[논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shuo Yang, Jinyang Wu, Zhengxi Lu, Yuhao Shen, Fan Zhang, Lang Feng, Shuai Zhang, Haoran Luo, Zheng Lian, Zhengqi Wen, Jianhua Tao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic RL: LLM을 에이전트로 활용하여 장기적인 상호작용 및 도구 사용을 최적화하는 강화학습 패러다임입니다.
- On-Policy Skill Distillation (OPID): 완료된 on-policy 궤적에서 사후(hindsight) 기술을 추출하고, 이를 통해 모델에 dense한 token-level 지도 신호를 제공하는 학습 프레임워크입니다.
- Hierarchical Skills: 궤적 전반을 요약하는 episode-level skills와 특정 핵심 단계의 의사결정 지식을 담은 step-level skills의 계층 구조를 의미합니다.
- Critical-First Routing: 의사결정의 중요도에 따라 step-level skill을 우선 적용하고, 그렇지 않은 경우 episode-level skill을 사용하는 기술 라우팅 메커니즘입니다.
- Skill Advantage: skill이 적용된 맥락과 원본 맥락 간의 log-probability 차이를 계산하여 도출한 token-level 자가 증류(self-distillation) 이득입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 에이전트 강화학습에서 outcome-based RL의 희소하고 지연된 보상이 중간 의사결정에 대한 세밀한 신용 할당(credit assignment)을 제공하지 못하는 문제를 해결합니다 [Figure 1]. 기존의 skill-conditioned 방법론들은 외부 skill 라이브러리나 검색된 privileged context에 의존하여 유지보수 비용이 크고, 현재 정책이 유도하는 상태 분포와 불일치할 위험이 있습니다. 이러한 한계를 극복하기 위해 저자들은 별도의 외부 자원 없이, 모델이 스스로 생성한 궤적에서 직접 기술을 추출하고 증류하는 OPID를 제안합니다.
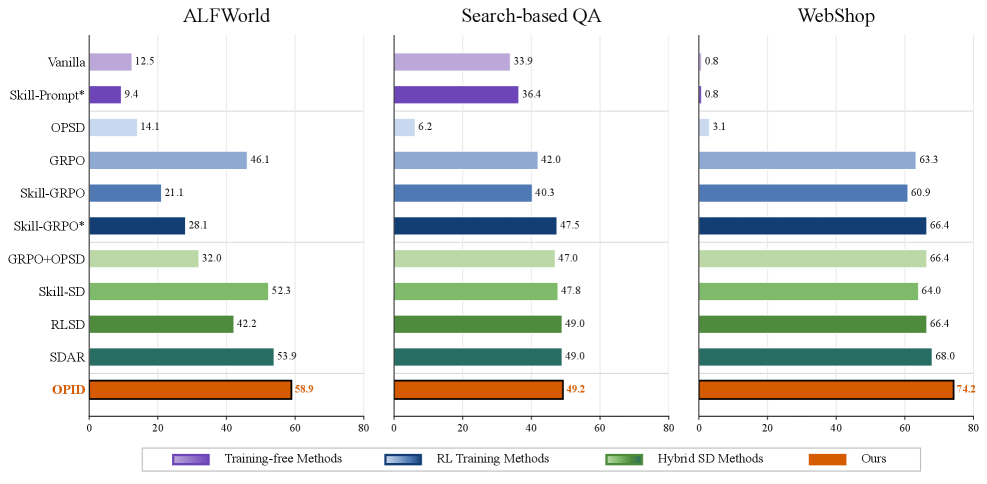
Figure 1 — 전체 성능 비교 요약
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 On-Policy Skill Distillation (OPID)을 통해 완료된 궤적에서 계층적 기술을 추출하고 이를 정책 학습에 통합합니다 [Figure 2]. 저자들은 LLM 기반 분석기를 활용해 episode-level 및 step-level 기술을 추출하며, critical-first routing을 통해 각 단계에 최적화된 지침을 제공합니다. 학습 시, 기존 정책은 routed skill이 포함된 맥락에서 동일한 응답을 다시 scoring하여 token-level의 skill advantage를 생성하고, 이를 episode advantage와 결합하여 최적화합니다 [Table 1]. 실험 결과, ALFWorld, WebShop, Search-based QA 벤치마크에서 OPID는 outcome-only RL 및 기존 skill-distillation 방법론들보다 우수한 성능을 보였습니다. 특히 Qwen2.5-7B-Instruct 모델 기준 ALFWorld에서 높은 성공률을 달성했으며, 향상된 sample efficiency와 더불어 추론 시 추가적인 외부 analyzer나 검색 없이도 더 견고한 에이전트 행동을 보장합니다 [Figure 3].
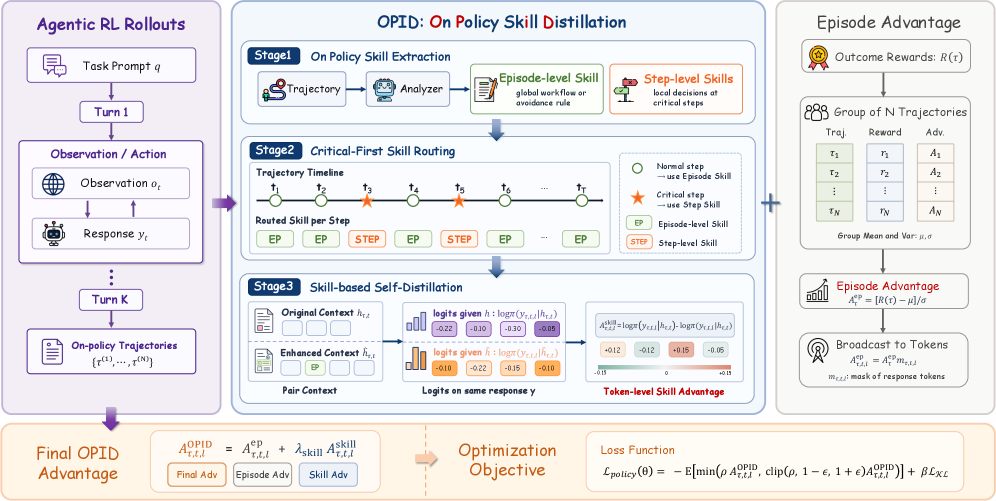
Figure 2 — OPID 전체 파이프라인
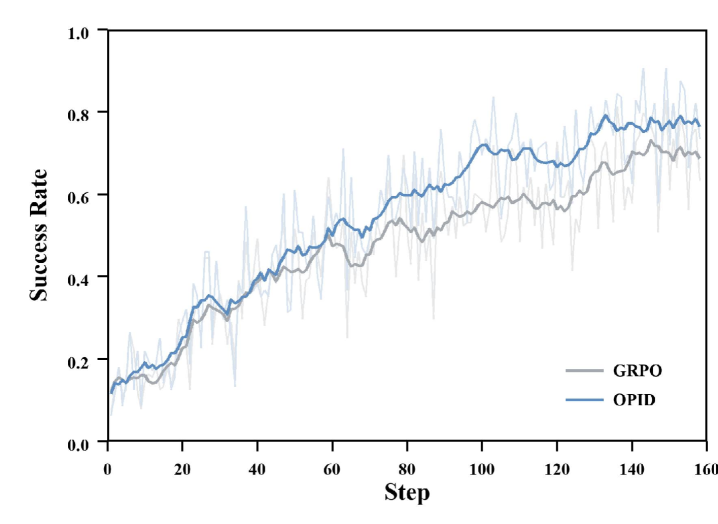
Figure 3 — 학습 역학 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 에이전트가 완료된 궤적에서 스스로 기술을 사후 추출하고 이를 정책에 증류함으로써, 외부 지식 없이도 더욱 지능적인 행동을 학습할 수 있음을 입증했습니다. OPID는 강화학습의 안정적인 보상 최적화와 dense한 token-level 지도를 성공적으로 결합한 효율적인 대안을 제시합니다. 이러한 접근 방식은 향후 장기적인 의사결정이 필요한 복잡한 에이전트 시스템에서 모델의 성능을 향상하고, 학습 데이터의 활용도를 극대화하는 데 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes
- [논문리뷰] Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent
- [논문리뷰] DanceOPD: On-Policy Generative Field Distillation
- [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
- [논문리뷰] ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation
Review 의 다른글
- 이전글 [논문리뷰] JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
- 현재글 : [논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
- 다음글 [논문리뷰] OpenBioRQ: Unsolved Biomedical Research Questions for Agents
댓글