[논문리뷰] GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
링크: 논문 PDF로 바로 열기
저자: Mingyu Ouyang, Siyuan Hu, Kevin Qinghong Lin, Hwee Tou Ng, Mike Zheng Shou
1. Key Terms & Definitions (핵심 용어 및 정의)
- Computer-Use Agent (CUA): raw keyboard 및 mouse control을 직접 생성하여 게임을 제어하는 에이전트 인터페이스입니다.
- Semantic Action Parsing: Generalist multimodal agent가 고수준의 semantic action을 수행하도록 하고, 이를 deterministic하게 low-level control로 변환하는 메커니즘입니다.
- Outcome-based State-Verifiable Evaluation: 비디오 프레임에 의존하는 heuristic이나 VLM-as-judge 대신, serialized gameAPI state를 통해 task 성공 및 progress를 정량적으로 측정하는 평가 방식입니다.
- GameWorld-RT: 에이전트의 추론 시간 동안에도 게임 환경이 일시 중지되지 않고 지속되는 실시간 벤치마크 변형 버전입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 Multimodal Large Language Model(MLLM) 기반 게임 에이전트의 체계적인 평가를 가로막는 표준화된 인터페이스의 부재와 검증 방식의 한계를 극복하기 위해 수행되었습니다. 기존 연구들은 heterogeneous한 action interface와 노이즈가 많은 heuristic 기반 평가 방식에 의존하고 있어 결과의 재현성과 신뢰성이 낮다는 문제점이 있습니다. 특히 실시간 게임 환경에서 발생하는 latency가 에이전트의 성능과 밀접하게 연관되어 있음에도, 많은 벤치마크가 이를 무시하거나 추론 시간을 배제한 평가만을 수행해왔습니다. 이를 해결하기 위해 저자들은 게임 수행 능력을 정량적이고 객관적으로 측정할 수 있는 `

`와 같은 표준화된 프레임워크가 필요함을 강조합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 34개의 다양한 게임과 170개의 작업을 포함하는 [Table 3]과 같은 범용적인 게임 에이전트 벤치마크인 GameWorld를 제안합니다. 제안된 방법론은 환경과 에이전트 간의 interaction을 표준화된 Semantic Action Parsing으로 정렬하고, `
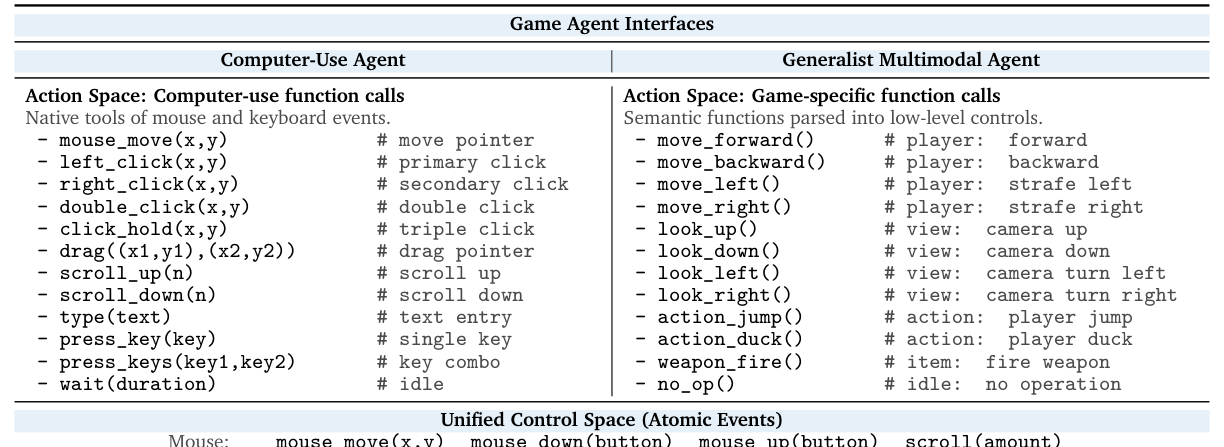
에 정의된 atomic interaction event를 사용하여 제어 공간을 통일하였습니다. 18개의 다양한 모델-인터페이스 쌍을 실험한 결과, 최고 성능의 에이전트조차 인간 수준의 숙련도에는 크게 미치지 못함을 확인했습니다. 또한 **GameWorld** 내에서 가장 높은 PG(Progress)를 기록한 모델은 **Gemini-3-Flash-Preview**로, 전반적인 task 완성도 측면에서 **GPT-5.2**를 포함한 다른 모델들보다 우수한 성능을 보였습니다
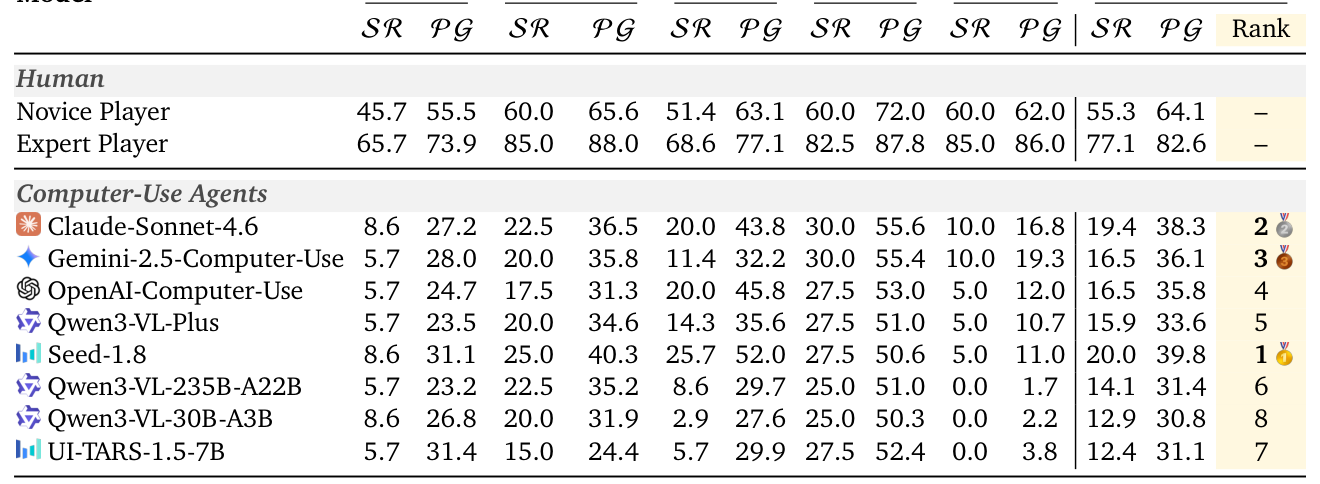
. 특히, memory rounds를 증가시켰을 때 일반적인 모델은 PG가 상승했으나 CUA 모델은 오히려 성능이 저하되는 흥미로운 경향성을 발견하였습니다 [Table 9]`.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 GameWorld를 통해 multimodal game agent를 위한 표준화된, 검증 가능한 평가 체계를 성공적으로 구축하였습니다. 실험 결과는 현존하는 MLLM 에이전트들이 전략적 결정에는 강점을 보이나, 정밀한 timing, spatial navigation, 그리고 장기적인 coordination 작업에서는 심각한 병목 현상을 겪고 있음을 시사합니다. 이 벤치마크는 향후 연구자들이 에이전트의 제어 능력과 reasoning 능력을 개선할 방향을 명확히 제시하며, 보다 견고하고 신뢰할 수 있는 embodied generalist 개발을 위한 핵심 플랫폼으로 자리매김할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MultiRef-Compass: Towards Comprehensive Evaluation of Multi-Reference-to-Audio-Video Generation
- [논문리뷰] OvisOCR2 Technical Report
- [논문리뷰] AdvancedMathBench: A Benchmark Suite for Advanced Mathematical Proof Generation and Verification
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
Review 의 다른글
- 이전글 [논문리뷰] From P(y|x) to P(y): Investigating Reinforcement Learning in Pre-train Space
- 현재글 : [논문리뷰] GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
- 다음글 [논문리뷰] Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
댓글