[논문리뷰] BubbleRAG: Evidence-Driven Retrieval-Augmented Generation for Black-Box Knowledge Graphs
링크: 논문 PDF로 바로 열기
저자: Duyi Pan, Tianao Lou, Xin Li, Haoze Song, et al.
키워: Large Language Models, Retrieval-Augmented Generation, Knowledge Graphs, Black-Box KGs, Optimal Informative Subgraph Retrieval, Bubble Expansion
1. Key Terms & Definitions (핵심 용어 및 정의)
- Black-Box Knowledge Graphs (KGs) : 스키마, 엔티티 타입, 관계 구조가 사전에 알려져 있지 않은 Knowledge Graph를 지칭합니다.
- Retrieval-Augmented Generation (RAG) : LLM의 생성 능력을 외부 정보 검색(retrieval)을 통해 보강하는 패러다임입니다.
- Optimal Informative Subgraph Retrieval (OISR) : 질의에 대한 Semantic Coverage(recall)와 Information Density(precision)라는 이중 목표를 달성하기 위해 가장 정보성 높은 연결된 서브그래프를 검색하는 문제로, Group Steiner Tree의 변형입니다.
- Candidate Evidence Graphs (CEGs) : BubbleRAG의 Semantic Anchor Group을 커버하며 연결된 서브그래프로, Bubble Expansion heuristic을 통해 발견됩니다.
- Bubble Expansion : Semantic Anchor Group에서 시작하여 낮은 Cost를 가진 영역을 통해 비등방적으로 확장하고, 다른 그룹의 Bubble과 충돌할 때 CEG를 형성하는 휴리스틱 그래프 탐색 알고리즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
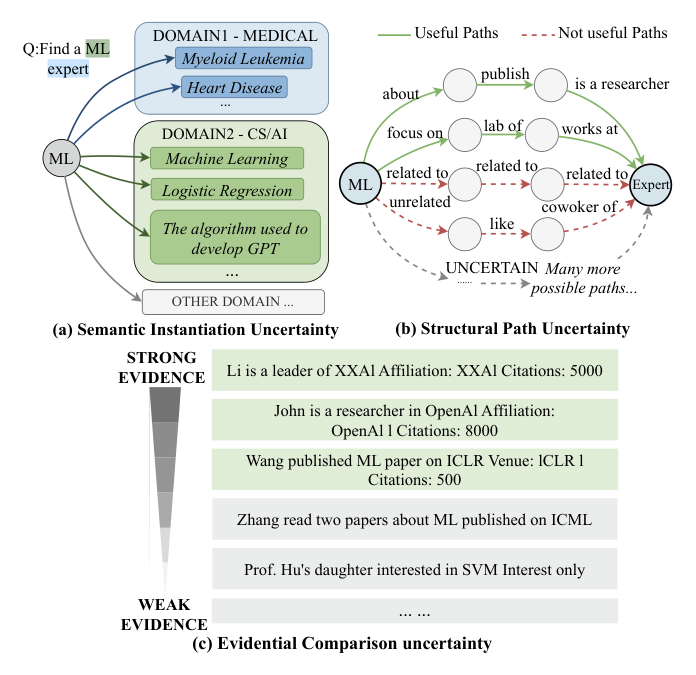
Large Language Models (LLMs)는 Knowledge-intensive task에서 Hallucination 과 outdated knowledge 문제를 겪고 있으며, 이를 해결하기 위해 Graph-based Retrieval-Augmented Generation (RAG)이 유망한 솔루션으로 부상했습니다. 그러나 기존의 접근 방식들은 black-box KGs (스키마와 구조를 알 수 없는 그래프)에서 작동할 때 근본적인 recall 및 precision 한계를 가집니다. 저자들은 이러한 문제를 야기하는 세 가지 핵심 과제를 식별했습니다. 첫째, Semantic instantiation uncertainty 는 질의 개념이 KG 내에서 다양한 형태로 나타날 수 있어 관련 엔티티를 찾지 못해 recall loss 를 유발합니다. 둘째, Structural path uncertainty 는 KG 스키마 지식 부족으로 정보성 높은 관계 연결을 식별하기 어려워 잘못된 탐색 전략으로 인해 recall loss 가 발생합니다. 셋째, Evidential comparison uncertainty 는 KG가 엔티티의 전문성이나 중요성과 같은 고수준 개념을 명시적으로 인코딩하지 않아 질의별 랭킹이 어렵고 precision loss 를 초래합니다. 이 세 가지 과제는 KG retrieval의 recall 과 precision 을 동시에 제한하는 근본적인 문제입니다
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 black-box KGs 를 위한 검색 기반의 training-free 파이프라인인 BubbleRAG 를 제안합니다. BubbleRAG 는 recall 과 precision 을 체계적으로 최적화하기 위해 Semantic Anchor Grouping , heuristic Bubble Expansion , composite ranking , 그리고 Reasoning-Aware Expansion 단계를 포함합니다
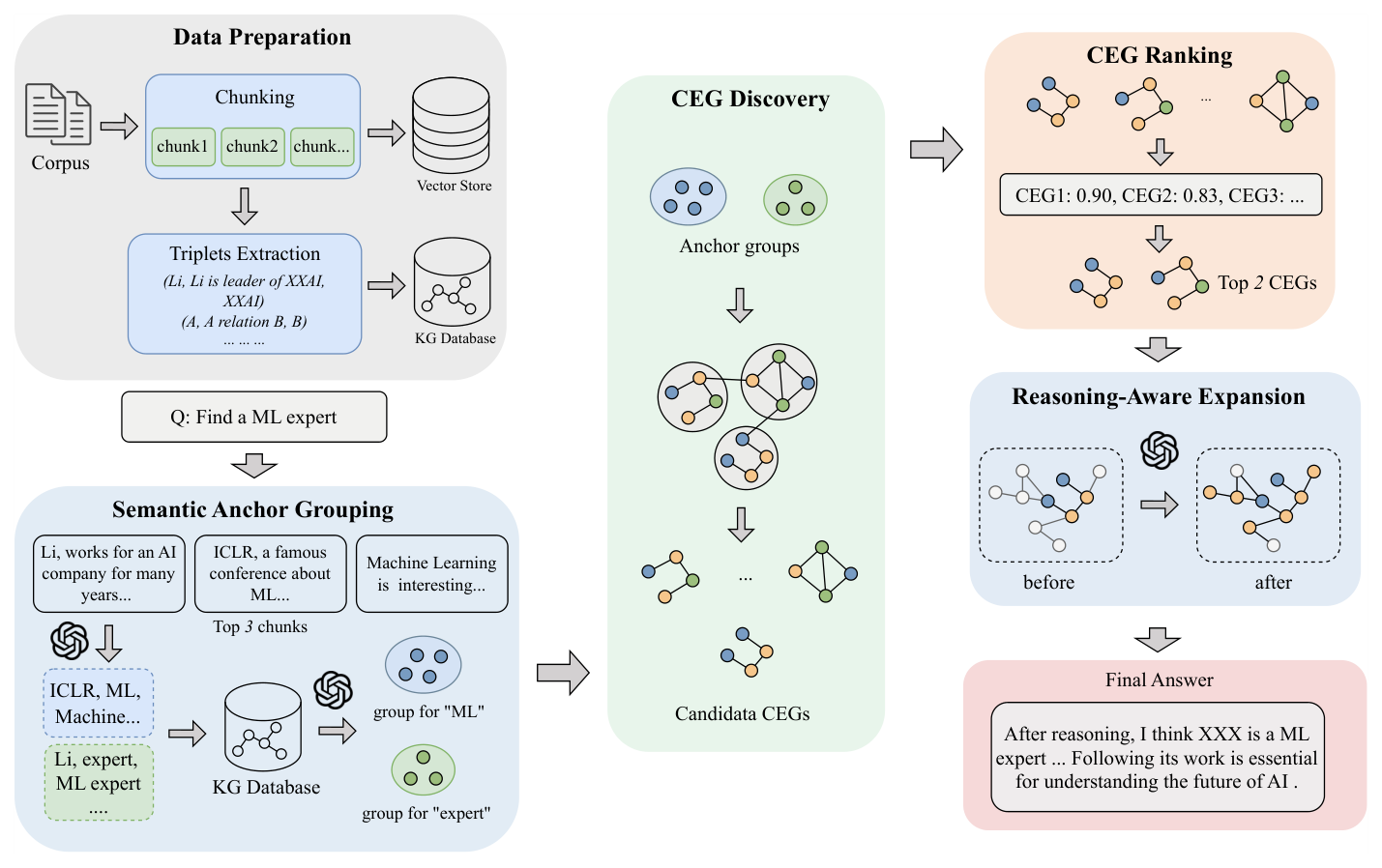
이 방법론은 retrieval task를 Optimal Informative Subgraph Retrieval (OISR) 문제로 공식화하며, 이는 NP-hard 및 APX-hard 임을 이론적으로 증명합니다.
BubbleRAG 의 주요 단계는 다음과 같습니다. 먼저, Semantic Anchor Grouping 은 질의에서 키워드를 추출하고, LLM 추론을 통해 latent concept까지 식별하여 KG 엔티티/관계에 매핑하며, 이를 가중치 있는 앵커 그룹으로 묶어 recall 을 향상시킵니다. 다음으로, Bubble Expansion 은 OISR 목표에 맞춰 Semantic Anchor Group에서 anisotropic 하게 확장하여 Candidate Evidence Graphs (CEGs) 를 발견합니다. 이 과정은 localized graph construction 으로 검색 공간을 제한하고, cost-guided search 로 Query-aligned 구조를 빠르게 발견합니다. 발견된 CEGs 는 CEG Ranking 단계에서 semantic dissonance (Costsem(T)) 및 structural incompleteness (Penalty_miss(T)) 를 고려한 composite score 를 통해 순위를 매겨 precision 을 높입니다. 특히, 패널티 팩터 α를 조절하여 AND , OR , Comparison 질의 유형에 유연하게 대응합니다. 마지막으로, 상위 랭크된 CEGs 에 대해 LLM-guided multi-hop expansion (Reasoning-Aware Expansion)을 적용하여 최종 답변에 필요한 증거 범위를 정제합니다.
실험 결과, BubbleRAG 는 multi-hop QA benchmarks (HotpotQA, MuSiQue, 2WikiMultiHopQA)에서 state-of-the-art 성능을 달성했습니다. 30B model 설정에서 BubbleRAG 는 가장 강력한 Baseline인 HippoRAG2 를 F1 에서 평균 2.52% , accuracy 에서 평균 2.23% 앞섰습니다

특히 복잡한 multi-hop reasoning 이 필요한 MuSiQue 데이터셋에서 30B model 로 53.03 F1 score 를 달성하여 HippoRAG2 보다 약 8%p 높은 성능을 보였습니다. ablation study에서는 Schema Relaxation 이 가장 큰 성능 하락을 야기했으며 (2Wiki에서 11.35 F1 포인트 하락), Anchor Specialization 및 CEG Ranking 도 중요한 기여를 하는 것으로 나타났습니다. 효율성 측면에서, BubbleRAG (20.99s) 는 ToG (45.93s) 보다 훨씬 빨랐으며, HippoRAG2 (4.26s) 보다는 LLM 상호작용으로 인해 높은 Latency를 보였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 black-box KGs 에서 retrieval 하는 문제를 OISR 이라는 최적화 문제로 공식화하고, 이를 해결하기 위한 BubbleRAG 프레임워크를 제안했습니다. BubbleRAG 는 Semantic Anchor Grouping 과 heuristic Bubble Expansion 을 통해 recall 을 높이고, Candidate Evidence Graph Ranking 과 Reasoning-Aware Expansion 을 통해 precision 을 향상시키는 체계적인 접근 방식을 제공합니다. 실험 결과, BubbleRAG 는 multi-hop QA benchmarks 에서 state-of-the-art 성능을 입증하며, 특히 복잡한 추론 문제에서 강력한 이점을 보여주었습니다. 이 연구는 black-box KGs 를 활용하는 multi-hop QA 및 knowledge-intensive tasks 를 위한 robust 하고 scalable 한 솔루션을 제공합니다. 또한, BubbleRAG 의 plug-and-play 설계는 underlying KG 구조에 대한 fine-tuning이나 수정 없이 적용 가능하여 다양한 실제 시나리오에서의 활용 가능성을 높입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] s2n-bignum-bench: A practical benchmark for evaluating low-level code reasoning of LLMs
- 현재글 : [논문리뷰] BubbleRAG: Evidence-Driven Retrieval-Augmented Generation for Black-Box Knowledge Graphs
- 다음글 [논문리뷰] F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
댓글