[논문리뷰] Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ka Yiu Lee, Yuxiang Chen, Zhiyuan He, Yihang Chen, Yuxuan Huang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Web-to-Table Search: 자연어 쿼리와 목표 스키마를 입력받아, 웹 검색을 통해 개체를 열(row)로, 속성을 행(column)으로 구성한 구조화된 테이블을 생성하는 작업입니다.
- Bi-Level Architecture: 상위 레벨의 Orchestrator가 복잡한 쿼리를 분해(decomposition)하고, 하위 레벨의 여러 Worker가 병렬로 작업을 수행하는 계층적 시스템 구조를 의미합니다.
- Shared Workboard: 여러 Worker가 비동기적으로 작업 진행 상황을 공유하고, 중복 탐색을 방지하며, 수집된 증거를 취합하는 Markdown 기반의 공용 메모리 영역입니다.
- Run–Verify–Reflect Loop: 훈련 과정에서 시스템이 작업을 수행(Run)하고 결과를 검증(Verify)한 뒤, 오류를 분석하여 Skill Bank를 업데이트(Reflect)하는 자동화된 학습 파이프라인입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 웹 정보 탐색에서 깊이 있는 추론과 넓은 범위의 구조화된 데이터 집계라는 두 가지 상충하는 요구를 동시에 만족해야 하는 문제를 해결하고자 합니다. 기존의 단일 에이전트 모델은 복잡한 쿼리 처리 시 context window의 한계, 오류 축적, 그리고 고정된 계획 수립으로 인해 확장성 있는 웹 정보 추출에 명확한 한계를 보입니다. 특히, 여러 엔티티와 속성을 포함하는 넓은 범위(Wide Search)의 탐색에서 구조적 일관성을 유지하는 능력이 부족합니다. 저자들은 이러한 한계를 극복하기 위해 계획(decomposition)과 실행(execution)을 동시에 최적화할 수 있는 새로운 다중 에이전트 프레임워크가 필요함을 역설합니다 [Figure 2].
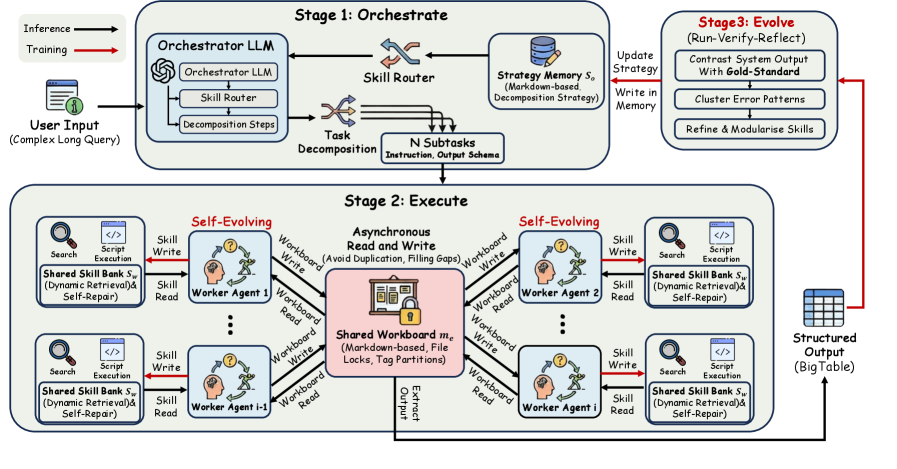
Figure 2 — Web2BigTable 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 상위 수준의 Orchestrator와 하위 수준의 Worker로 구성된 Web2BigTable 프레임워크를 제안합니다. 제안 방법론의 핵심은 Gradient 업데이트 없이 외부 메모리(Skill Banks)를 활용하여 시스템이 스스로 진화(Self-Evolving)하도록 설계한 것입니다. Orchestrator는 쿼리 유형에 따라 분해 전략을 선택하고, Worker들은 Shared Workboard를 통해 실시간으로 작업 상태를 공유하여 동적으로 협업합니다 [Figure 1]. 훈련 과정에서는 Run–Verify–Reflect 루프를 통해 사람이 읽을 수 있는 형식의 Skill Bank를 모노토닉(Monotone)하게 축적합니다 [Figure 3].
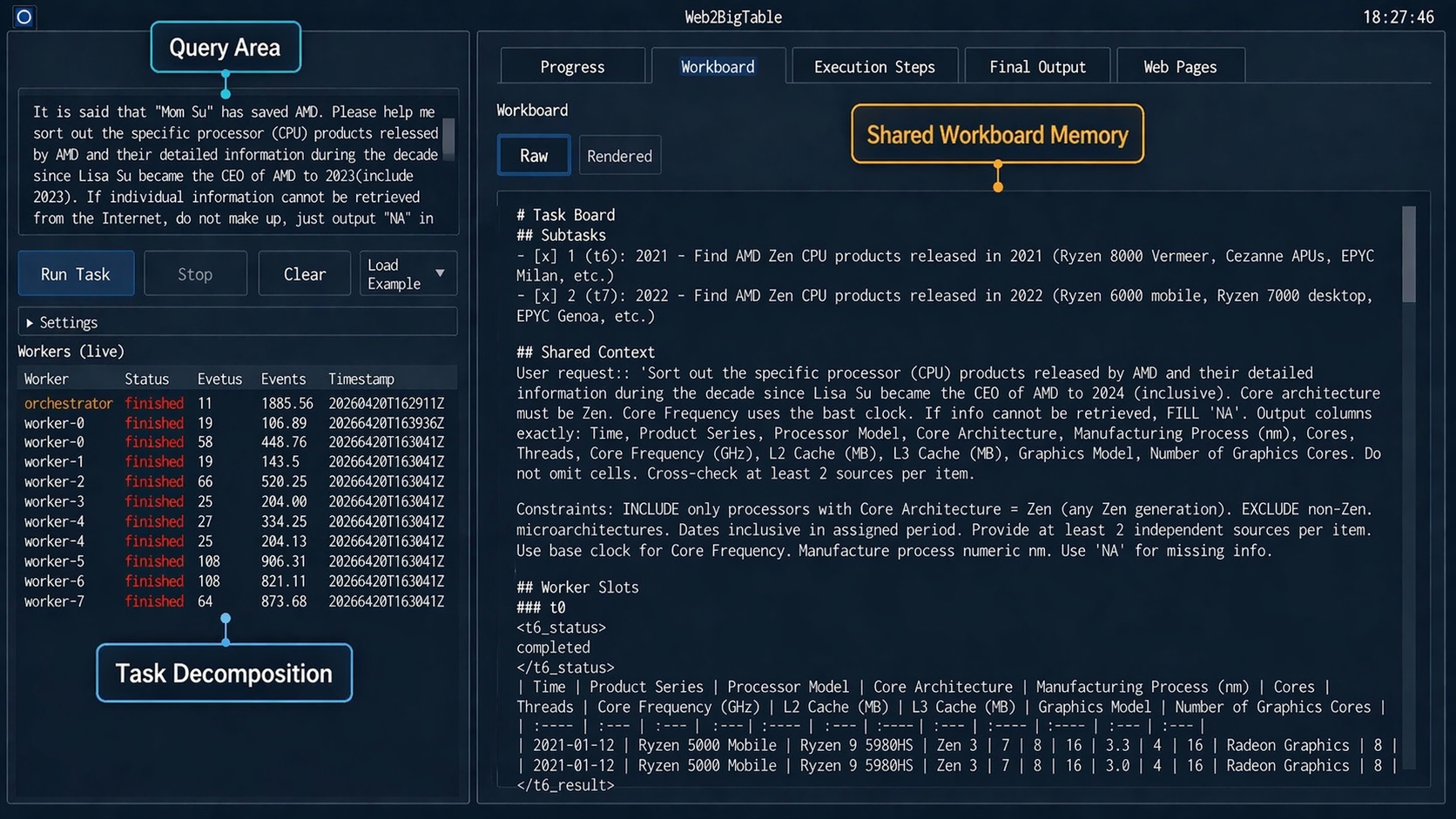
Figure 1 — Web2BigTable 실행 인터페이스
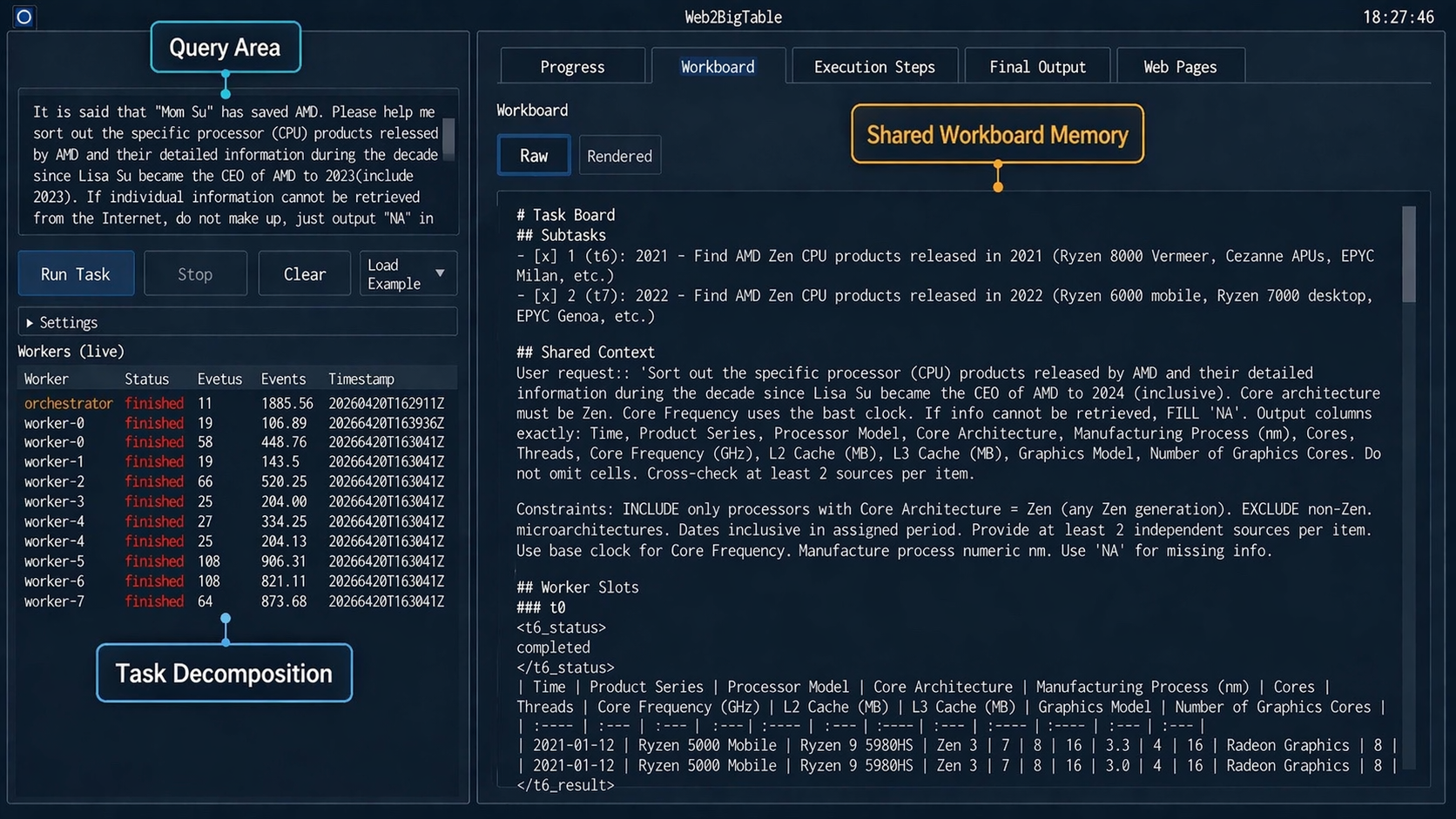
Figure 3 — 훈련 및 진화 프로세스
실험 결과, 제안 모델은 WideSearch 벤치마크에서 기존 최고 성능 대비 압도적인 우위를 점하였습니다. Avg@4 Success Rate 38.50, Row F1 63.53, Item F1 80.12를 기록하며 SOTA를 달성했습니다 [Table 3]. 또한 XBench-DeepSearch에서도 73.0의 높은 정확도를 기록하며 다양한 탐색 환경에서의 범용성을 입증했습니다. 특히, 사전 훈련된 모델들의 단일 에이전트 성능과 비교했을 때 프레임워크 기반의 구조적 이점이 성능 향상의 핵심 동력임을 입증하였습니다 [Table 2].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 대규모 웹 정보 추출을 위한 bi-level 메모리 기반 다중 에이전트 프레임워크인 Web2BigTable을 성공적으로 제시하였습니다. 이 연구는 모델의 가중치를 직접 튜닝하지 않고도 외부 메모리를 통한 전략적 최적화와 동적 협업만으로도 뛰어난 성능 향상이 가능함을 보여주었습니다. 향후 이 시스템은 학계의 에이전트 자율성 연구뿐만 아니라, 산업 현장에서 방대한 웹 데이터를 신속하고 정확하게 구조화해야 하는 다양한 비즈니스 요구사항을 충족하는 기반 기술로 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
- [논문리뷰] LectūraAgents: A Multi-Agent Framework for Adaptive Personalized AI-Assisted Learning and Embodied Teaching
- [논문리뷰] Orchestra-o1: Omnimodal Agent Orchestration
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
- [논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
Review 의 다른글
- 이전글 [논문리뷰] UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors
- 현재글 : [논문리뷰] Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
- 다음글 [논문리뷰] AcademiClaw: When Students Set Challenges for AI Agents
댓글