[논문리뷰] The State-Prediction Separation Hypothesis
링크: 논문 PDF로 바로 열기
메타데이터
저자: Giovanni Monea, Nathan Godey, Kianté Brantley, Yoav Artzi
1. Key Terms & Definitions (핵심 용어 및 정의)
- State-Prediction Separation (SPS): 언어 모델 내에서 다음 토큰을 예측하는 기능(Prediction)과 이후 시점의 토큰 예측을 위해 정보를 저장하는 기능(State Preparation)을 서로 다른 연산 스트림으로 분리하는 설계 개념입니다.
- Persistent State: 입력 토큰($x_i$) 스트림을 통해 유지되는 정보로, 후속 시점의 쿼리가 참조할 수 있도록 KV Cache에 장기적으로 저장되는 상태입니다.
- Prediction Stream:
토큰($\rho_i$)을 사용하여 다음 토큰 예측을 수행하는 별도의 연산 경로입니다. - Sliding Window: 메모리 효율성을 위해 제한된 크기($w$)의 최근
토큰들만을 참조하도록 설계된 Attention 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 표준 Transformer가 단일 연산 스트림 내에서 다음 토큰 예측과 상태 저장을 동시에 수행함으로써 발생하는 "Present-Future Tension" 문제를 해결하고자 합니다. 기존 모델은 단일 hidden state가 두 가지 역할을 동시에 수행하도록 강제되는데, 이는 최적화 과정에서 서로 경쟁하게 만들어 모델의 효율성을 저해합니다 [Figure 1]. 저자들은 이러한 두 역할을 구조적으로 분리하는 것이 언어 모델링 성능을 향상시킬 것이라는 가설을 제안하며, 이를 검증하기 위해 두 스트림을 독립적으로 처리하는 SPS Transformer 아키텍처를 설계하였습니다.
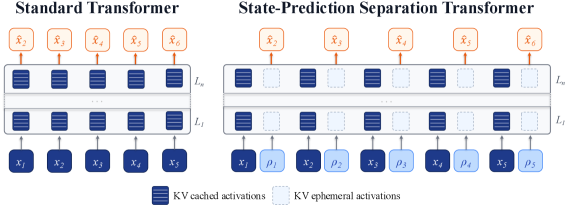
Figure 1 — 표준 Transformer와 SPS Transformer 구조 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 각 입력 토큰 뒤에 학습 가능한 <predict> 토큰을 인터리빙하여, 상태 정보와 예측 정보를 별도의 스트림으로 분리하였습니다 [Figure 1]. 학습 시, 입력 토큰은 Persistent KV Cache를 통해 상태 정보를 장기 보존하고, <predict> 토큰은 Sliding Window 내에서 다음 토큰 예측을 위한 단기적인 예측 연산을 수행하도록 설계하였습니다. 주요 실험 결과는 다음과 같습니다.
- Data & Compute Efficiency: SPS는 표준 Transformer 대비 동일한 성능에 도달하는 데 필요한 토큰 수를 약 50% 절감하였으며, matched parameter count 환경에서 일관되게 더 낮은 validation NLL을 달성하였습니다 [Table 2].
- Downstream Task Performance: 제안 모델은 5개 벤치마크 평균 zero-shot 정확도에서 표준 모델 대비 2.3% ~ 3.1% 포인트 우수한 성능을 보였습니다 [Table 2].
- Robustness: 성능 향상은 단순히 추가 연산에 의한 것이 아니라, 두 역할의 구조적 분리에 기인함을 2x Memory 및 Delayed State ablation 연구를 통해 입증하였습니다 [Table 2].
- Gradient Analysis: 연구팀은 SPS가 실제로 prediction loss와 state-preparation loss에 해당하는 그래디언트를 각각의 스트림으로 효과적으로 분배하고 있음을 분석하였습니다 [Figure 5].
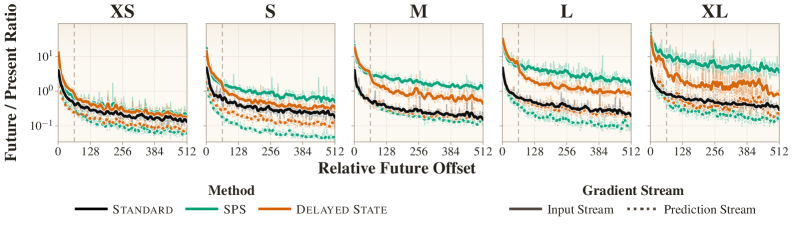
Figure 5 — 그래디언트 분리 및 상태 활용 분석
4. Conclusion & Impact (결론 및 시사점)
본 논문은 언어 모델의 연산 성능이 모델의 Capacity뿐만 아니라, 예측과 상태 정보 전달이라는 두 핵심 기능의 분리 수준에 의해 결정된다는 State-Prediction Separation Hypothesis를 성공적으로 입증하였습니다. 이 연구는 고품질 데이터의 한계가 명확해지는 시대에, 더 적은 데이터로 더 높은 학습 효율을 달성할 수 있는 구조적 대안을 제시합니다. 향후 대규모 언어 모델 아키텍처 설계 시 연산 경로 최적화를 위한 중요한 이론적 기반이 될 것으로 기대됩니다.
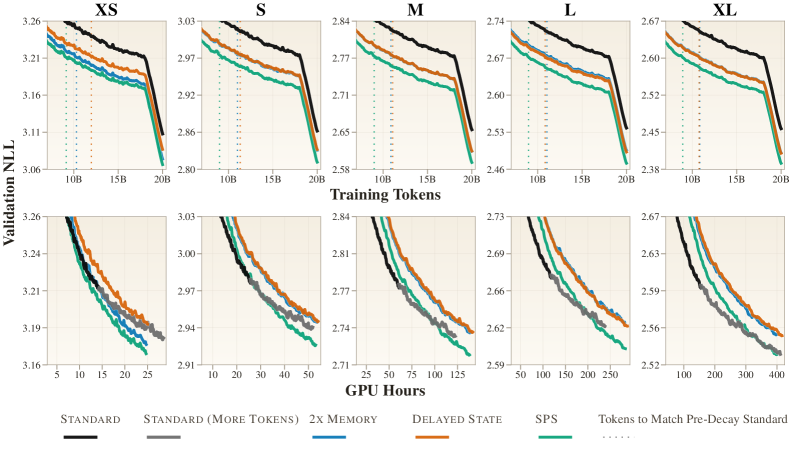
Figure 2 — 스케일별 validation NLL 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ESPO: Early-Stopping Proximal Policy Optimization
- [논문리뷰] Learn-by-Wire Training Control Governance: Bounded Autonomous Training Under Stress for Stability and Efficiency
- [논문리뷰] Efficient Exploration at Scale
- [논문리뷰] In-Context Reinforcement Learning for Tool Use in Large Language Models
- [논문리뷰] Post-LayerNorm Is Back: Stable, ExpressivE, and Deep
Review 의 다른글
- 이전글 [논문리뷰] Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity
- 현재글 : [논문리뷰] The State-Prediction Separation Hypothesis
- 다음글 [논문리뷰] TurboServe: Serving Streaming Video Generation Efficiently and Economically
댓글