[논문리뷰] OpenBioRQ: Unsolved Biomedical Research Questions for Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Minbyul Jeong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OpenBioRQ: 해결되지 않은(unsolved) 생의학 연구 질문들로 구성된 벤치마크로, LLM agent의 문헌 합성 및 Grounding 능력을 평가하기 위한 데이터셋입니다.
- Wrong-Paper Citation: 식별자(PMID 등)는 유효하여 실재하는 문서를 가리키지만, 정작 해당 문서가 모델이 주장하는 내용을 뒷받침하지 않는 인용 오류를 의미합니다.
- Agentic Collapse: 난도가 높은 질문에서 모델이 외부 도구(tool) 활용을 포기하고 스스로 답을 생성하려 하는 현상으로, 이로 인해 도구 활용의 이점이 사라지는 결과를 초래합니다.
- Frozen Per-Question Checklist: 모델의 답변을 평가하기 위해 사전에 생성되어 고정된 질문별 체크리스트로, 평가자 간 일관성을 높이고 주관적 판단 오류를 최소화하는 장치입니다.
- L1/L2 Audit: 인용 신뢰성을 검증하는 2단계 평가로, L1은 식별자가 실제로 존재하는지(Existence)를, L2는 인용된 문서가 해당 주장을 실제로 뒷받침하는지(Content Support)를 확인합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 LLM 평가 벤치마크들이 정해진 정답(ground-truth)이 있는 질문들만을 다룸으로써, 실제 환경에서 발생하는 치명적인 오류 유형을 간과하고 있다는 문제를 제기합니다 [Figure 1]. 특히, 모델이 인용을 생성할 때 99% 이상이 실제 존재하는 문서를 가리킴에도 불구하고, 약 15.9%는 내용과 관련 없는 잘못된 문서를 인용하는 Wrong-Paper Citation 문제가 발생함을 발견했습니다. 이러한 현상은 기존의 정답 기반 평가 방식으로는 식별 불가능하며, 모델의 신뢰성 검증에 심각한 공백을 야기합니다. 따라서 저자들은 인용의 정당성과 모델의 추론 행태를 정밀하게 측정할 수 있는 새로운 Agentic 벤치마크가 필요하다고 주장합니다.
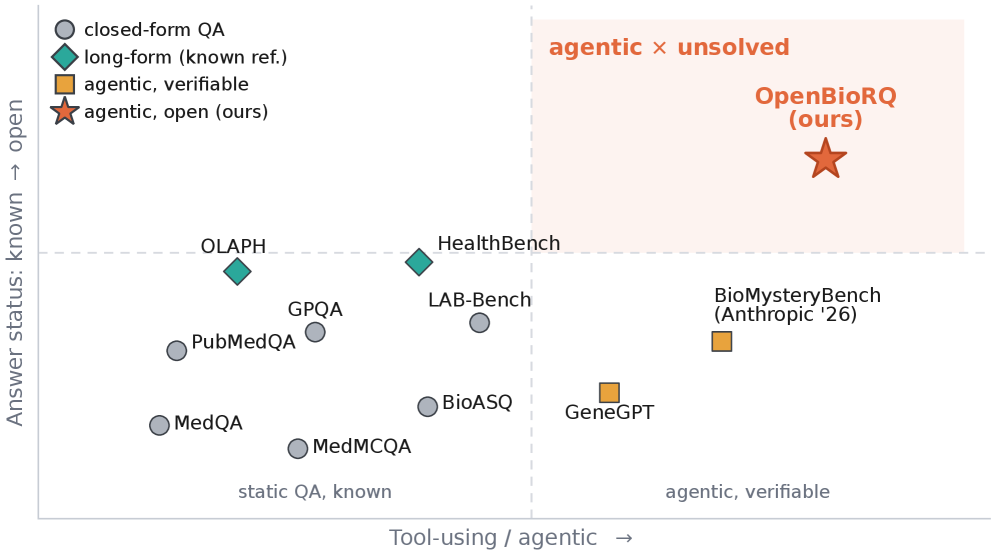
Figure 1 — 기존 벤치마크 대비 OpenBioRQ 위치
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 12,553개의 미해결 생의학 연구 질문을 수집하여 OpenBioRQ를 구축하고, 이를 Retrieval-Grounded 방식의 Faithfulness 평가 프레임워크로 활용합니다. 제안된 방법론은 고정된 질문별 체크리스트(Frozen Checklist)를 통해 평가자 간 일관성을 확보하며(Spearman 0.35에서 0.82로 향상), 모델이 외부 도구를 사용하는 멀티 라운드 추론 과정을 평가합니다 [Figure 4]. 실험 결과, 최신 Frontier 모델들조차 핵심 난제 질문들에 대해 29%~60%의 정답률을 보이며 여전히 33%~40% 이상의 질문을 해결하지 못해, 본 벤치마크가 변별력 있는 고난도 평가임을 입증했습니다 [Figure 4]. 또한, 도구 활용이 가장 필요한 난제 질문에서 오히려 Agentic Collapse가 빈번하게 발생하여 도구 접근 권한이 성능 향상으로 직결되지 않는다는 역설적인 현상을 관찰했습니다. 인용 오류 검증 결과, 존재 여부(L1)만 확인할 경우 0.7%의 낮은 오류율을 보이나, 내용 뒷받침 여부(L2)를 검증하면 15.9%에 달하는 인용 신뢰성 결함이 드러나, 단순히 인용 문헌의 존재 확인만으로는 모델의 전문성을 신뢰할 수 없음이 밝혀졌습니다 [Figure 5].
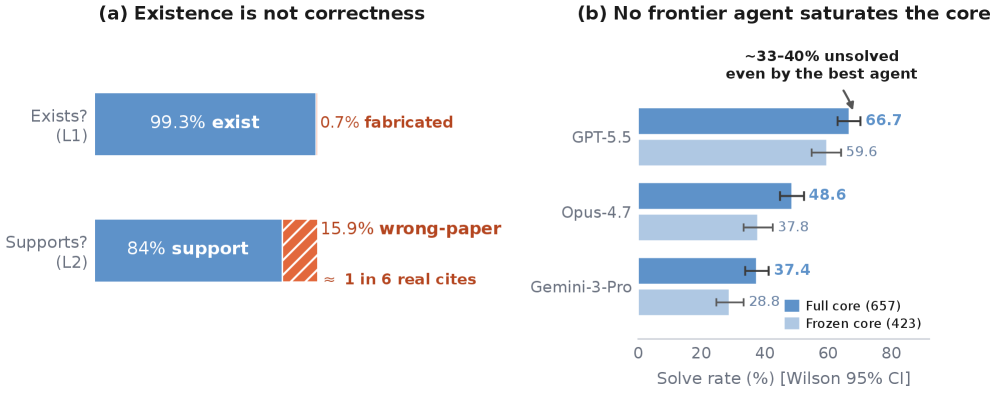
Figure 4 — 인용 신뢰성 및 모델 성과 지표
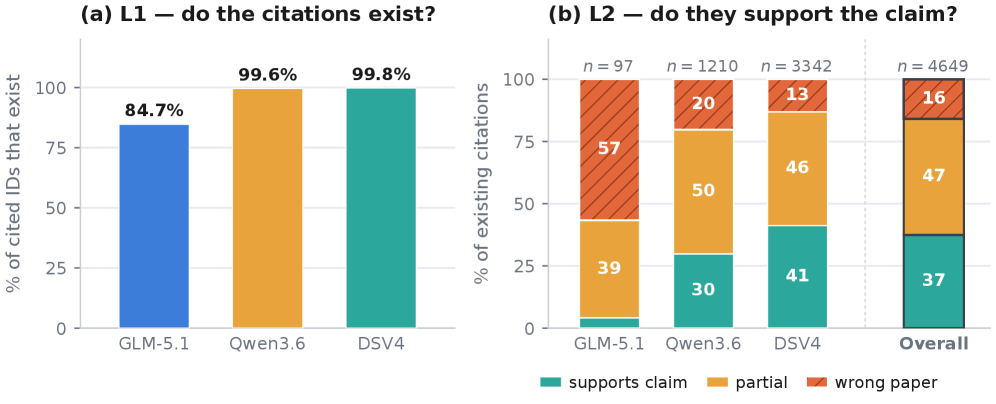
Figure 5 — 모델별 인용 신뢰성 상세 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 미해결 생의학 질문을 활용하여 기존 평가 방식의 한계를 극복하고, 모델의 실제 인용 신뢰성과 에이전트 행동을 객관적으로 측정하는 새로운 기준을 제시합니다. 연구 결과는 인용의 존재 여부(Existence)가 내용적 정당성(Correctness)을 보장하지 않는다는 사실을 명확히 함으로써, 향후 LLM의 문헌 기반 추론(Evidence Retrieval) 분야에 중요한 방법론적 교훈을 제공합니다. 특히 Agentic Collapse에 대한 관찰은 향후 에이전트 아키텍처 개선에 있어 도구 사용 최적화의 중요성을 학계와 산업계에 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models
- [논문리뷰] Hardening Agent Benchmarks with Adversarial Hacker-Fixer Loops
- [논문리뷰] Cosine Misleads: Auxiliary Losses Reshape Vision Language Models, Not Their Latents
- [논문리뷰] OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
- [논문리뷰] Measuring the Depth of LLM Unlearning via Activation Patching
Review 의 다른글
- 이전글 [논문리뷰] OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
- 현재글 : [논문리뷰] OpenBioRQ: Unsolved Biomedical Research Questions for Agents
- 다음글 [논문리뷰] PhysiFormer: Learning to Simulate Mechanics in World Space
댓글