[논문리뷰] WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
링크: 논문 PDF로 바로 열기
저자: Jisu Nam, Yicong Hong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video Diffusion Transformers (DiTs) : 공간-시간적 Self-Attention 및 Text Cross-Attention Layer로 구성되어 영상 생성에 사용되는 SOTA Diffusion Transformer 모델.
- Camera Pose : 카메라의 3D 위치(Translation)와 방향(Rotation)을 나타내는 6-DoF 기하학적 정보로, Lie algebra se(3) 를 통해 상대적인 카메라 모션을 정확하게 표현한다.
- Lie Algebra se(3) : 강체(Rigid Body)의 움직임을 표현하는 수학적 공간으로, Translation과 Rotation이 분리되지 않고 결합된(Coupled) 방식으로 처리되어 실제 물리적 움직임에 더 가깝게 모델링할 수 있다.
- Plücker Embeddings : 카메라 Pose를 Video DiT에 주입하기 위한 Compact한 Geometric Conditioning Signal 인코딩 방식.
- Progressive Autoregressive Inference : 장기적(Long-Horizon) 비디오 생성 시 Time-Step이 지남에 따라 점진적으로 증가하는 Noise Level을 적용하여 초기 프레임의 Stability를 확보하고 이후 프레임의 오류를 수정 가능하게 하는 기법.
- Attention Sink : Long-Horizon 생성 과정에서 Attention이 Distorted UI Elements나 시각적 포화(Visual Saturation)로 인해 Error Drift가 발생하는 것을 방지하기 위해 초기 토큰(Token)들을 고정된 Anchor로 활용하는 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Video Diffusion Transformers (DiTs)의 발전으로 Interactive Gaming World Models은 생성된 환경을 Long-Horizon으로 탐색하는 능력을 보여주었지만, 여전히 정밀한 Action Control 및 3D Consistency 확보에 어려움을 겪고 있습니다. 기존 연구들은 사용자 Action을 추상적인 Conditioning Signal로 처리하여 Action과 3D World 간의 근본적인 기하학적 결합(Geometric Coupling)을 간과했습니다. 이로 인해 카메라 Motion이 잘못 정렬되거나 3D Geometry 가 일관성 없이 생성되는 문제가 발생했으며, 단기 비디오(예: 16프레임 )에 집중하여 Action-Driven Control 및 Long-Horizon 추론을 모델링하는 데 실패했습니다. 따라서, 즉각적인 Action Control과 장기적인 3D Consistency 를 동시에 Grounding할 수 있는 통합된 기하학적 표현(Unifying Geometric Representation)의 필요성이 대두되었습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
WorldCam은 Camera Pose 를 즉각적인 Action Control과 Long-Horizon 3D Consistency 를 동시에 Grounding하는 통합된 기하학적 표현으로 제시합니다
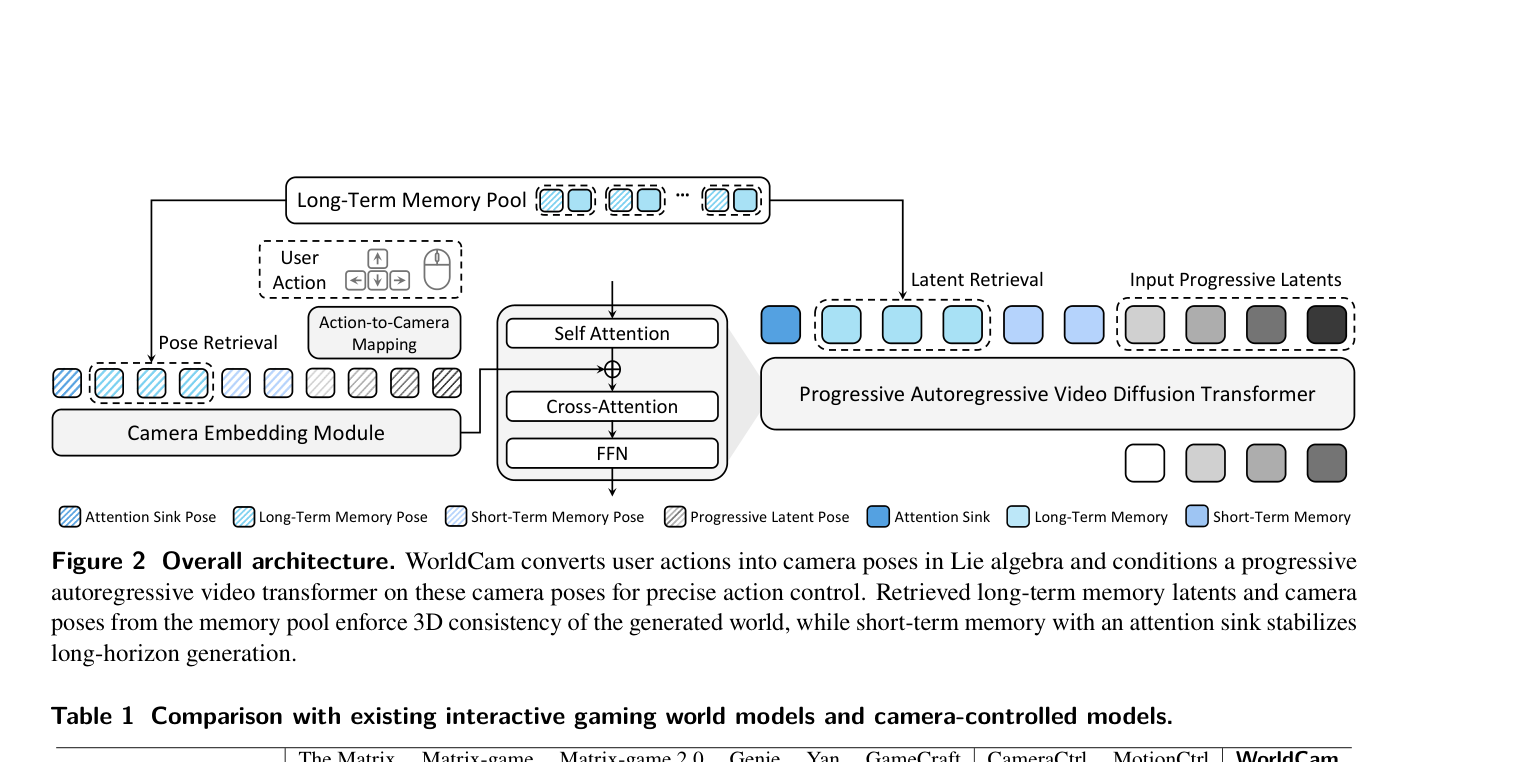 Figure 2: Overall architecture.
Figure 2: Overall architecture.
. 첫째, 사용자 Input(키보드, 마우스)을 Lie algebra se(3) 의 공간 속도(Spatial Velocities)로 정의하여 정확한 6-DoF 카메라 Pose를 유도하고, 이를 Plücker Embeddings 로 인코딩한 뒤 Video DiT 에 주입하여 정확한 Action Alignment를 보장합니다. 둘째, Global Camera Pose를 공간적 Index로 활용하여 관련 과거 관측치(Latents)를 Long-Term Memory Pool 에서 검색함으로써 Long-Horizon Navigation 시 3D Geometry 가 일관되게 유지되도록 합니다. 또한, Progressive Noise Scheduling 과 Attention Sink 메커니즘을 결합하여 장기적인 Visual Quality를 안정화합니다.
WorldCam은 WorldCam-50h 라는 3,000분 규모의 대규모 오픈 라이선스 게임 플레이 데이터셋을 구축하여 학습 및 평가에 활용했습니다. 정량적 실험 결과, WorldCam은 기존 Interactive Gaming World Models 대비 뛰어난 성능을 보였습니다.
- Action Controllability : 200프레임 생성에서 RPEcamera 0.086 을 달성하여 GameCraft( 0.100 ) 대비 16.3% 향상되었고, 16프레임 생성에서는 RPEcamera 0.030 으로 CameraCtrl( 0.083 ) 대비 36.1% 향상되었습니다 [Table 2, Table 4]. 특히, Lie algebra-based approximation 은 선형 근사 방식 대비 ATEfinal을 91.149 에서 0.015 로 크게 줄였습니다 [Table 11].
- Visual Quality : VBench Average Score 0.844 를 기록하여 GameCraft( 0.781 ) 대비 8.1% 높은 성능을 보였으며
 Table 2: Quantitative comparison with recent interactive gaming world models in terms of action controllability and visual quality. All methods are evaluated under the same action trajectories with 200-frame video generation.
Table 2: Quantitative comparison with recent interactive gaming world models in terms of action controllability and visual quality. All methods are evaluated under the same action trajectories with 200-frame video generation.
, Real Videos ( 577 )와 유사한 Sharpness Score ( 656 )를 유지했습니다
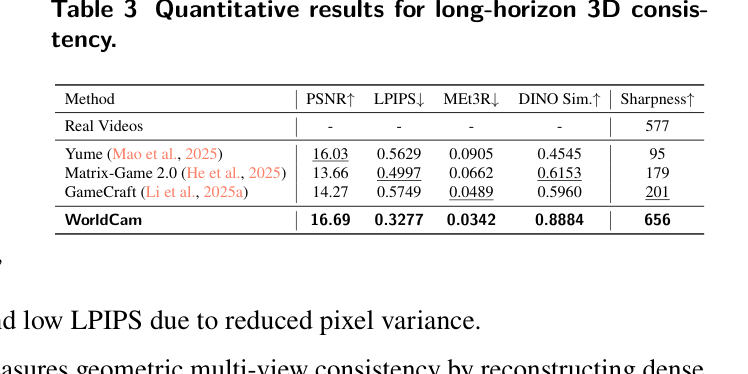 Table 3: Quantitative results for long-horizon 3D consistency.
Table 3: Quantitative results for long-horizon 3D consistency.
.
- 3D Consistency : PSNR 16.69 , LPIPS 0.3277 , MEt3R 0.0342 , DINO Similarity 0.8884 , Sharpness 656 등 모든 평가 지표에서 SOTA 성능을 달성했습니다 [Table 3]. Human Evaluation에서도 Action Controllability, Visual Quality, 3D Consistency 모두에서 기존 모델 대비 각각 14.0% , 29.8% , 29.8% 의 상대적 개선을 이루었습니다 [Table 5].
4. Conclusion & Impact (결론 및 시사점)
WorldCam은 Camera Pose 를 Unified Geometric Representation으로 성공적으로 확립하여, Interactive Gaming World Models에서 정밀한 Action Control, Long-Horizon Generation 및 일관된 3D World Modeling 을 가능하게 합니다. 본 연구는 물리적으로 일관된 카메라 모션을 통해 사용자 Action을 3D World 와 직접 연결함으로써, 기존 방식의 한계를 극복하고 생성된 환경의 현실감과 인터랙션 품질을 크게 향상시켰습니다.
이 연구는 학계에 3D Consistent 비디오 생성의 새로운 방법론을 제시하며, WorldCam-50h 와 같은 대규모 오픈 소스 데이터셋을 공개하여 Reproducible Research를 촉진합니다. 산업적으로는 더욱 몰입감 있고 기능적인 Generative Gaming Environment 개발의 문을 열었으며, 복잡한 3D 환경에서 사용자 Action에 대한 정밀한 제어와 장기적인 환경 일관성을 확보하는 데 중요한 이정표를 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
- [논문리뷰] InstanceControl: Controllable Complex Image Generation without Instance Labeling
- [논문리뷰] DiffusionBench: On Holistic Evaluation of Diffusion Transformers
- [논문리뷰] PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation
- [논문리뷰] RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
Review 의 다른글
- 이전글 [논문리뷰] WiT: Waypoint Diffusion Transformers via Trajectory Conflict Navigation
- 현재글 : [논문리뷰] WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
- 다음글 [논문리뷰] ACE-LoRA: Graph-Attentive Context Enhancement for Parameter-Efficient Adaptation of Medical Vision-Language Models
댓글