[논문리뷰] Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence
링크: 논문 PDF로 바로 열기
메타데이터
저자: Artur Jesslen, Olaf Dünkel, Adam Kortylewski, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Semantic Correspondence: 서로 다른 이미지에서 의미적으로 일치하는 객체 부분을 식별하고 매칭하는 컴퓨터 비전 작업입니다.
- PartField: 3D 형상의 각 정점에서 기하학적 및 부품 구조를 인코딩한 descriptor로, 2D 기반 모델이 구분하기 어려운 대칭적 부품이나 반복되는 부품을 구별하는 데 사용됩니다.
- Render-and-Compare: 3D 모델의 투영 결과물(silhouette 등)과 관찰된 이미지 간의 차이를 최소화하여 초기 3D 메쉬의 포즈와 규모를 정밀하게 보정하는 최적화 기법입니다.
- Geodesic Filtering: 3D 메쉬 표면에서의 최단 거리(geodesic distance)를 활용하여, 이미지 수준에서 생성된 매칭 후보가 기하학적으로 일치하는지 검증하고 신뢰도가 낮은 매칭을 제거하는 필터링 방식입니다.
- Adapter: 훈련된 Foundation Model(예: DINOv2, Stable Diffusion)의 파라미터를 고정(frozen)한 상태에서, downstream 작업인 semantic correspondence를 위해 추가로 학습되는 경량 모델입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 2D 기반 Foundation Model들이 가지는 3D 인지 능력 부족으로 인한 semantic correspondence의 구조적 오류를 해결하고자 합니다. 기존의 DINOv2나 Stable Diffusion 같은 모델은 2D 이미지 데이터로 학습되어 대칭적인 객체(예: 자동차의 좌우)나 반복적인 부품(예: 의자 다리)을 매칭할 때 구조적 혼동(confusion)을 겪는 한계가 있습니다 [Figure 1]. 이러한 문제를 해결하려는 기존 연구들은 수동 pose annotation이나 조악한 구(spherical) 기반의 기하학적 프록시에 의존하여 인스턴스 수준의 상세한 3D 구조를 활용하지 못했습니다. 이에 저자들은 수동 주석 없이 인스턴스 고유의 3D 구조를 자동으로 추출하고 이를 통해 correspondence 학습을 가이드하는 3D-aware post-training framework를 제안합니다.

Figure 1 — 3D 기반 매칭 필터링 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 3D Foundation Model인 SAM3D를 활용해 단일 이미지에서 객체 메쉬를 재구성하고, 이를 render-and-compare 기법으로 정교화하여 3D-aware한 PartField descriptor를 이미지 평면에 투영하는 방법론을 제시합니다 [Figure 2]. 투영된 PartField features는 DINOv2 및 Stable Diffusion features와 결합되어, 매칭 후보군 생성 시 대칭성 및 반복 부품 오류를 획기적으로 줄여줍니다 [Figure 3]. 생성된 매칭 후보들은 재구성된 메쉬 표면 위에서의 Geodesic Filtering을 거쳐 최종적으로 신뢰할 수 있는 pseudo-label로 변환되며, 이를 통해 경량 Adapter를 학습시킵니다. 실험 결과, SPair-71k 벤치마크에서 기존의 비지도 및 약지도 학습 방법론들을 능가하는 73.0 PCK@0.1을 달성하였습니다. 특히, 기하학적 대칭성이 중요한 SPair-Geo-Aware 서브셋에서 타 방법론 대비 월등한 성능 향상을 보이며, 별도의 수동 pose annotation 없이도 정밀한 correspondence 생성이 가능함을 입증하였습니다 [Table 1].
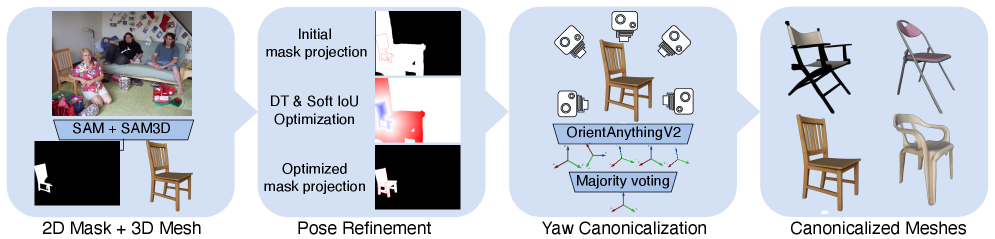
Figure 2 — 3D 객체 재구성 파이프라인
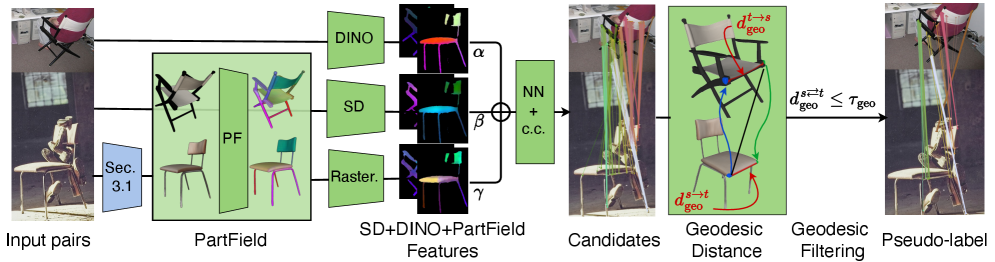
Figure 3 — Pseudo-label 생성 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 instance-specific 3D 구조를 자동으로 활용함으로써 semantic correspondence의 정확도를 크게 향상시킨 새로운 3D-aware post-training 프레임워크를 정립하였습니다. 본 연구는 3D Foundation Model이 2D 비전 작업의 기하학적 교사(geometric teacher)로서 기능할 수 있음을 보여주며, 향후 3D 정보가 부족한 다양한 2D 컴퓨터 비전 작업에 3D 기반의 사전 지식(prior)을 효과적으로 이식하는 중요한 이정표가 될 것으로 기대됩니다. 또한 수동 레이블링에 대한 의존도를 낮춤으로써 향후 다양한 객체 카테고리로의 확장 가능성을 제시하였습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Vision Pretraining for Dense Spatial Perception
- [논문리뷰] Speaker-Disentangled Chunk-Wise Regression for Syllabic Tokenization
- [논문리뷰] Speaker-Aware Temporal Aggregation Strategies on Segment Representations for Depression Detection in Dyadic Interaction: A Benchmark Study
- [논문리뷰] AGE: Adaptive-masking for Graph Embedding in Graph Retrieval-Augmented Generation
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
Review 의 다른글
- 이전글 [논문리뷰] GenClaw: Code-Driven Agentic Image Generation
- 현재글 : [논문리뷰] Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence
- 다음글 [논문리뷰] How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
댓글