[논문리뷰] GenClaw: Code-Driven Agentic Image Generation
링크: 논문 PDF로 바로 열기
저자: Junyan Ye, Jun He, Zilong Huang, Dongzhi Jiang, Xuan Yang, Rui Chen, Weijia Li
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- GenClaw: 인간의 예술적 창작 과정(구상-스케치-채색)을 모방한 Code-Driven Agentic Image Generation 프레임워크입니다.
- Executable Canvas: LLM이 구조적 정보(객체 위치, 텍스트 레이아웃 등)를 시각화하기 위해 사용하는 중간 코드(SVG, HTML, Three.js 등)입니다.
- Cognitive Structuring Layer: 이미지 생성 전, VLM 및 외부 검색 도구를 활용하여 의도를 해석하고 지식을 보완하여 구조화된 레코드를 생성하는 단계입니다.
- Visual Generation and Review Layer: Executable Canvas를 기반으로 최종 픽셀 이미지를 렌더링하고, VLM을 통해 결과를 검증 및 수정하는 단계입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 end-to-end 방식의 image generation 모델이 겪는 제어 가능성 및 추론 능력의 한계를 해결하고자 합니다. 기존 모델들은 프롬프트 재작성을 통해 반복적인 '블랙박스' 식 시행착오를 거치며, 복잡한 공간 관계나 텍스트 레이아웃을 정밀하게 제어하는 데 실패하는 경우가 많습니다 [Figure 1]. 이러한 문제는 모델이 언어적 모호성 뒤에 숨어 실제 시각적 구조에 대한 직접적인 조작 권한을 갖지 못하기 때문에 발생합니다. 따라서 저자들은 LLM이 직접 코드를 사용하여 시각적 골격을 설계하는 새로운 '디지털 붓' 기반의 접근 방식을 제안합니다 [Figure 1].
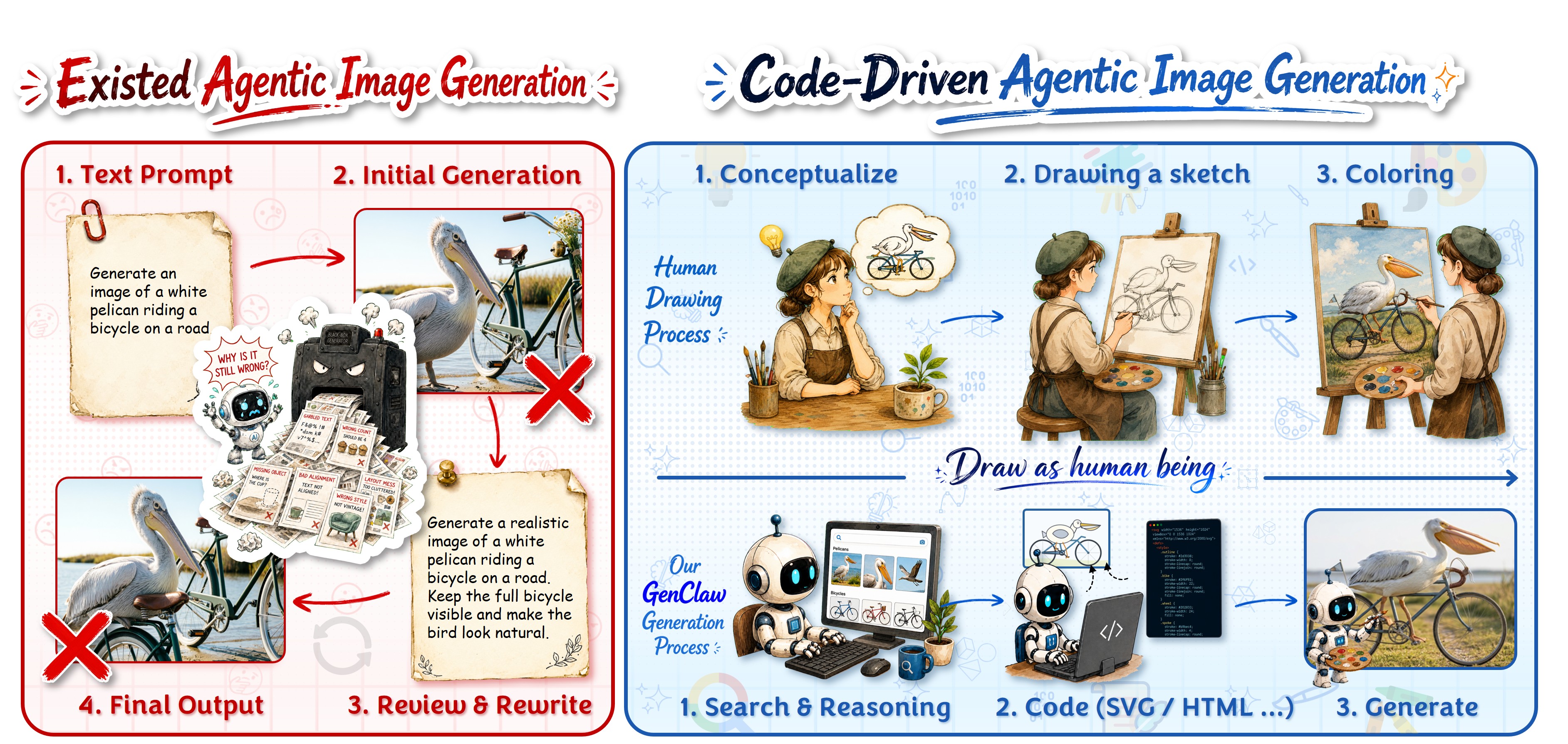
Figure 1 — GenClaw의 개념적 워크플로우
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 창작 프로세스를 Cognitive Structuring Layer, Executable Canvas Layer, Visual Generation and Review Layer의 3단계로 분리한 프레임워크를 제안합니다 [Figure 3]. Cognitive Structuring Layer에서는 검색 및 reasoning 도구를 활용해 복잡한 의도를 해석하고, Executable Canvas Layer에서 SVG나 HTML 등을 사용해 레이아웃과 3D 물리를 구조적으로 표현합니다. 마지막으로 Visual Generation and Review Layer에서 렌더링을 수행하여 최종 이미지를 생성합니다 [Figure 3]. 실험 결과, GenClaw는 GenEval++ 벤치마크에서 기존 모델 대비 압도적인 성능을 보였으며, 특히 Overall 스코어에서 0.878을 기록하여 GenAgent (0.725) 및 Mind-Brush (0.782)를 크게 상회했습니다 [Table 1]. 또한, ImgEdit 작업에서 정밀한 레이어 편집을 통해 비편집 영역의 훼손을 최소화하여 기존 모델들보다 높은 PSNR 및 SSIM 수치를 확보하였습니다 [Table 3]. 이러한 결과는 구조화된 스케치 방식이 복잡한 composition 및 텍스트 렌더링에서 훨씬 더 정확한 결과를 도출함을 증명합니다 [Figure 4].

Figure 3 — GenClaw의 3단계 아키텍처
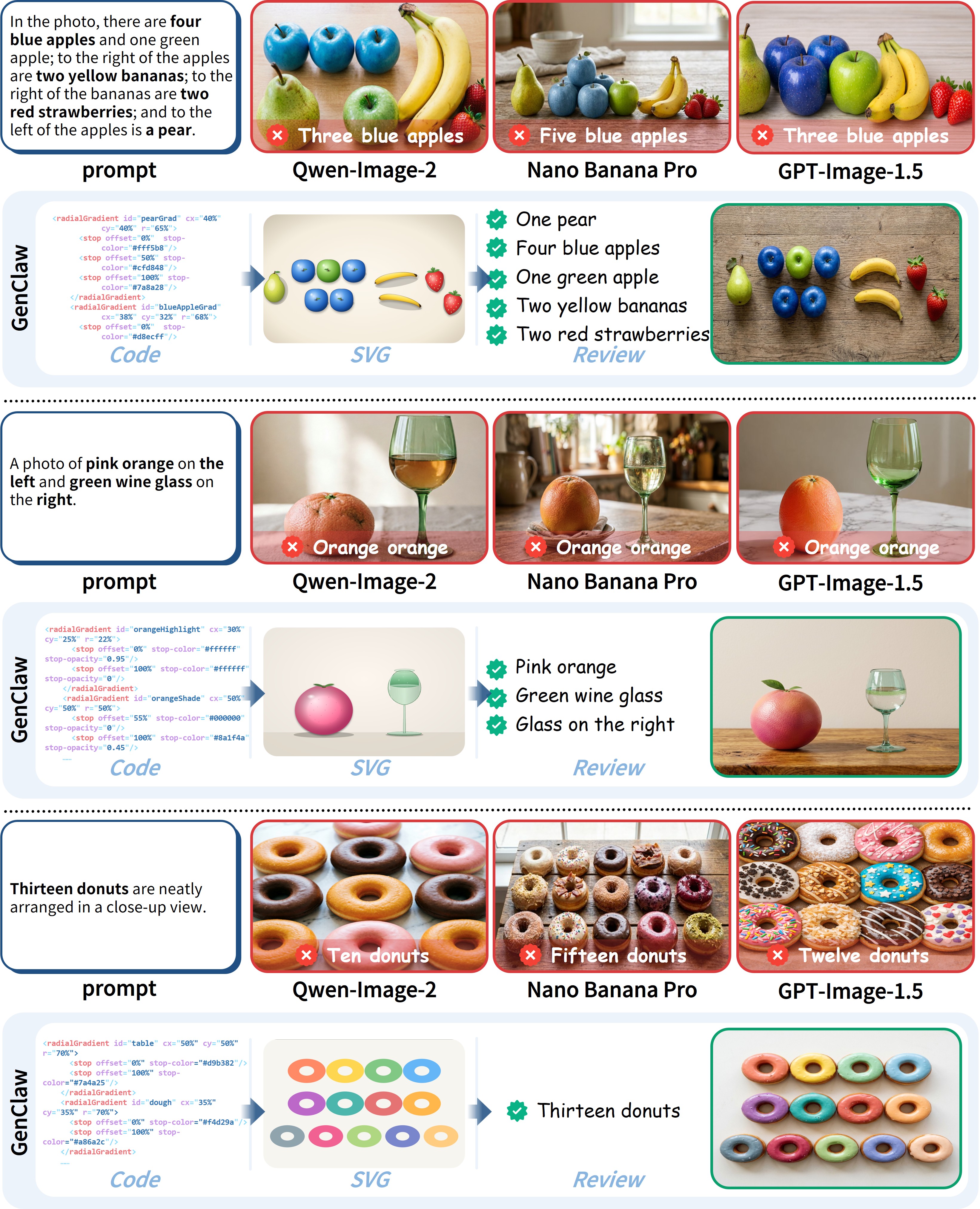
Figure 4 — 복잡한 구성의 정성적 결과 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 image generation 패러다임을 '단일 단계 블랙박스 생성'에서 '코드 기반의 단계적 창작'으로 전환함으로써 제어 가능성과 투명성을 비약적으로 향상시켰습니다. 제안된 GenClaw 시스템은 인간의 예술적 창작 과정을 모방하여 추론, 스케치, 채색의 과정을 체계적으로 분리하였으며, 이는 생성 과정에서의 오류를 개별 단계별로 추적하고 수정 가능하게 만듭니다. 본 연구는 차세대 agentic multimodal 시스템이 단순히 prompt를 최적화하는 수준을 넘어, 도구 사용과 코드 생성을 통해 시각적 논리성을 확립하는 방향으로 나아가야 함을 제시하며 관련 분야에 중요한 방법론적 기준을 마련하였습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] S1-Omni: A Unified Multimodal Reasoning Model for Scientific Understanding, Prediction, and Generation
- [논문리뷰] Accurate, Interdisciplinary and Transparent Structure-property Understanding with Deep Native Structural Reasoning
- [논문리뷰] FlexiSLM: A Dynamic and Controllable Frame Rate Spoken Language Model
- [논문리뷰] Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation
- [논문리뷰] ClinHallu: A Benchmark for Diagnosing Stage-Wise Hallucinations in Medical MLLM Reasoning
Review 의 다른글
- 이전글 [논문리뷰] EarlyTom: Early Token Compression Completes Fast Video Understanding
- 현재글 : [논문리뷰] GenClaw: Code-Driven Agentic Image Generation
- 다음글 [논문리뷰] Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence
댓글