[논문리뷰] GRASP: Learning to Ground Social Reasoning in Multi-Person Non-Verbal Interactions
링크: 논문 PDF로 바로 열기
저자: Junho Kim, Xu Cao, Houze Yang, Bikram Boote, Ana Jojic, Fiona Ryan, Bolin Lai, Sangmin Lee, James M. Rehg
키워: Social Reasoning, Non-Verbal Interactions, Gaze, Gesture, MLLMs, GRASP, Social Grounding Reward, Video QA
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRASP (Grounded Reasoning And Social Perception): 다중 인원 비언어적 상호작용에 대한 사회적 추론을 grounding하는 대규모 데이터셋.
- MLLMs (Multimodal Large Language Models): 시각적 인지 능력과 강력한 추론 능력을 통합한 모델로, 사회적 상호작용을 이해하는 데 사용된다.
- Non-Verbal Cues: Gaze(시선) 및 Deictic Gesture(지시적 제스처)와 같은 미묘한 비언어적 신호로, 사회적 상호작용의 의미를 전달한다.
- Social Grounding Reward (SGR): 모델이 근본적인 사회적 이벤트에 관련된 정확한 참가자들을 참조하도록 장려하는 학습 신호.
- GRASP-Bench: GRASP 데이터셋 기반으로 구축된 1,000개의 curated 테스트 아이템으로 구성된 벤치마크.
- Deictic Gesture: Pointing, Showing, Giving, Reaching을 포함하며, 타겟을 향한 주의를 지시하거나 상호작용 의도를 나타내는 communicative hand gesture.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재 MLLMs가 다중 인원 비디오에서 미묘한 비언어적 단서에 기반한 사회적 추론을 수행하는 데 어려움을 겪는 문제를 해결합니다. 기존 MLLMs는 시각적 장면에서 사람과 행동을 인식할 수 있지만, 이를 참가자 간의 temporally grounded social event로 조직하는 데 실패하여, 누가 누구와 상호작용하는지, 어떤 단서가 관련되어 있는지 식별하기 어렵습니다. MLLMs의 추론은 미세한 시각적 증거에 주의를 기울이기보다는 종종 언어적 또는 장면 수준의 priors에 의존하여 [Figure 1]과 같이 spurious reasoning trace를 생성합니다. 기존 사회적 데이터셋들은 단일 fine-grained cue나 high-level social QA에 초점을 맞춰, 여러 비언어적 단서가 사회적 추론을 어떻게 grounding하는지 공동으로 감독하는 대규모 supervision이 부족한 한계점을 가집니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 fine-grained gaze 및 deictic gesture 이벤트에서 사회적 추론을 grounding하기 위한 대규모 데이터셋인 GRASP와 효과적인 학습 신호인 Social Grounding Reward (SGR)를 제안합니다. GRASP는 다중 인원 비디오를 person-consistent gaze trajectory 및 deictic gesture 이벤트로 변환하고, 이를 social event로 구성하는 bottom-up pipeline을 통해 구축됩니다 [Figure 2]. 이 데이터셋은 46K 비디오(총 749시간)에 걸쳐 290K 개의 QA 쌍을 포함하며, gaze, gesture, 그리고 joint gaze-gesture reasoning을 아우르는 16개 카테고리 taxonomy로 구성됩니다 [Figure 3].

Figure 2 — GRASP 데이터셋의 전체 구축 파이프라인과 QA 예시를 시각적으로 보여주는 핵심 다이어그램.
훈련 전략은 두 단계로 진행됩니다: (i) Structured Format Supervised Fine-Tuning (SFT)으로 모델을 초기화하여 gaze 및 gesture 증거를 명시적으로 분리하여 추론하도록 가르치고, (ii) Grounded Reinforcement Post-Training 단계에서 SGR을 포함한 reward를 사용하여 정책을 최적화합니다. SGR은 모델의 추론이 근본적인 사회적 이벤트에 관련된 올바른 참가자들을 참조하는지 확인하는 학습 신호로, 예측된 참가자 ID와 실제 참가자 ID 간의 overlap을 비교하는 가중치 precision-recall formulation을 사용합니다 [Table 3].
핵심 결과:
- GRASP-Bench에서, SGR이 적용된 모델은 모든 16가지 추론 유형에서 기존 SFT 모델 및 RL post-training baseline 모델을 일관되게 능가하는 성능을 보였습니다 [Table 1]. 특히 Qwen3.5-9B + SGR 모델은 전체 평균 정확도 52.6%를 달성하여, Qwen3.5-9B (Instruct)의 40.8% 및 GRPO 기반 Qwen3.5-9B (Thinking Mode)의 31.7%를 크게 상회했습니다.
- 외부 벤치마크 (MMSI, Online-MMSI, TVQA+)에 대한 zero-shot generalization 결과, SGR 훈련 모델은 기존 instruction-tuned backbone 및 RL post-training baseline과 비교하여 경쟁력 있거나 더 우수한 성능을 보였습니다 [Table 2]. 예를 들어, Qwen3.5-9B + SGR은 MMSI에서 평균 62.1%를 기록하며 Qwen3.5-9B (Instruct)의 61.6%보다 높은 성능을 보였습니다.
- SGR은 모델의 reasoning이 올바른 참가자들을 지칭하는지 확인함으로써, grounding precision을 높이고 [Figure 5] 동시에 reasoning length를 단축시키면서 정확도를 향상시킵니다.
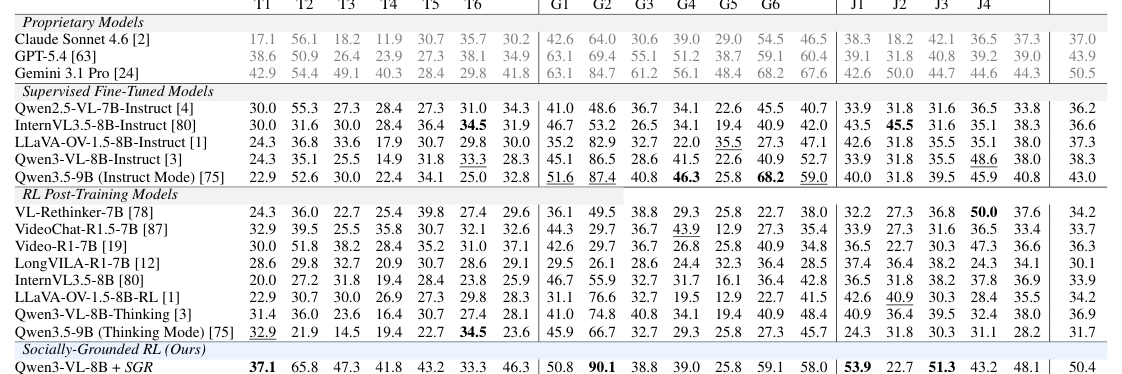
Table 1 — 제안된 SGR 방법론의 GRASP-Bench에서의 정량적 성능 우수성을 보여주는 주요 결과 테이블.
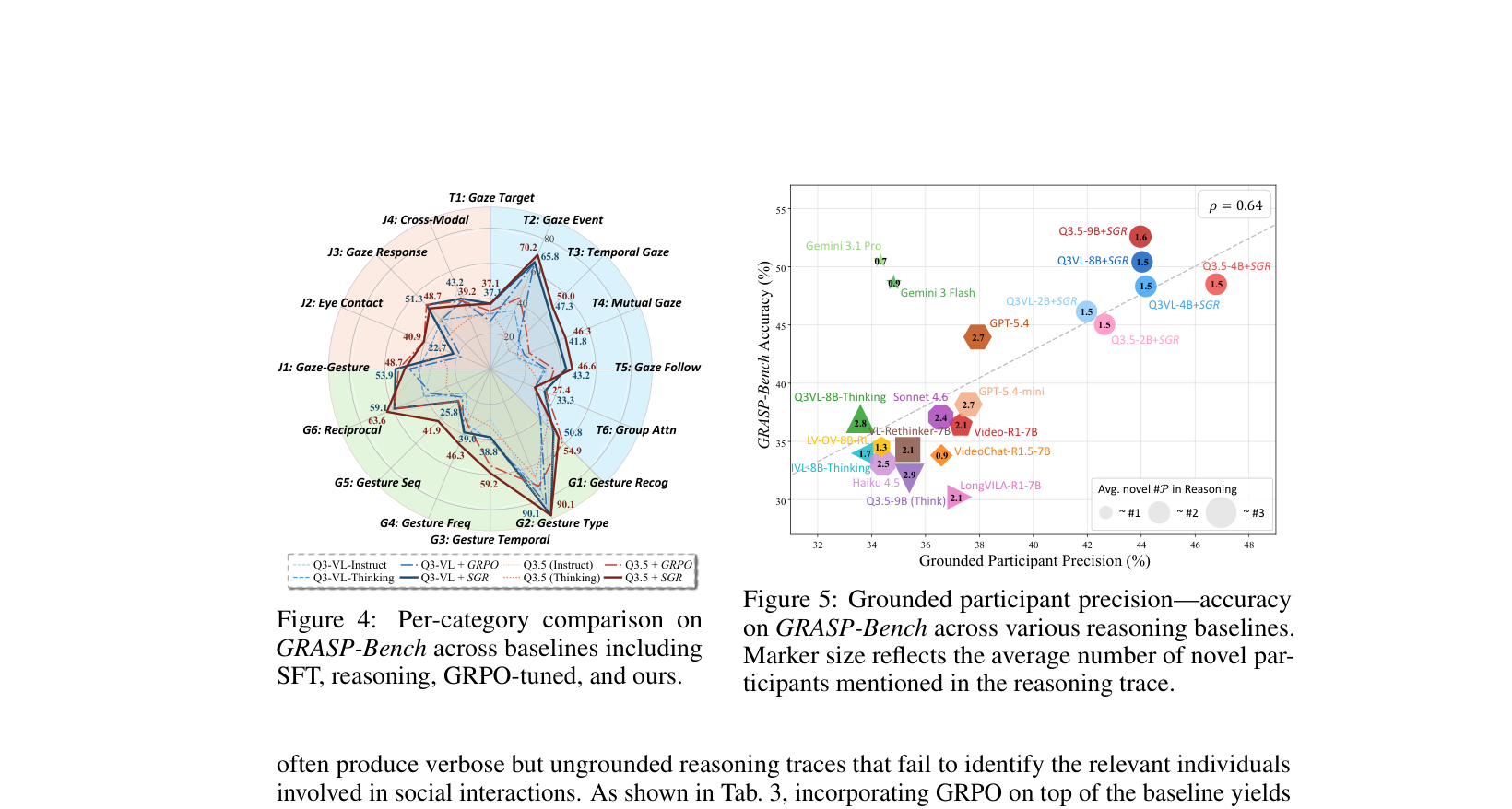
Figure 5 — Grounding Precision과 Accuracy 간의 상관관계를 시각적으로 보여주며, SGR의 효과를 지지하는 중요한 분석 결과.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 fine-grained gaze 및 gesture 이벤트에 grounding된 사회적 추론을 위한 대규모 데이터셋 GRASP와 모델이 관련 비언어적 증거에 추론을 grounding하도록 장려하는 효과적인 RL 신호인 Social Grounding Reward (SGR)를 도입했습니다. 이러한 participant-grounded supervision은 MLLMs가 primitive perception을 넘어 비언어적 단서로부터 사회적 상호작용에 대해 추론하도록 돕는 중요한 진전을 보여줍니다. 이 연구는 GRASP-Bench에서 성능을 향상시키고 관련 사회적 비디오 QA 벤치마크에서 zero-shot 성능을 유지함으로써, human-centered video understanding, assistive agents, collaborative robotics, 그리고 socially aware interface 분야에서 AI 시스템이 사람들과 더 효과적으로 상호작용할 수 있는 핵심 역량을 강화하는 데 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] From Runnable to Shippable: Multi-Agent Test-Driven Development for Generating Full-Stack Web Applications from Requirements
- 현재글 : [논문리뷰] GRASP: Learning to Ground Social Reasoning in Multi-Person Non-Verbal Interactions
- 다음글 [논문리뷰] Geometric Phase Transition Enables Extreme Hippocampal Memory Capacity
댓글