[논문리뷰] VOID: Video Object and Interaction Deletion
링크: 논문 PDF로 바로 열기
저자: Saman Motamed, William Harvey, Benjamin Klein, Luc Van Gool, Zhuoning Yuan, Ta-Ying Cheng
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- VOID (Video Object and Interaction Deletion) : 객체뿐만 아니라 해당 객체로 인해 발생하는 물리적 상호작용까지 제거하여 인과적으로 일관된 결과를 생성하는 비디오 편집 프레임워크입니다.
- Counterfactual Dataset : 객체가 제거된 상황에서 발생할 변화(예: 물리적 충돌 제거, 중력에 의한 낙하)를 시뮬레이션하기 위해 Kubric 및 HUMOTO 를 활용하여 생성된 paired 데이터셋입니다.
- Quadmask : 객체 제거 시 영상 내 변화가 필요한 영역을 정밀하게 제어하기 위해 기존의 3단계 trimask를 확장하여, 제거 대상, 영향 받는 영역(Overlap 포함), 보존 영역을 4가지 색상으로 구분한 조건부 입력 포맷입니다.
- VLM-as-a-judge : 비디오 모델의 물리적 타당성과 편집 품질을 정량적으로 평가하기 위해 사전 학습된 VLM(예: Gemini 3 Pro )을 활용하는 평가 프로토콜입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 비디오 객체 제거 기법들이 단순한 배경 인페인팅에 국한되어, 제거된 객체가 주변 환경과 맺고 있는 인과적 물리 상호작용(예: 충돌, 지지 관계)을 보존하거나 재구성하지 못한다는 한계에서 출발합니다. 기존 모델들은 객체만을 지울 뿐, 그로 인해 영향을 받는 후속 동작을 인지하지 못해 물리적으로 불가능한 결과(예: 객체가 사라졌음에도 여전히 움직이는 잔상)를 생성합니다. 따라서 영상 편집 모델이 단순한 시각적 인페인팅을 넘어, 환경의 물리 법칙을 이해하고 추론하는 시뮬레이터 역할을 수행할 수 있도록 하는 새로운 프레임워크가 요구됩니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 CogVideoX 확산 모델을 기반으로, 물리적 인과 관계를 반영하는 카운터팩추얼 생성 모델을 구축하였습니다. 먼저 Kubric 과 HUMOTO 를 통해 객체 제거 전후의 물리적 역학 변화를 학습하고, VLM을 활용해 영상 내 영향받는 영역을 실시간으로 추론하여 Quadmask 를 생성함으로써 모델의 생성 범위를 명확히 제한합니다. 또한 첫 번째 패스에서 생성된 영상의 구조적 변형을 해결하기 위해, 두 번째 패스에서 광학 흐름(optical flow) 기반의 변형된 노이즈를 사용하여 시간적 일관성과 객체 강성을 보존하는 Flow-Warped Noise Stabilization 기법을 적용하였습니다. 실사용 환경 75개 시나리오에 대한 인간 평가 결과, 본 제안 모델은 64.8% 의 선호도를 기록하며 기존 기법들을 압도하였으며, 합성 데이터 벤치마크에서도 FVD 260.31, VLM-Judge 25.10으로 최고 성능을 달성하였습니다.
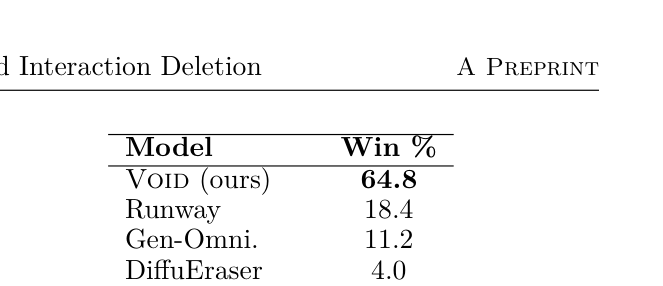
과
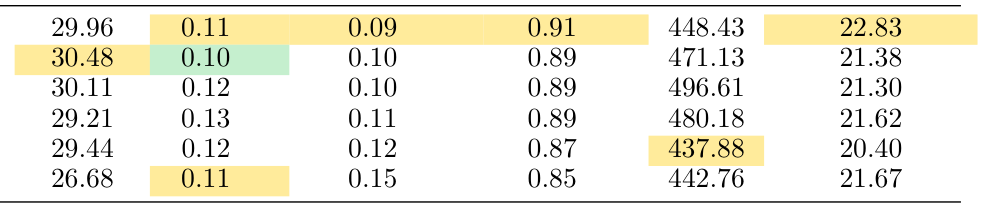
은 이러한 정량적 우위를 명확히 보여줍니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 비디오 편집이 단순히 시각적 정보를 채우는 작업이 아니라, 고차원적인 물리적 인과 추론 과정임을 입증하였습니다. VOID 프레임워크는 물리적 환경 변화를 효과적으로 모델링함으로써 기존의 비디오 생성 모델들이 가진 물리적 왜곡 문제를 해결하는 데 큰 기여를 했습니다. 본 연구는 향후 복잡한 물리 시뮬레이션 기반의 비디오 생성 및 편집 모델 연구를 위한 중요한 이정표가 될 것이며, 실세계 영상 데이터를 활용한 세계 모델링(World Modeling) 연구의 가능성을 확장했다는 점에서 의의가 큽니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] InstanceControl: Controllable Complex Image Generation without Instance Labeling
Review 의 다른글
- 이전글 [논문리뷰] UniRecGen: Unifying Multi-View 3D Reconstruction and Generation
- 현재글 : [논문리뷰] VOID: Video Object and Interaction Deletion
- 다음글 [논문리뷰] VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification
댓글