[논문리뷰] GEM: Generative Supervision Helps Embodied Intelligence
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ruowen Zhao, Bangguo Li, Zuyan Liu, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- GEM (Generative-supervised Embodied vision-language Model): 언어 모델링에 Depth Map 생성 과제를 통합하여 공간적, 물리적 인지 능력을 강화한 Embodied VLM 프레임워크입니다.
- GEM-VLA (Vision-Language-Action Model): GEM의 표현력을 로봇 제어 영역으로 확장하여, 멀티모달 관찰을 기반으로 연속적인 로봇 행동을 생성하는 모델입니다.
- GEM-4M: Grounding, Reasoning, Planning 데이터를 포함하는 400만 규모의 고품질 Embodied Pre-training 데이터셋입니다.
- Flow Matching Objective: 확산 모델(Diffusion Transformer)을 학습시키기 위한 목적 함수로, 노이즈 분포를 실제 Depth Map으로 변환하는 벡터 필드를 학습하는 데 사용됩니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 현재의 Embodied VLM들이 고수준의 언어적 추론에는 능숙하지만, 실제 물리 환경에서 로봇을 제어하기 위한 미세한 공간적 구조와 물리적 인지 능력이 결합되지 못하는 한계를 해결하고자 합니다. 기존의 방식은 2D 시각 정보에 의존하거나, 3D 물리적 정보를 후반부에 독립적으로 주입하여 전체적인 모델 아키텍처 내에서 정보가 충분히 융합되지 않는다는 문제점이 있습니다. 저자들은 이러한 물리적 제약과 추상적 의미론적 이해 사이의 간극을 좁히기 위해, 기초적인 Pre-training 단계에서부터 공간적 구조 정보를 명시적으로 학습시키는 접근 방식을 제안합니다. [Figure 1]
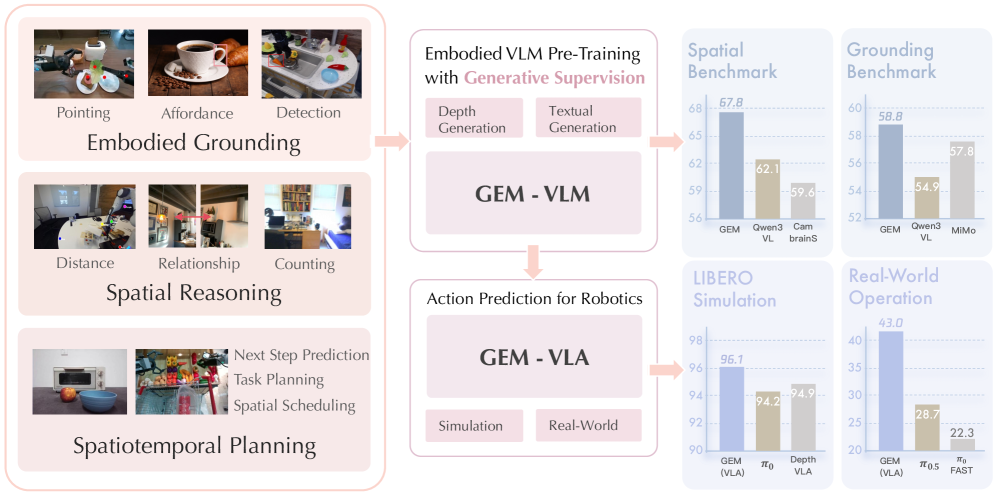
Figure 1 — GEM 모델 개요
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 VLM Backbone에 DiT(Diffusion Transformer) 기반의 Depth Generator를 결합한 아키텍처를 설계하여, Depth Map 예측을 고유한 생성 과제로 도입함으로써 구조적 정보를 학습하도록 했습니다 [Figure 2]. 모델 학습의 안정성을 위해 'Connector 초기화 → Depth Generator Warm-up → End-to-End Joint Training' 순으로 구성된 Progressive Training Recipe를 제안합니다. 정량적 실험 결과, GEM-8B 모델은 VSI-Bench에서 기존 모델 대비 큰 성능 향상을 보였으며, Gemini-3-Pro와 비교하여 특정 공간 추론 지표에서 10% 이상 우수한 결과를 기록했습니다 [Table 1], [Table 2]. 또한, LIBERO 벤치마크에서 96.1%의 평균 성공률을 달성하며 기존의 VLA 모델들을 압도하는 State-of-the-art 성능을 입증했습니다 [Table 3]. 아울러, 실제 로봇 조작 환경에서도 Deformable Object 조작 및 장기 계획 수립 과제에서 이전 베이스라인 대비 월등한 성과를 보였습니다 [Figure 3].
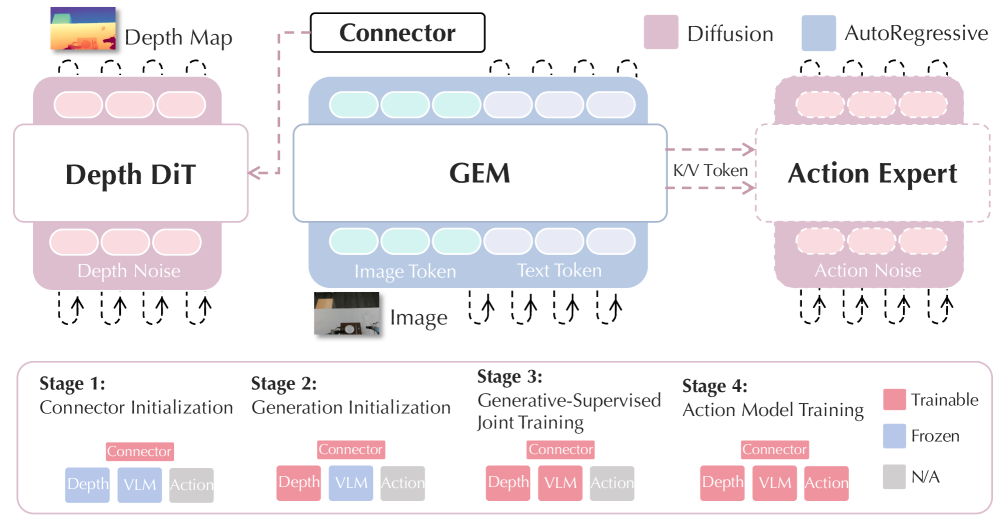
Figure 2 — GEM 아키텍처 상세
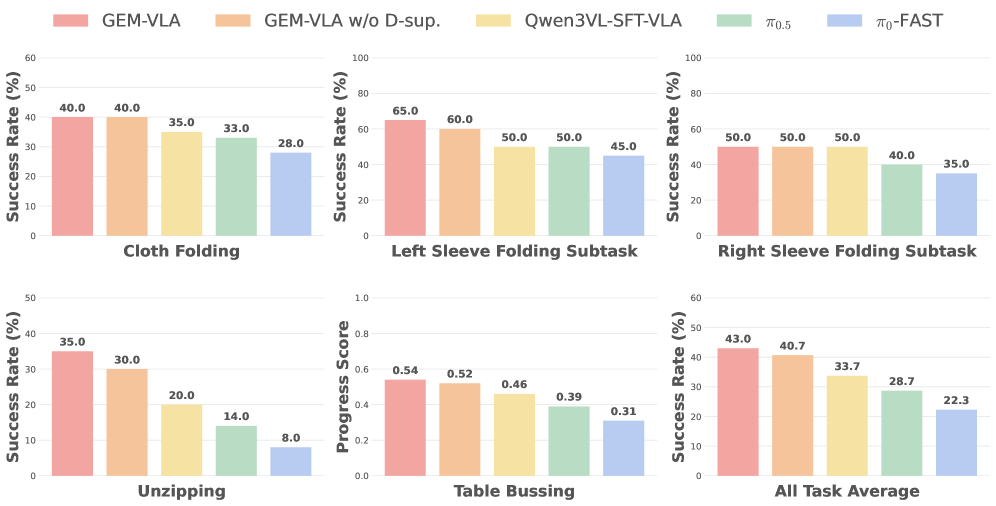
Figure 3 — 실제 로봇 작업 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 Generative Supervision을 통해 Embodied VLM의 공간 인지 및 물리적 추론 능력을 획기적으로 향상하는 GEM 프레임워크를 성공적으로 제안했습니다. 이 연구는 단순히 Semantic Reasoning에 그치지 않고, Depth Map 생성이라는 구조적 학습을 통해 물리적 세계를 이해하는 방식이 Embodied AI의 성능에 지대한 영향을 미친다는 것을 증명했습니다. 향후 이 연구는 로봇 학습을 위한 기초 모델(Foundation Model) 구축에 있어 시각적 구조 정보의 중요성을 강조하며, 더욱 복잡하고 일반화된 물리적 상호작용이 필요한 분야에 폭넓게 활용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
- [논문리뷰] VideoVLA: Video Generators Can Be Generalizable Robot Manipulators
- [논문리뷰] Qwen-Music Technical Report
Review 의 다른글
- 이전글 [논문리뷰] GE-Sim 2.0: A Roadmap Towards Comprehensive Closed-loop Video World Simulators for Robotic Manipulation
- 현재글 : [논문리뷰] GEM: Generative Supervision Helps Embodied Intelligence
- 다음글 [논문리뷰] Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
댓글