[논문리뷰] HybridStitch: Pixel and Timestep Level Model Stitching for Diffusion Acceleration
링크: 논문 PDF로 바로 열기
저자: Desen Sun, Jason Hon, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- HybridStitch : 텍스트-투-이미지(T2I) Diffusion 모델의 추론(inference) 속도를 가속화하기 위해 Pixel 및 Timestep 수준에서 대규모(large) 모델과 소규모(small) 모델을 결합하는 새로운 모델 스티칭(stitching) 패러다임입니다.
- Mixture of Models (MoM) : Diffusion 모델 추론 시 여러 모델(일반적으로 크기가 다른 모델)을 사용하여 계산 효율성을 높이는 방법론을 의미합니다. 초기 또는 후기 denoising 단계에서 모델을 전환하여 compute를 절감합니다.
- Timestep : Diffusion 모델의 denoising 프로세스에서 노이즈를 제거하는 반복적인 단계 중 하나를 지칭합니다. 각 Timestep마다 이미지에 대한 노이즈 예측 및 업데이트가 이루어집니다.
- Masked Generation : HybridStitch 방법론의 핵심으로, 이미지의 일부(mask된 영역)만 대규모 모델로 처리하고 나머지 영역은 소규모 모델로 처리하여 계산량을 줄이는 기법입니다. 이때 대규모 모델은 KV Cache 를 활용하여 전체 Context 를 보존합니다.
- L1 Distance (D_t) : 두 인접한 Timestep 간 latent state의 차이를 측정하는 지표로,
HybridStitch에서 다음 단계로 전환할지 여부를 결정하는 데 사용되는 적응형 스위칭(adaptive switching) 함수의 핵심입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Text-to-Image (T2I) Diffusion 모델은 인상적인 이미지 생성 능력을 보여주지만, 수십억 개의 파라미터를 포함하는 대규모 모델의 경우 극심한 계산 오버헤드와 높은 Latency로 인해 latency-sensitive한 애플리케이션에 적용하기 어렵다는 문제에 직면해 있습니다. 기존 연구들은 denoising Step의 일부를 더 작은 모델로 대체하여 계산량을 줄이려 했으나, 이러한 방법들은 전체 이미지 Granularity에서 모델을 전환하며, 단일 Timestep 내에서 Pixel마다 달라지는 compute demand를 무시합니다. 이는 쉬운 영역(예: 배경)과 복잡한 영역(예: 객체)을 동일하게 처리하여, 쉬운 영역이 준비될 때 전환하면 품질 저하가 발생하거나, 모든 Pixel이 충분히 정제될 때까지 전환을 지연하면 Latency가 증가하는 비효율성을 야기합니다. [Figure 1 (b)]는 대규모 모델과 소규모 모델의 예측 차이가 객체 부분에서 두드러진다는 것을 보여주며, 이는 Pixel 수준의 차이가 존재함을 명확히 합니다. 이러한 한계점은 Pixel 간 차이를 인지하는 보다 유연한 스위칭 정책의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Pixel 및 Timestep 수준에서 모델 스티칭을 수행하는 Region-aware 패러다임인 HybridStitch 를 제안합니다. [Figure 1 (c)]에 제시된 HybridStitch 는 T2I 생성을 마치 편집처럼 취급합니다. 초기 denoising 단계에서는 대규모 모델을 사용하여 Gaussian noise를 처리하고 이미지의 전반적인 레이아웃을 구성합니다. 이후 하이브리드 단계에서 HybridStitch 는 렌더링이 어려운 Pixel(Mask 영역)을 추출하여 대규모 모델로 정제하는 동시에, 소규모 모델은 전체 Latent State를 처리하여 전반적인 일관성을 유지합니다. 이때 대규모 모델은 이전 Timestep의 KV cache 를 활용하여 Masked Generation 시 Context 를 보존하며, 마스크는 각 denoising Step마다 업데이트되어(가장 큰 차이를 보이는 Top-K 값을 선택) 품질을 향상합니다. [Figure 3 (a)]는 세 가지 단계(First Stage, Second Stage, Third Stage)로 구성된 전체 추론 프로세스를 보여주며, L1 Distance (D_t) 를 활용한 적응형 스위칭 전략으로 다음 단계로의 전환 시점을 결정합니다.
실험 결과 `
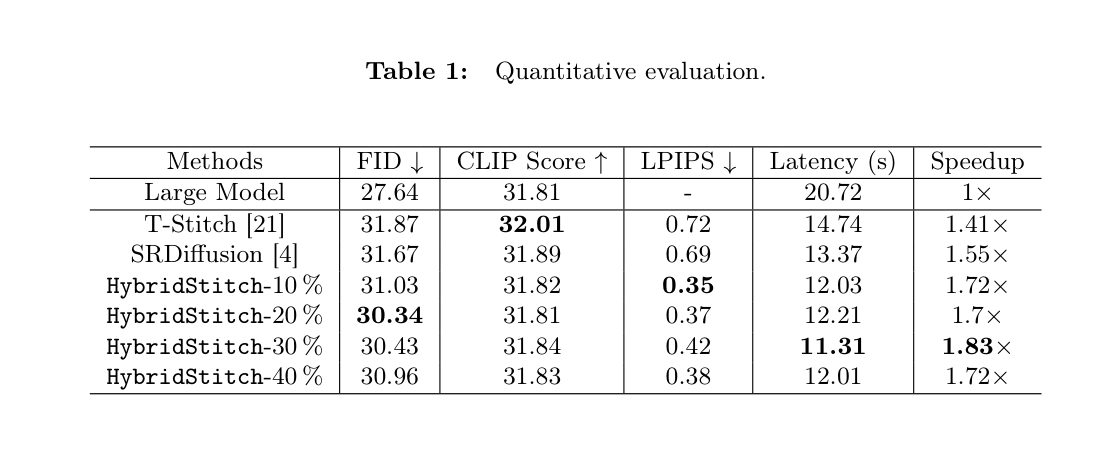 Table 1: Quantitative evaluation comparing HybridStitch with baselines across various metrics.
Table 1: Quantitative evaluation comparing HybridStitch with baselines across various metrics.
, **HybridStitch** 는 **Stable Diffusion 3.5 Large** 모델과 **Stable Diffusion 3 Medium** 모델을 사용하여 **RTX6000 Ada GPU** 환경에서 기존 **T-Stitch** 및 **SRDiffusion** 대비 모든 품질 Metric에서 우수한 성능을 보였습니다. 특히, **HybridStitch** 는 **SRDiffusion** 대비 최대 **18.06%** 의 Latency를 감소시키며, **30% Mask** 설정에서 **1.83x Speedup** 을 달성했습니다. 또한, **HybridStitch** 는 **T-Stitch** 및 **SRDiffusion** 대비 **FID** 를 최대 **5%** 및 **4.4%** 감소시켜 더 나은 시각적 품질을 제공했습니다. [Figure 4]`의 시각적 비교에서도 HybridStitch-30% 가 시각적 품질 저하 없이 가장 높은 Speedup 을 보였습니다. 다양한 GPU (H100 SXM, A100 SXM)에서도 HybridStitch 는 최소 1.5x Speedup 을 달성하며, 특히 저성능 플랫폼에서 더 큰 이점을 제공함을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 T2I Diffusion 모델의 가속화를 위한 Pixel 및 Timestep 수준의 모델 스티칭 기법인 HybridStitch 를 성공적으로 제안했습니다. 대규모 및 소규모 모델 간의 출력 불일치가 이미지 영역별로 상당한 다양성을 보인다는 중요한 관찰을 기반으로, HybridStitch 는 Masked Generation과 Mixture of Models 패러다임을 통합하여 이러한 지역적 차이를 명시적으로 설명합니다. 특히, 이전 denoising 단계의 KV Cache 를 활용하여 Masked Computation 중 누락된 Context 를 보완함으로써 생성 품질을 보존합니다. HybridStitch 는 최첨단 Mixture of Models 가속화 접근 방식 대비 최대 18.06% 의 Latency 감소를 달성하면서도 비교 가능한 이미지 품질을 유지하여, Diffusion 모델의 실시간 애플리케이션 통합에 중요한 진전을 가져왔습니다. 이는 고품질 이미지 생성의 Latency 장벽을 낮추는 데 기여하며, 특히 자원 제약이 있는 환경에서의 Diffusion 모델 배포 가능성을 높이는 데 큰 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DiffusionBench: On Holistic Evaluation of Diffusion Transformers
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] Text-to-Image Models Need Less from Text Encoders Than You Think
- [논문리뷰] PaintBench: Deterministic Evaluation of Precise Visual Editing
- [논문리뷰] PixVerve: Advancing Native UHR Image Generation to 100MP with a Large-Scale High-Quality Dataset
Review 의 다른글
- 이전글 [논문리뷰] HomeSafe-Bench: Evaluating Vision-Language Models on Unsafe Action Detection for Embodied Agents in Household Scenarios
- 현재글 : [논문리뷰] HybridStitch: Pixel and Timestep Level Model Stitching for Diffusion Acceleration
- 다음글 [논문리뷰] LMEB: Long-horizon Memory Embedding Benchmark
댓글