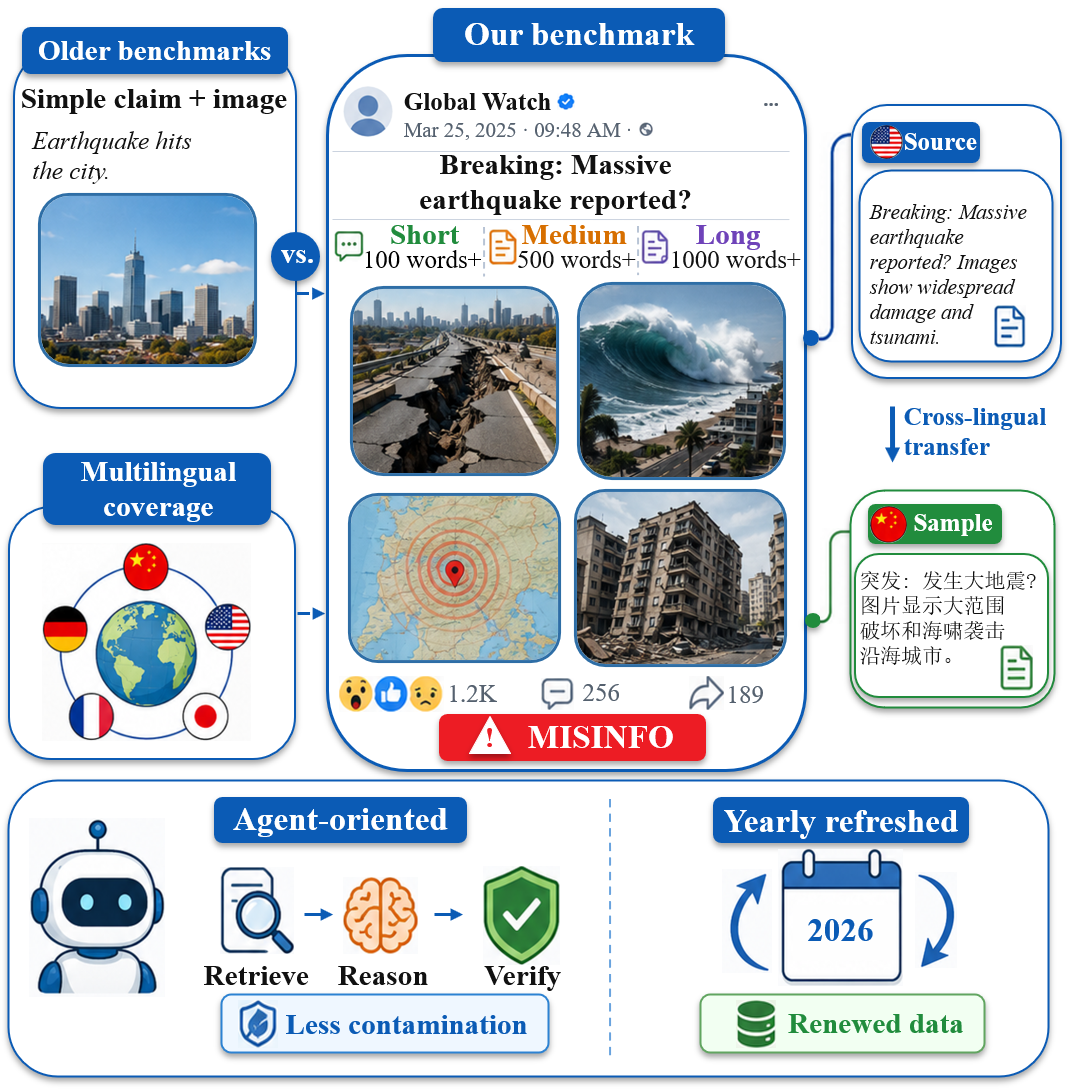
Figure 1 — ReMMDBench 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] mSCoRe: a Multilingual and Scalable Benchmark for Skill-based Commonsense Reasoning
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
Review 의 다른글
- 이전글 [논문리뷰] Qwen-AgentWorld: Language World Models for General Agents
- 현재글 : [논문리뷰] ReMMD: Realistic Multilingual Multi-Image Agentic Verification for Multimodal Misinformation Detection
- 다음글 [논문리뷰] World Value Models for Robotic Manipulation
댓글