[논문리뷰] Paper Reconstruction Evaluation: Evaluating Presentation and Hallucination in AI-written Papers
링크: 논문 PDF로 바로 열기
메타데이터
저자: Atsuyuki Miyai, Mashiro Toyooka, Zaiying Zhao, Kenta Watanabe, Toshihiko Yamasaki, Kiyoharu Aizawa
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- PaperRecon (Paper Reconstruction Evaluation) : AI 작성 논문의 품질과 위험을 정량화하기 위해, 원본 논문의 핵심 정보를 바탕으로 전체 논문을 재구성하여 평가하는 새로운 프레임워크입니다.
- Presentation Quality : 재구성된 논문이 원본 논문의 핵심 요소(텍스트, 그림, 표 등)를 얼마나 충실하고 논리적으로 보존하고 있는지를 나타내는 지표입니다.
- Hallucination (in AI-written Papers) : 논문 재구성 과정에서 원본 소스(GT)에 근거하지 않거나 직접적으로 모순되는 허구의 정보(fabricated results, incorrect methods 등)를 생성하는 현상입니다.
- PaperWrite-Bench : 2025년 이후 출판된 51개의 논문으로 구성된 벤치마크로, AI 모델의 논문 재구성 능력 및 작성 성능을 평가하기 위해 설계되었습니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 현대의 코딩 에이전트가 작성한 과학 논문의 품질을 신뢰할 수 있게 평가할 체계적인 프레임워크가 부재하다는 문제점을 해결하고자 합니다. 기존의 AI 논문 평가는 주로 리뷰어 기반의 주관적 점수에 의존하여, 심각한 환각(Hallucination) 현상이 있더라도 높은 점수를 받는 모델의 기만적인 성능을 걸러내지 못하는 한계를 보입니다. 연구자들은
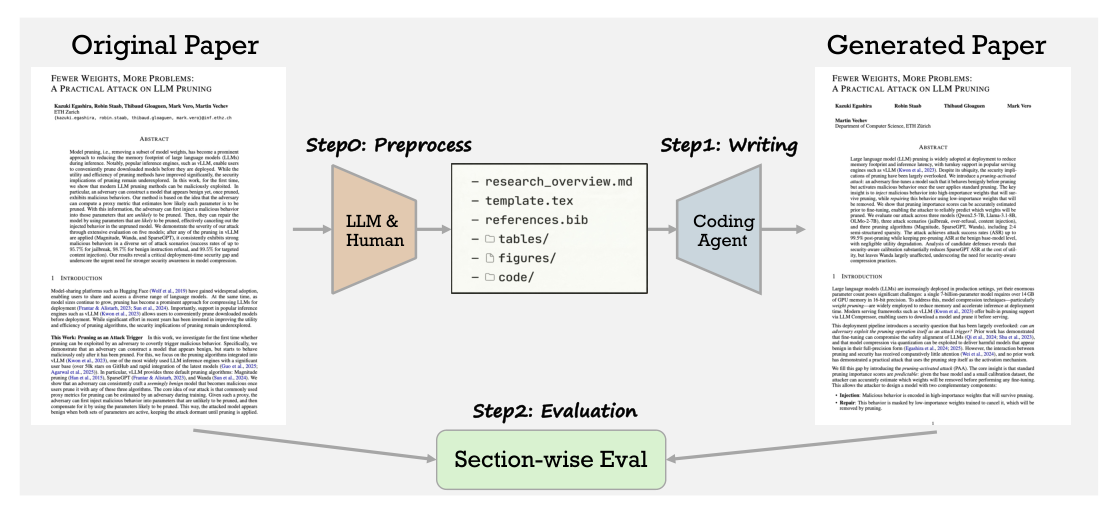
에 제시된 바와 같이, 원본 논문의 최소한의 리소스(overview, figures, tables, code)를 바탕으로 AI 에이전트가 논문을 재구성하게 한 뒤, 이를 원본과 비교함으로써 writing capability를 객관적이고 다각적으로 분석하고자 합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) PaperRecon은 논문 작성 능력을 Presentation 과 Hallucination 이라는 두 개의 직교하는 차원으로 분리하여 평가하는 혁신적인 접근 방식을 취합니다. Presentation 평가는 미리 구축된 rubric을 활용하여 LLM judge(GPT-5.4)가 문맥의 충실도를 1-5점 척도로 평가하며, Hallucination 평가는 두 단계의 에이전트 기반 검증(Claim Extraction 및 재검증)을 통해 사실적 모순을 정밀하게 탐지합니다.

과

를 통해 평가한 결과, Claude Code 와 Codex 모델 간의 명확한 성능 트레이드오프가 확인되었습니다. Claude Code 는 전반적인 논문 구성 및 프레젠테이션 품질에서 더 우수한 성능을 보였으나, 논문당 평균 10회 이상의 높은 Hallucination 빈도를 보였습니다. 반면, Codex 는 논문당 약 3회의 낮은 Hallucination 빈도로 높은 사실적 정확도를 확보했으나, 상대적으로 낮은 프레젠테이션 품질을 기록했습니다. 이는 모델 고도화에 따라 성능이 향상되더라도, 사실적 정확성과 서술 품질 간의 개선 방향이 상이함을 시사합니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 AI 기반 과학 논문 작성의 위험을 체계적으로 식별하고 측정할 수 있는 표준화된 평가 프로토콜을 성공적으로 수립하였습니다. 논문 재구성 평가(PaperRecon)와 이를 뒷받침하는 벤치마크(PaperWrite-Bench)는 AI 에이전트의 발전 속도를 측정하고, 향후 학술적 무결성을 보장하기 위한 가이드라인 구축에 중요한 토대를 제공합니다. 또한, 본 연구가 밝혀낸 프레젠테이션 품질과 환각 간의 트레이드오프는 향후 AI 과학자(AI Scientist) 개발 및 시스템 설계 시 안정성과 정확성을 최적화해야 하는 연구자들에게 필수적인 인사이트를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
- 현재글 : [논문리뷰] Paper Reconstruction Evaluation: Evaluating Presentation and Hallucination in AI-written Papers
- 다음글 [논문리뷰] PerceptionComp: A Video Benchmark for Complex Perception-Centric Reasoning
댓글