[논문리뷰] Qwen-AgentWorld: Language World Models for General Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuxin Zuo, Zikai Xiao, Li Sheng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LWM (Language World Model): 에이전트의 현재 상태와 행동을 입력받아, 환경의 다음 상태(Next-state)를 예측하는 언어 모델 기반의 시뮬레이터입니다.
- Unified Environment Trajectory Schema: 서로 다른 7개 도메인(Terminal, Android 등)의 데이터를 일관된 형식의 (Action, Observation) 쌍으로 구성하여 학습에 활용하는 프레임워크입니다 [Figure 3].
- Decoupled/Unified Paradigm: LWM을 독립된 환경 시뮬레이터로 활용하는 방식(Decoupled)과, 에이전트 자체의 성능 향상을 위한 기초 모델(Foundation Model)로 통합하는 방식(Unified)을 의미합니다 [Figure 1].
- AgentWorldBench: 실제 환경에서의 상호작용을 기반으로 구축된 벤치마크로, 오픈 엔드 형태의 Rubric 평가를 통해 LWM의 시뮬레이션 품질을 측정합니다.
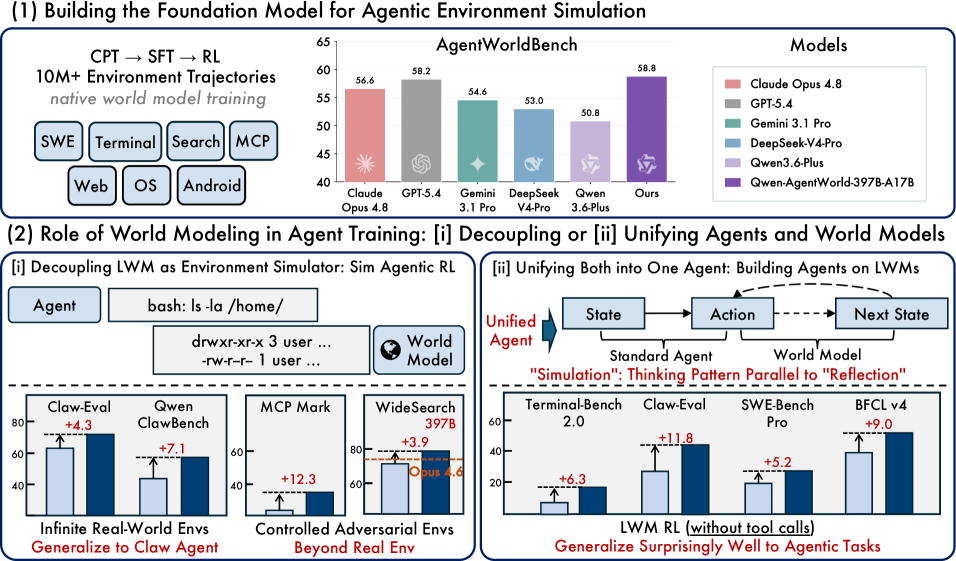
Figure 1 — Qwen-AgentWorld 전체 개요
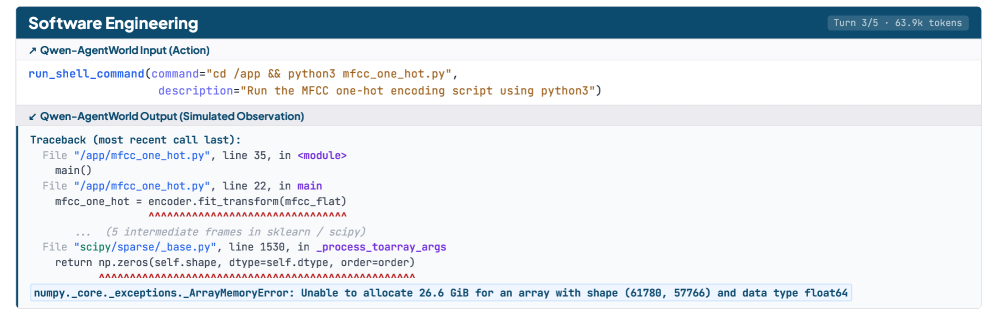
Figure 3 — Terminal 환경 시스템 프롬프트 구조
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 대규모 언어 모델(LLM) 기반 에이전트가 효과적으로 작동하기 위해 필수적인 환경 시뮬레이션 능력, 즉 World Model의 부재를 해결하고자 합니다. 기존 연구는 에이전트의 정책(Policy) 결정에만 집중할 뿐, 환경의 동역학을 예측하는 World Model 구축에는 소홀했습니다. 이로 인해 에이전트가 복잡하고 긴 호흡의(Long-horizon) 실제 환경에서 예측 기반의 행동 교정이나 안정적인 시뮬레이션 환경 구축이 어렵다는 한계가 존재합니다. 따라서 저자들은 다양한 도메인을 포괄하는 범용 LWM을 통해 에이전트의 학습 효율과 범용성을 극대화하는 새로운 접근 방식을 제안합니다 [Figure 1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Qwen-AgentWorld라는 3단계 학습 파이프라인(CPT, SFT, RL)을 제안하여 7개 도메인에 걸친 범용 LWM을 구축했습니다. 먼저 Continual Pre-Training (CPT)을 통해 상태 전이 동역학을 주입하고, Supervised Fine-Tuning (SFT)으로 다음 상태 예측을 위한 추론 능력을 활성화하며, 최종적으로 Reinforcement Learning (RL)을 통해 하이브리드 보상 프레임워크를 기반으로 시뮬레이션 정밀도를 극대화했습니다 [Figure 2]. 주요 실험 결과, Qwen-AgentWorld는 기존의 Frontier 모델들을 능가하는 시뮬레이션 성능을 보였으며, 특히 수천 개의 실제 환경 시뮬레이션을 가능하게 하여 대규모 에이전트 학습에 기여했습니다. 또한, LWM 학습을 에이전트 기초 모델의 Warm-up 단계로 활용했을 때, 7개 에이전트 벤치마크 전반에서 성능이 향상되는 정량적 우위를 확인했습니다 [Table 1]. 이는 단순 환경 시뮬레이션을 넘어, 에이전트가 미래를 예측하며 행동을 정교화하는 메타 인지 능력을 갖추게 함을 시사합니다.

Figure 2 — 7개 도메인을 통합한 LWM
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Qwen-AgentWorld를 통해 언어 모델이 어떻게 범용적인 에이전트 환경 시뮬레이터로 기능할 수 있는지를 성공적으로 입증했습니다. 이 연구는 LWM이 에이전트의 정책 학습뿐만 아니라, 예측 기반의 자기 교정 및 환경 적응력을 높이는 핵심 파운데이션임을 증명했습니다. 학계 및 산업계 전반에 걸쳐 에이전트 학습을 위한 고비용의 실제 환경 의존도를 낮추고, 제어 가능한(Controllable) 시뮬레이션 환경을 제공함으로써 에이전트 연구의 새로운 패러다임을 제시할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
- [논문리뷰] AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
- [논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
- [논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
Review 의 다른글
- 이전글 [논문리뷰] QG-MIL: A Gated Transformer Aggregator for Domain-Agnostic Multiple Instance Learning in Medical Imaging
- 현재글 : [논문리뷰] Qwen-AgentWorld: Language World Models for General Agents
- 다음글 [논문리뷰] ReMMD: Realistic Multilingual Multi-Image Agentic Verification for Multimodal Misinformation Detection
댓글