[논문리뷰] Steve-Evolving: Open-World Embodied Self-Evolution via Fine-Grained Diagnosis and Dual-Track Knowledge Distillation
링크: 논문 PDF로 바로 열기
저자: Zhengwei Xie, Zhisheng Chen, Ziyan Weng, Tingyu Wu, Chenglong Li, Vireo Zhang, Kun Wang
키워: Embodied Agent, Self-Evolution, Fine-Grained Diagnosis, Knowledge Distillation, Minecraft, Long-Horizon Tasks, LLM Planner
1. Key Terms & Definitions (핵심 용어 및 정의)
- Steve-Evolving : 오픈 월드 Embodied Agent를 위한 비모수적(non-parametric) 자가 진화(self-evolving) 프레임워크로, fine-grained execution diagnosis와 dual-track knowledge distillation을 긴밀하게 결합하여 경험을 체계화하고 진화시키는 것을 목표로 합니다.
- Experience Anchoring : Subgoal 시도를 고정된 스키마(pre-state, action, diagnosis-result, post-state)를 갖는 Structured Experience Document로 기록하고, 다차원 인덱싱(condition signatures, spatial hashing, semantic tags)과 롤링 요약(rolling summarization)을 통해 효율적인 검색을 가능하게 하는 단계입니다.
- Fine-Grained Execution Diagnosis : 단순 이진 결과(성공/실패)를 넘어, State-Difference 요약, 실패 원인(enumerated failure causes), 연속 지표(continuous indicators), 정체/루프 감지(stagnation/loop detection) 등 상세하고 구조화된 진단 신호를 제공하여 실패의 정확한 Attribution을 가능하게 합니다.
- Dual-Track Knowledge Distillation : 성공적인 궤적을 재사용 가능한 Skills 로 일반화하고, 실패를 실행 가능한 Guardrails (근본 원인 및 위험한 작업 금지)로 Distill하는 두 가지 경로의 지식 추출 메커니즘입니다.
- Knowledge-Driven Closed-Loop Control : 검색된 Skills 및 Guardrails를 LLM Planner에 주입하여 계획을 안내하고, Diagnosis-Triggered Local Replanning을 통해 Active Constraint를 온라인으로 업데이트하여 Continuous Evolution Process를 형성하는 단계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 오픈 월드 환경에서 Embodied Agent가 Long-Horizon Compound Task를 자율적으로 수행하는 데 있어 Single-Step Planning Quality보다는 상호작용 경험을 어떻게 체계화하고 진화시키는지가 핵심 병목(bottleneck)임을 지적합니다. 최신 LLM 및 Multimodal 모델은 Instruction Understanding과 Logical Reasoning에서 진전을 보였지만, Minecraft와 같은 Sandbox 환경에서 여러 상호의존적 Subgoal을 순차적으로 완료해야 하는 복잡한 시나리오에서는 인간 플레이어 대비 상당한 성능 격차가 존재합니다.
기존 연구(Baseline)들은 대부분 경험 관리 전략에 대한 다양한 탐색을 시도했으나, 몇 가지 한계를 보입니다. JARVIS-1 은 성공적인 궤적을 원본 형태로 저장하고 실패 경험을 버리며, Optimus-1 은 성공 및 실패 사례를 참조 예시로 사용하지만, 실행 계층의 Diagnostic Signal을 활용하여 실패 원인을 Actionable Constraint로 Attribution하지 못합니다. Reflexion 이나 ExpeL , Voyager 와 같은 Self-Evolution 방법론은 언어 기반의 Self-Reflection을 통해 실패로부터 교훈을 얻지만, Embodied 환경의 복잡한 실패 모드(Spatial Navigation, Physical Interaction, GUI Operation, Resource Status 등 다차원 요인과 얽힌)를 정확하게 Attribution하기 위한 Fine-Grained Structured Diagnostic Signal이 부족합니다. 결과적으로 이들은 "마지막 시도가 실패했다"고 알릴 수는 있지만, "어떤 Embodied State Anomaly가 실패를 유발했고, 어떤 Computable Execution Constraint를 부과하여 실수를 반복하지 않아야 하는지"를 정확히 식별하는 데 어려움을 겪습니다. 이러한 기존 연구의 한계점은 Embodied Agent의 지속적인 Capability 성장 및 경험 진화의 상한선을 제약하며,
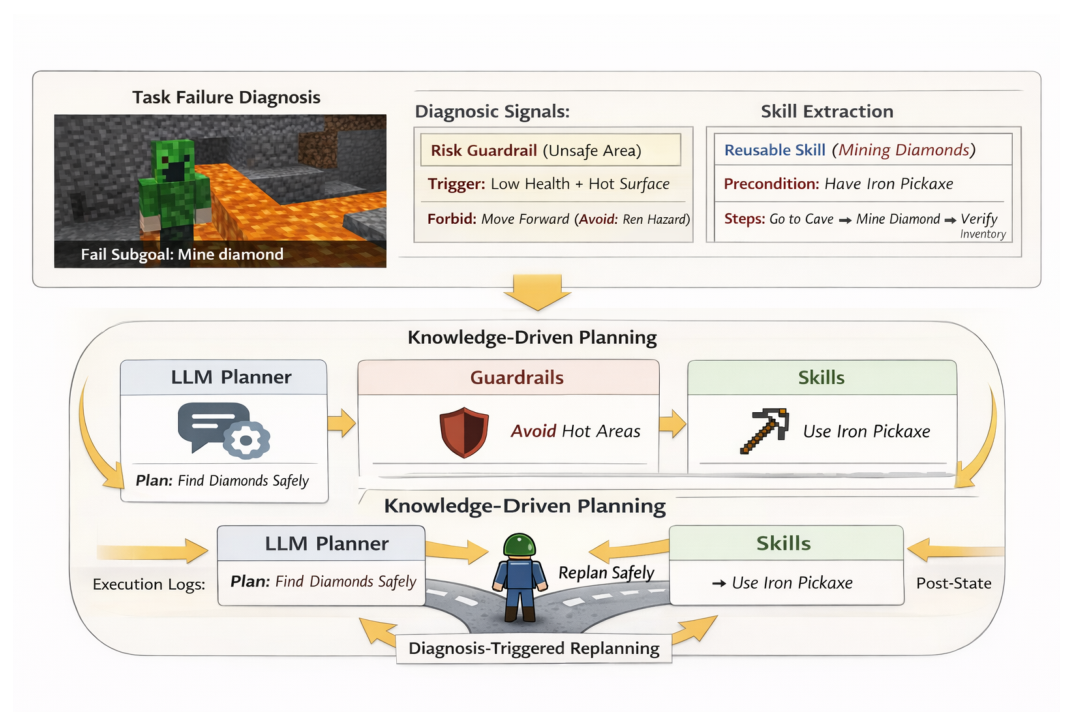 Figure 1: Diagnosis-triggered knowledge-driven planning (horizontal layout).
Figure 1: Diagnosis-triggered knowledge-driven planning (horizontal layout).
에서 제시된 Diagnosis-Triggered Knowledge-Driven Planning의 필요성을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 위 문제점을 해결하기 위해 Fine-Grained Embodied Diagnostic Signal과 Structured Knowledge Distillation을 긴밀하게 결합한 계층적 Experience Evolution Paradigm인 Steve-Evolving 을 제안합니다. 이 방법론은 크게 세 가지 Phase로 진행됩니다. 첫째, Experience Anchoring 은 각 Subgoal 시도를 Pre-state, Action, Diagnosis-Result, Post-state를 포함하는 고정된 스키마의 Structured Experience Tuple로 고착시키고, Condition Signatures, Spatial Hashing, Semantic Tags 등 Multi-Dimensional Index와 Rolling Summarization을 통해 Efficient Recall을 가능하게 합니다. 특히 실행 계층은 단순히 성공/실패 여부를 넘어 State-Difference Summary, 11가지 Enumerated Failure Causes, Continuous Indicators, Stagnation/Loop Detection 등 Fine-Grained Compositional Diagnosis Signals 를 제공하여 정보 밀도를 높입니다. 둘째, Dual-Track Experience Distillation 은 성공적인 궤적을 명시적인 Precondition과 Verification Criteria를 갖춘 Reusable Skill로 일반화하고, 실패를 근본 원인과 위험한 작업을 금지하는 실행 가능한 Guardrails로 Distill합니다. 셋째, Knowledge-Driven Closed-Loop Control 은 검색된 Skills와 Guardrails를 LLM Planner에 주입하여 의사결정을 안내하고, 진단이 트리거될 때 Active Constraint를 Online으로 업데이트하여 Local Replanning을 수행합니다. 이 과정은 모델 파라미터 업데이트 없이 지속적인 Evolution을 가능하게 합니다.
이 방법론의 효과는 Minecraft MCU Long-Horizon Task Benchmarks에서 검증되었습니다. 실험 결과, Steve-Evolving 은 모든 LLM Backbone(Qwen3.5-flash, Qwen3.5-plus, GLM-4.7, Gemini-3-flash, Gemini-3-pro)에서 Static-Retrieval Baseline 대비 Consistent Improvements 를 보였습니다. 예를 들어, Gemini-3-pro Backbone에서 Steve-Evolving 은 전체 Task Success Rate에서 53.37% 를 달성하며, Jarvis-1의 42.67% 와 Optimus-1의 47.63% 를 크게 상회했습니다. 특히 Task Horizon Length와 Compositional Dependencies가 높은 Iron, Redstone, Diamond, Armor와 같은 Later-Stage Task Group에서 Steve-Evolving 의 이점이 가장 두드러졌습니다.
Ablation Studies
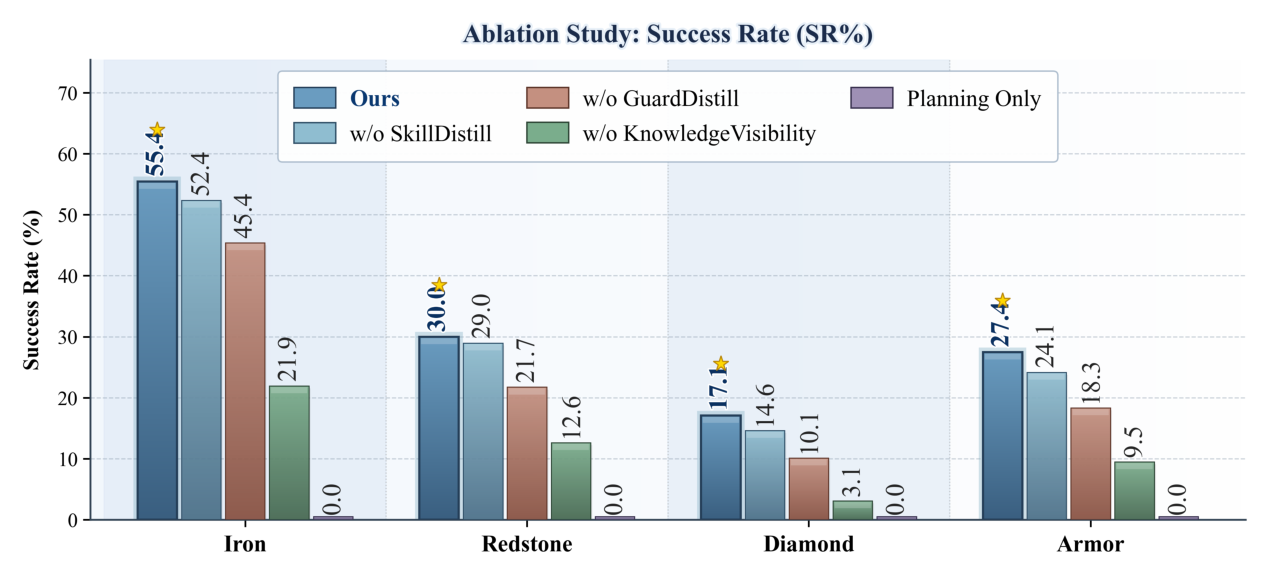 Figure 4: visualization of Ablation results.
Figure 4: visualization of Ablation results.
는 제안된 Closed-Loop Framework의 각 구성 요소가 필수적임을 입증합니다. KnowledgeVisibility (명시적 지식 주입) 제거 시 가장 큰 성능 저하가 발생했으며 (Iron/Redstone/Diamond/Armor Task에서 각각 21.9/12.6/3.1/9.5% SR), GuardDistill 제거 시에도 SR이 크게 감소했습니다 ( 45.4/21.7/10.1/18.3% ). SkillDistill 제거 시에는 상대적으로 적은 감소를 보였으나 지속적인 성능 저하가 관찰되었습니다 ( 52.4/29.0/14.6/24.1% ). Planning Only (Closed-Loop Mechanism 및 Knowledge-Conditioned Control 없이 Planner만 사용) 변형은 모든 Group에서 0.0% SR 을 기록하여, Planning 단독으로는 Long-Horizon Task에 불충분하며 Closed-Loop Knowledge Grounding 및 Recovery의 중요성을 시사합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 오픈 월드 Embodied Agent를 위한 비모수적 자가 진화 프레임워크인 Steve-Evolving 을 제안합니다. 이 프레임워크는 경험을 단순히 축적하는 것을 넘어, Fine-Grained Execution Diagnosis를 통해 상호작용 이력을 Structured Assets로 조직화하고, Dual-Track Knowledge Distillation을 통해 재사용 가능한 Skills와 Guardrails로 정제하며, Knowledge-Driven Closed-Loop Control을 통해 LLM Planner에 이를 주입하여 동적으로 Replanning하는 Life Cycle을 강조합니다.
이 연구는 Minecraft MCU Long-Horizon Benchmark 실험을 통해 계층적 경험 진화가 Static Retrieval Baseline 대비 일관된 성능 향상을 가져오고, 경험 축적에 따라 지속적인 Capability 성장을 지원함을 실증했습니다. 이는 Embodied Agent가 복잡한 환경에서 Self-Evolution하는 새로운 기술적 경로를 제시하며, 미래 AI 시스템이 복잡한 개방형 환경에서 인간과 유사한 방식으로 지속적으로 학습하고 적응하는 능력을 갖추는 데 중요한 시사점을 제공합니다. 궁극적으로 이 연구는 경험 관리 패러다임을 Static Retrieval Corpus에서 Structured Assets with a Life Cycle로 재정의하여, AI 분야의 Long-Horizon Embodied Task 해결 능력 향상에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Spend Less, Reason Better: Budget-Aware Value Tree Search for LLM Agents
- 현재글 : [논문리뷰] Steve-Evolving: Open-World Embodied Self-Evolution via Fine-Grained Diagnosis and Dual-Track Knowledge Distillation
- 다음글 [논문리뷰] Think While Watching: Online Streaming Segment-Level Memory for Multi-Turn Video Reasoning in Multimodal Large Language Models
댓글