[논문리뷰] ACE-LoRA: Graph-Attentive Context Enhancement for Parameter-Efficient Adaptation of Medical Vision-Language Models
링크: 논문 PDF로 바로 열기
저자: M. Arda Aydın, Melih B. Yilmaz, Aykut Koç, et al.
키워: Vision-Language Models (VLMs), Parameter-Efficient Fine-Tuning (PEFT), Low-Rank Adaptation (LoRA), Hypergraph Neural Networks (HGNN), Medical Imaging, Zero-shot Learning, Contrastive Learning
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLMs (Vision-Language Models) : 이미지와 텍스트 데이터를 함께 학습하여 joint representation을 생성하며, 다양한 컴퓨터 비전 및 NLP Task에 활용되는 모델.
- PEFT (Parameter-Efficient Fine-Tuning) : Pre-trained model의 방대한 parameter 중 일부만을 fine-tuning하여 특정 Task에 모델을 효과적으로 적응시키는 방법론으로, computational cost를 줄이고 overfitting을 방지한다.
- LoRA (Low-Rank Adaptation) : PEFT 기법 중 하나로, pre-trained model의 self-attention layer 내 projection matrices에 low-rank decomposition matrices를 주입하여 parameter efficiency를 높인다.
- ACE-HGNN (Attention-based Context Enhancement Hypergraph Neural Network) : 본 논문에서 제안하는 hypergraph 기반 모듈로, transformer-derived attention affinities를 활용하여 local 및 global embedding 간의 higher-order contextual interaction을 포착하고 fine-grained diagnostic cue를 강화한다.
- InfoNCE Loss (Information Noise-Contrastive Estimation Loss) : Contrastive learning에서 Positive sample 간의 유사도를 높이고 Negative sample 간의 유사도를 낮추는 데 사용되는 Loss function. label-guided InfoNCE loss 는 Medical domain의 False Negative 문제를 완화하기 위해 semantic label 정보를 활용한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
CLIP과 같은 VLMs 는 Natural image 분야에서 탁월한 성능을 보였고, 이는 Medical domain에도 큰 영감을 주었다. 그러나 기존 Medical VLMs 는 Specialist model과 Generalist model이라는 두 가지 극단적 형태로 나뉘어져 있었다. Specialist model은 특정 Domain-specific detail에는 강하지만 generalization 능력이 부족하고, Generalist model은 broad semantics는 유지하지만 fine-grained diagnostic cue를 놓치는 한계가 있었다. 이러한 Specialization-Generalization trade-off를 해소하는 것이 Medical VLMs 의 중요한 과제로 남아있었다.
Generalist Medical VLMs (예: BiomedCLIP )을 특정 Biomedical domain에 적응시키는 것이 필요하지만, large model의 full fine-tuning은 막대한 computational burden을 초래하며, data-scarce Medical setting에서는 overfitting 위험이 높다. 또한, 기존 PEFT 방법론들은 Medical imaging Task에서 두 가지 주요 한계를 가진다. 첫째, 주로 global contextual feature에 집중하여 진단에 중요한 localized pattern, 즉 fine-grained detail을 간과한다. 둘째, 대부분 few-shot setting 및 명시적으로 label된 sample에 의존하여 low-annotation setting에서의 적용과 unseen dataset에 대한 generalization이 어렵다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Generalist Medical VLMs 의 robust zero-shot generalization을 유지하면서 효율적으로 적응시키기 위한 parameter-efficient adaptation framework 인 ACE-LORA 를 제안한다. ACE-LORA 는 BiomedCLIP 을 기반으로 하며, frozen image-text encoder에 LoRA modules를 통합한다. 더 나아가, ACE-HGNN (Attention-based Context Enhancement Hypergraph Neural Network) 모듈을 도입하여 transformer-derived attention affinities로부터 hyperedge를 구성하고 hypergraph message passing을 통해 local 및 global embeddings 간의 higher-order contextual interaction을 포착한다. 이는 fine-grained diagnostic cue를 풍부하게 하여 기존 PEFT 방법론의 한계인 fine-grained detail 간과 문제를 해결한다.
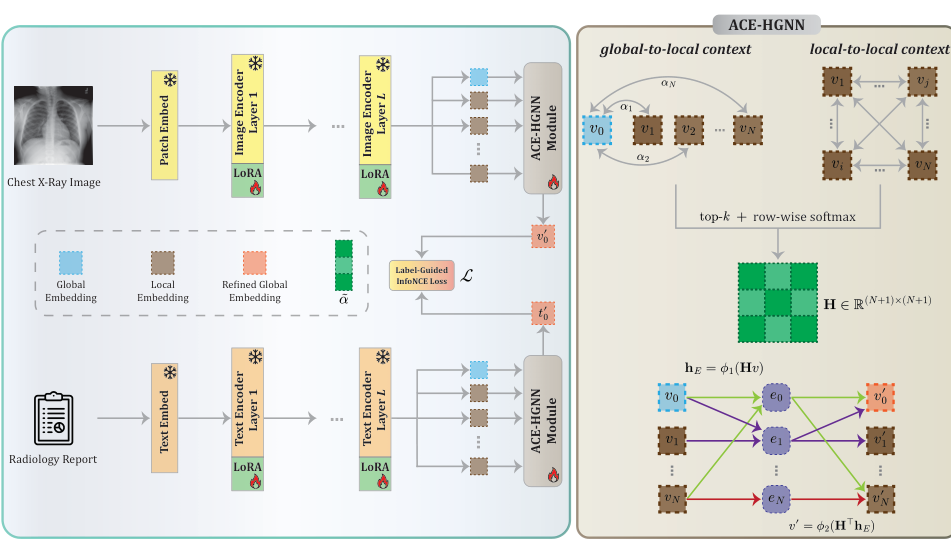 Figure 1: Overview of ACE-LORA. ACE-LORA integrates low-rank adaptation modules into self-attention blocks of image and text encoders in a generalist medical VLM, and introduces ACE-HGNN, a hypergraph-based module that models high-order topological dependencies between local (e.g., image patches or report snippets) and global embeddings. For clarity, ACE-HGNN is described using image embeddings, though the same procedure is applied to text embeddings.
Figure 1: Overview of ACE-LORA. ACE-LORA integrates low-rank adaptation modules into self-attention blocks of image and text encoders in a generalist medical VLM, and introduces ACE-HGNN, a hypergraph-based module that models high-order topological dependencies between local (e.g., image patches or report snippets) and global embeddings. For clarity, ACE-HGNN is described using image embeddings, though the same procedure is applied to text embeddings.
은 ACE-LORA 의 전반적인 아키텍처를 보여준다.
또한, cross-modal alignment를 강화하기 위해 label-guided InfoNCE loss 를 제안하여 Medical contrastive learning에서 흔히 발생하는 False Negative 문제(semantically related 이미지-텍스트 쌍이 서로 다른 Label을 가짐에도 불구하고 Negative로 처리되는 문제)를 효과적으로 완화한다.
ACE-LORA 는 단 0.95M 의 trainable parameter만 추가함에도 불구하고 (이는 full fine-tuning에 필요한 parameter의 약 0.48% 에 해당), Zero-shot classification, segmentation, detection 등 다양한 Medical benchmark에서 SOTA 성능을 달성했다.
- Zero-shot Classification : ACE-LORA 는 CheXpert 5x200 에서 ACC 49.80% , AUC 80.87% 를, RSNA 에서 ACC 79.54% , AUC 87.19% 를, SIIM 에서 ACC 73.35% , AUC 81.51% 를 달성하며 기존 Medical VLMs 및 PEFT baseline을 일관되게 능가했다.
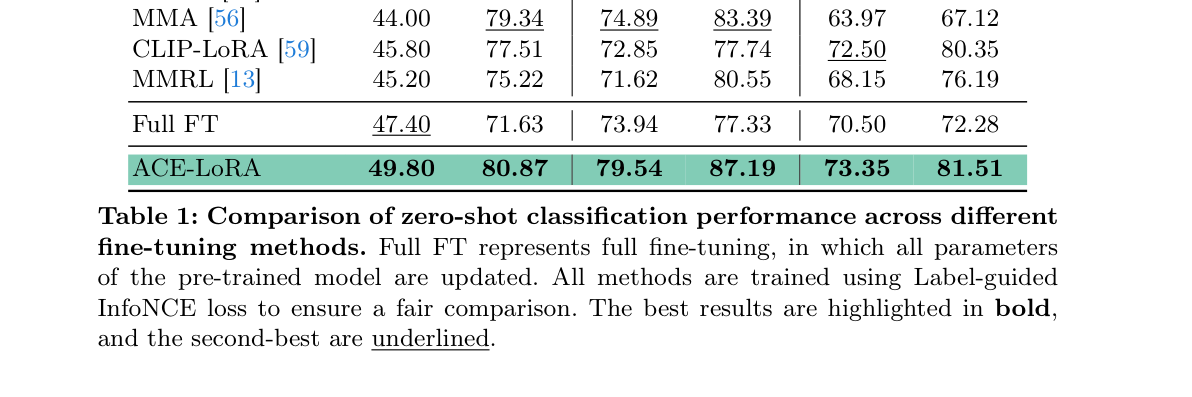 Table 1: Comparison of zero-shot classification performance across different fine-tuning methods. Full FT represents full fine-tuning, in which all parameters of the pre-trained model are updated. All methods are trained using Label-guided InfoNCE loss to ensure a fair comparison. The best results are highlighted in bold, and the second-best are underlined.
Table 1: Comparison of zero-shot classification performance across different fine-tuning methods. Full FT represents full fine-tuning, in which all parameters of the pre-trained model are updated. All methods are trained using Label-guided InfoNCE loss to ensure a fair comparison. The best results are highlighted in bold, and the second-best are underlined.
,
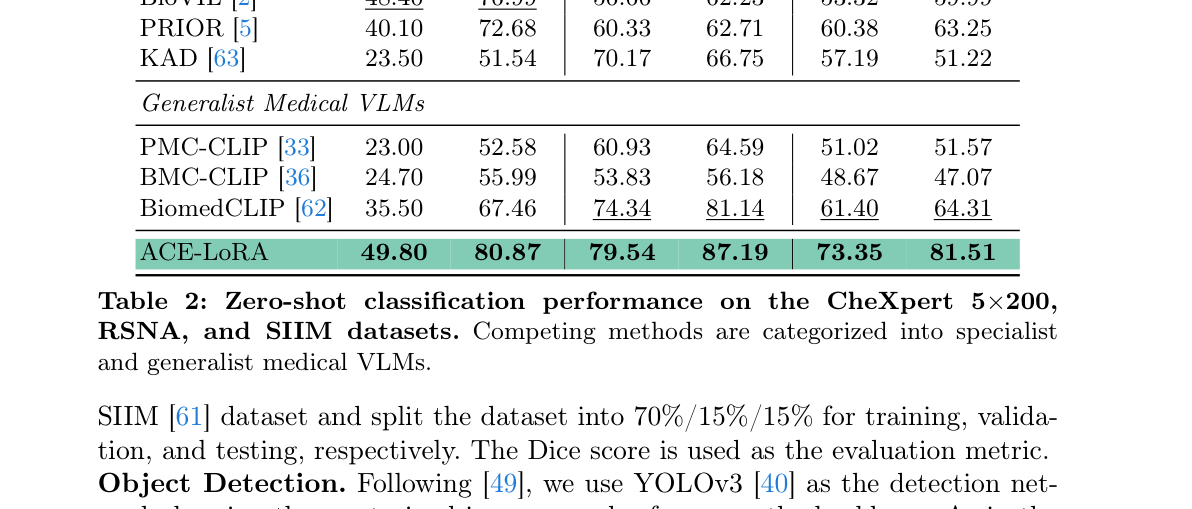 Table 2: Zero-shot classification performance on the CheXpert 5x200, RSNA, and SIIM datasets. Competing methods are categorized into specialist and generalist medical VLMs.
Table 2: Zero-shot classification performance on the CheXpert 5x200, RSNA, and SIIM datasets. Competing methods are categorized into specialist and generalist medical VLMs.
- Segmentation & Detection : SIIM dataset의 Pneumothorax Semantic Segmentation Task에서 Dice score 46.34% 를, RSNA dataset의 Object Detection Task에서 mAP 21.29% 를 기록하며 SOTA Medical VLMs 보다 우수한 성능을 보였다. [Table 4]
- Ablation Studies : ACE-HGNN 모듈의 통합은 LoRA-only baseline 대비 Zero-shot classification 성능을 크게 향상시켰으며, 특히 image encoder와 text encoder 모두에 적용 시 가장 균형 잡힌 결과를 제공함을 확인했다. [Table A.3] 또한, attention maps를 hyperedge weights로 사용하는 것이 GAT, GATv2와 같은 기존 Graph Attention Network 접근 방식보다 우수함을 입증했다. [Table 6]
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Generalist Medical VLMs 를 Data-limited clinical setting에서 robust한 zero-shot transfer를 위해 효율적으로 fine-tuning하는 ACE-LORA framework를 제시한다. ACE-LORA 는 LoRA modules를 통해 parameter efficiency를 확보하고, ACE-HGNN 모듈로 higher-order contextual interaction을 모델링하여 fine-grained diagnostic cue를 강화함으로써 Medical image의 semantic complexity를 효과적으로 포착한다. 또한, label-guided InfoNCE loss 는 contrastive learning의 False Negative 문제를 완화하여 cross-modal alignment를 개선한다.
ACE-LORA 는 기존 Medical VLMs 및 PEFT baseline 대비 Zero-shot classification, segmentation, detection 등 여러 Task에서 일관되게 우수한 성능을 달성했으며, 이는 적은 수의 trainable parameter로도 가능하다는 것을 입증했다. 이러한 결과는 parameter-efficient adaptation 이 Medical imaging 분야에서 foundation model의 활용성을 극대화하고, Data-limited 환경에서도 강력한 성능을 달성할 수 있는 핵심적인 접근 방식임을 시사한다. 이는 학계뿐만 아니라 실제 임상 환경에서의 Medical AI 적용 가능성을 크게 확장할 수 있는 중요한 발걸음이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
- 현재글 : [논문리뷰] ACE-LoRA: Graph-Attentive Context Enhancement for Parameter-Efficient Adaptation of Medical Vision-Language Models
- 다음글 [논문리뷰] AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
댓글