[논문리뷰] UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tianrui Zhu, Hong Li, Anyi Rao, Xianghao Kong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Stochastic Condition Masking (SCM): 학습 중 모달리티를 정제된 조건(clean condition)과 노이즈가 섞인 타겟(noisy target)으로 무작위 분할하여, 고정된 input-output mapping 없이 다방향 conditional generation을 학습하게 하는 기법입니다.
- Decoupled Gated LoRA (DGL): 각 모달리티마다 독립적인 LoRA 모듈을 할당하고, 해당 모달리티가 타겟일 때만 이를 활성화하여 파라미터 간 간섭을 방지하고 VDM의 강력한 사전 지식을 보존하는 기법입니다.
- Cross-Modal Self-Attention (CMSA): 모든 모달리티의 key와 value를 공유하여 통합된 컨텍스트를 형성하면서, 쿼리(query)는 모달리티별로 유지함으로써 모달리티 간의 spatiotemporal consistency와 밀접한 상호작용을 보장하는 기법입니다.
- UniVid-Intrinsic / UniVid-Alpha: 본 논문에서 제안한 프레임워크를 각각 물리적 구성 요소(albedo, irradiance, normal) 및 레이어 분해(RGBA) 도메인에 적용한 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 비디오 생성 연구들은 각 문제 설정(예: Text-to-Video, Inverse Rendering)에 대해 개별적인 모델을 학습시키는 파편화된 방식을 취하고 있어, 고정된 입력-출력 매핑에 제한되고 모달리티 간의 상호 상관관계를 활용하지 못하는 한계가 있습니다. 이러한 방식은 다채로운 그래픽스 애플리케이션에서 요구되는 유연성을 저해하며, 직렬식(serial) 멀티모달 추론 시 결과물 간의 일관성을 저하시킵니다 [Figure 1]. 본 논문은 이러한 불투명하고 파편화된 설계를 해결하기 위해, 비디오 모델이 다양한 멀티모달 입력을 조건 또는 타겟으로 유연하게 활용할 수 있는 통일된 생성 프레임워크를 제안합니다.

Figure 1 — UniVidX의 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VDM의 강력한 생성 사전 지식(Diffusion Priors)을 유지하면서 다목적 생성 태스크를 수행하기 위해 UniVidX 프레임워크를 제안합니다 [Figure 2]. SCM을 통해 다양한 비디오 태스크를 단일 조건 생성 문제로 통합하고, DGL을 통해 모달리티별 분포 차이를 효율적으로 학습하며, CMSA를 통해 모달리티 간의 공간적·시간적 정렬을 강화합니다. 실험 결과, UniVid-Intrinsic은 기존 단일 도메인 방법론(예: IntrinsiX) 대비 더 높은 temporal stability와 modality consistency를 보이며, 특히 Sintel 데이터셋에서 기존 전문 normal estimation 모델들보다 적은 학습 데이터(19K 프레임)로도 대등하거나 우수한 성능을 입증했습니다 [Table 4]. UniVid-Alpha 또한 기존의 mask-guided 방식들을 능가하며 최신(SOTA) 수준의 video matting 및 RGBA 합성을 달성하였습니다 [Table 5]. 이러한 모델들은 학습 데이터가 1,000개 미만인 제한적인 환경에서도 robust한 일반화 능력을 보입니다 [Figure 3], [Figure 7].
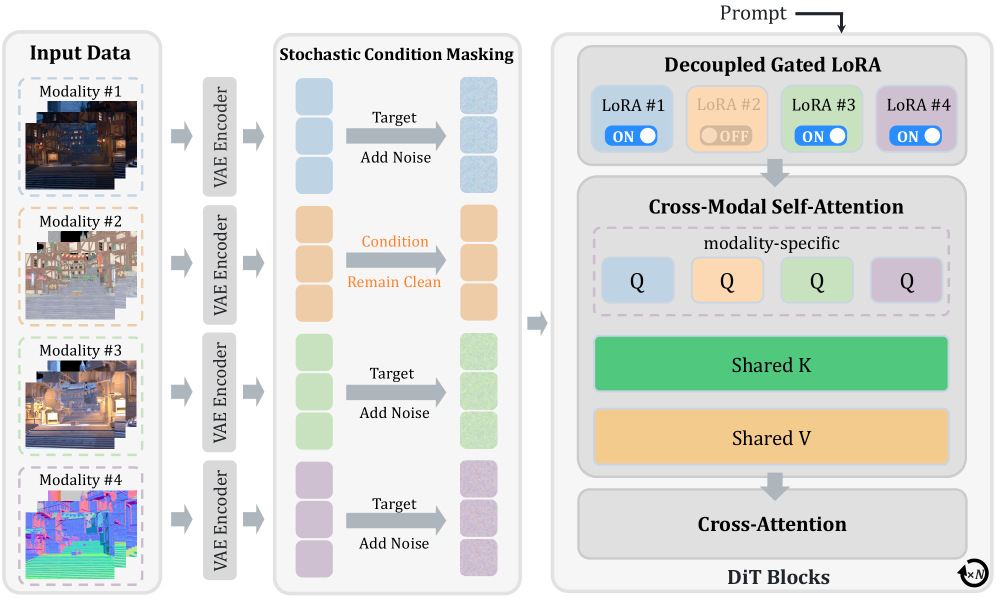
Figure 2 — UniVidX 모델 아키텍처

Figure 3 — Text-to-Intrinsic 결과 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 SCM, DGL, CMSA를 결합하여 멀티모달 비디오 생성을 위한 통일된 생성 프레임워크인 UniVidX를 성공적으로 구축했습니다. 본 연구는 개별 태스크에 고립되었던 모델들을 하나의 생성 로직으로 통합하여, 그래픽스 분야의 다양한 하류 작업(video relighting, inpainting, material editing 등)에 필요한 유연성과 일관성을 확보했습니다. 제안된 프레임워크는 사전 학습된 대형 VDM의 강력한 Prior를 효율적으로 활용하여, 데이터 효율성을 극대화함으로써 향후 멀티모달 비디오 모델링의 표준적인 방법론으로서 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
- [논문리뷰] DomainShuttle: Freeform Open Domain Subject-driven Text-to-video Generation
- [논문리뷰] FLAT: Feedforward Latent Triangle Splatting for Geometrically Accurate Scene Generation
- [논문리뷰] RhymeFlow: Training-Free Acceleration for Video Generation with Asynchronous Denoising Flow Scheduling
Review 의 다른글
- 이전글 [논문리뷰] Trees to Flows and Back: Unifying Decision Trees and Diffusion Models
- 현재글 : [논문리뷰] UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors
- 다음글 [논문리뷰] Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
댓글