[논문리뷰] Distill Once, Adapt Life-Long: Exploring Dataset Distillation for Continual Test-Time Adaptation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hyun-Kurl Jang, Jihun Kim, Hyeokjun Kweon, Kuk-Jin Yoon
1. Key Terms & Definitions (핵심 용어 및 정의)
- CTTA (Continual Test-Time Adaptation): 모델이 배포 후 변화하는 Target 도메인에 레이블 없이 온라인으로 적응하면서, 장기적인 분포 변화 속에서도 성능을 유지해야 하는 환경을 지칭합니다.
- Dataset Distillation (DD): 대규모 소스 데이터를 압축하여, 원본 데이터의 정보를 보존하면서도 훨씬 적은 수의 학습 가능한 합성 샘플(synthetic samples)을 생성하는 기술입니다.
- Source-Distilled Anchors: DD를 통해 생성된 합성 입력, 소프트 레이블, 그리고 잠재 특징(latent feature)으로 구성된 정보 덩어리로, CTTA 과정에서 모델의 안정적인 참조점 역할을 합니다.
- Harm-Adaptive Blending: 적응 과정에서 발생한 과도한 파라미터 변화가 소스 모델의 성능을 저해하지 않도록, 그래디언트 정보를 바탕으로 불안정한 파라미터 그룹을 소스 초기값으로 되돌리는 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 CTTA 환경에서 발생하는 Catastrophic Forgetting과 Self-training 오류의 누적 문제를 해결하기 위해 DO-ALL 프레임워크를 제안합니다. 기존의 Source-Free CTTA 연구들은 원본 데이터셋을 보유하지 않는 환경에서 안정성을 확보하기 위해 다양한 통계적 지표를 활용해 왔으나, 긴 시간 동안 발생하는 분포 변화(distribution shift) 앞에서는 Representation Drift를 효과적으로 억제하지 못하는 한계가 있었습니다 [Figure 1]. 저자들은 완전한 데이터셋을 보관하는 대신, Dataset Distillation을 활용해 소스 도메인의 핵심 지식을 compact하고 개인정보 보호가 가능한 형태로 유지함으로써, 적응 과정에서 안정적인 가이드라인을 제공해야 할 필요성을 제시합니다.
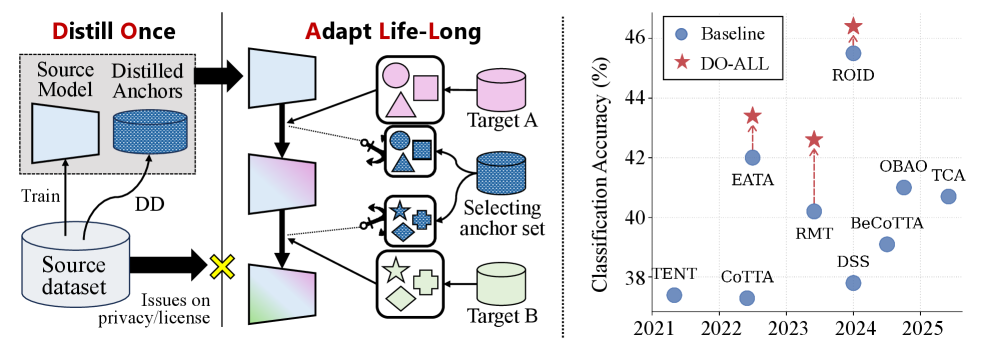
Figure 1 — DO-ALL 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 DO-ALL 프레임워크를 통해 배포 전 Dataset Distillation을 수행하고, 적응 과정에서 각 Target 샘플을 가장 의미론적으로 유사한 소스 앵커와 대응시키는 방식을 제안합니다 [Figure 2]. 핵심 방법론은 크게 세 가지로 구성됩니다: 첫째, Anchor-based replay loss를 통해 소스 지식을 보존하고 Target과 앵커 간의 MixUp을 수행하여 결정 경계(decision boundary)를 부드럽게 합니다. 둘째, Layer-wise MMD objective를 사용하여 잠재 공간 내에서 타겟과 앵커의 특징 분포를 정렬합니다. 셋째, Harm-adaptive blending을 도입하여 적응 중 발생하는 유해한 파라미터 drift를 선별적으로 복구합니다 [Figure 2].
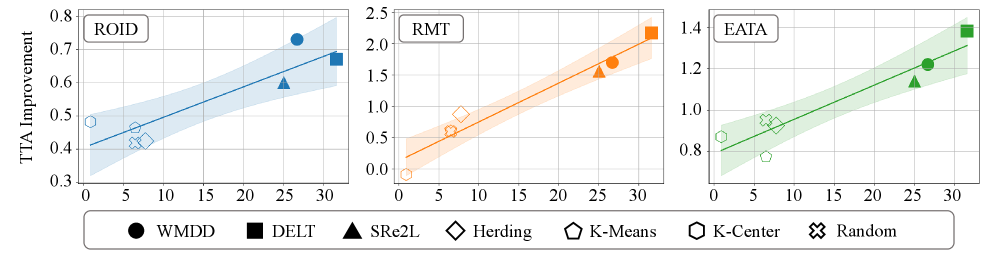
Figure 2 — DO-ALL 상세 적응 과정
실험 결과, DO-ALL은 ImageNet-C 및 CCC benchmark 등 다양한 CTTA 환경에서 기존 Baseline 모델(예: EATA, RMT, ROID) 대비 일관된 성능 향상을 입증했습니다. 구체적으로 ImageNet-C 환경에서 ROID 모델에 적용했을 때 평균 에러율을 54.5%에서 53.6%로 개선하였으며, CCC benchmark의 Hard 시나리오에서도 13.2%에서 15.5%의 정확도 향상을 기록했습니다 [Table 2, Table 3]. 이는 DO-ALL이 다양한 기존 CTTA 알고리즘과 원활하게 결합 가능한 Plug-and-Play 모듈임을 입증하며, 데이터 품질과 적응 안정성 간의 양의 상관관계를 통해 DD 기술이 CTTA 성능 제고에 핵심적인 역할을 함을 증명했습니다 [Figure 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Dataset Distillation이 Continual Test-Time Adaptation의 안정성을 높이기 위한 compact한 메모리이자 안정화 도구로 활용될 수 있음을 효과적으로 증명했습니다. DO-ALL은 모델 아키텍처를 수정하지 않고도 기존 알고리즘의 성능을 보완할 수 있는 실용적인 프레임워크를 제공합니다. 이 연구는 프라이버시가 중요한 배포 환경에서 소스 데이터 없이도 강력한 적응 능력을 확보할 수 있는 새로운 이정표를 제시하며, 향후 온라인 학습 분야에서 압축된 지식(distilled knowledge)을 일반적인 안정화 Prior로 활용하는 연구의 촉매제가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GEAR: Guided End-to-End AutoRegression for Image Synthesis
- [논문리뷰] Formalizing Latent Thoughts: Four Axioms of Thought Representation in LLMs
- [논문리뷰] SP^3: Spherical Priors for Plug-and-Play Restoration
- [논문리뷰] Implicit Reasoning for Large Language Model-based Generative Recommendation
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
Review 의 다른글
- 이전글 [논문리뷰] Constraint Tax in Open-Weight LLMs: An Empirical Study of Tool Calling Suppression Under Structured Output Constraints
- 현재글 : [논문리뷰] Distill Once, Adapt Life-Long: Exploring Dataset Distillation for Continual Test-Time Adaptation
- 다음글 [논문리뷰] DomainShuttle: Freeform Open Domain Subject-driven Text-to-video Generation
댓글