[논문리뷰] How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziwen Xu, Haiwen Hong, Linsong Yu, Benglei Cui, Longtao Huang, Hui Xue, Ningyu Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Parametric Memory: LLM의 가중치(
Parameters) 내부에 정보를 직접 저장하는 방식으로,LoRA와 같은 모듈을 통해 지식을 고정하는 메커니즘을 의미합니다. - Parametric Memory Law: 학습된
Parameters(LoRA rank)와 시퀀스 길이(Sequence Length)에 따른 손실 감소량(Loss Reduction) 사이의 거듭제곱 법칙(Power Law) 관계를 정량화한 법칙입니다. - Deterministic Phase Transition:
Greedy Decoding환경에서Target Token의 확률(Probability)이 특정 임계값(p > 0.5)을 넘어서는 순간, 모델이 해당 토큰을 확정적으로 기억하게 되는 전이 지점을 의미합니다. - MemFT (Memorization-oriented Fine-Tuning): 모델의 전체 학습 예산을 균등하게 분배하는 대신, 임계값보다 낮은 확률을 가진 'Stubborn Token'에 집중하여 최적화하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LoRA를 활용한 Parametric Memory의 용량 한계와 내부 기억 메커니즘을 정량적으로 규명하는 것을 핵심 문제로 다룹니다 [Figure 1]. 기존 연구들은 LoRA의 성능을 주로 다운스트림 태스크의 기능적 평가로만 측정하여, 순수한 정보 암기 성능이나 내부 용량의 정량적 한계를 명확히 설명하지 못한다는 한계가 있었습니다. 특히, 모델이 암기한 지식을 재현할 때 단순히 평균적인 손실 감소가 정확한 기억 보존을 보장하지 않는다는 점이 중요하게 고려되었습니다. 저자들은 이러한 한계를 극복하기 위해 LoRA를 제어 가능한 용량 프로브(Probe)로 활용하여 암기 역학의 근본적인 원리를 탐구하고자 합니다.
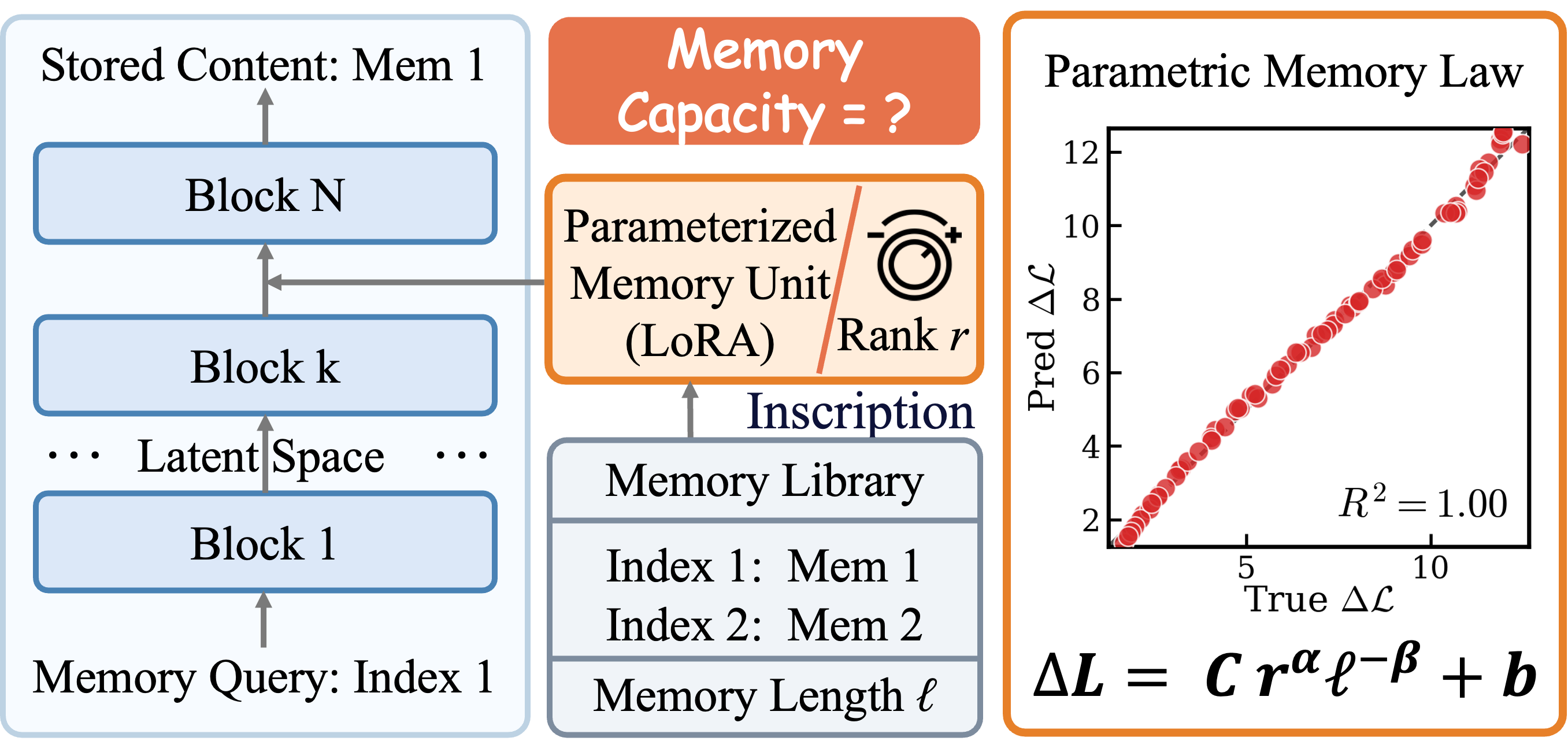
Figure 1 — LoRA 기반 메모리 장치 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Parametric Memory Law를 정립하고 이를 바탕으로 한 MemFT 최적화 전략을 제안합니다 [Figure 2]. 저자들은 거대한 실험 데이터셋을 통해 손실 감소량(Δℒ)이 rank와 시퀀스 길이의 거듭제곱 함수로 표현됨을 입증하였으며, R² > 0.98의 높은 적합도를 보였습니다 [Table 1]. 또한, 토큰 레벨의 확률 분석을 통해 p > 0.5가 성공적인 암기를 위한 확정적 조건임을 규명하였고, ℒ_crit = ln(2) ≈ 0.693을 전이 임계값으로 정의하였습니다 [Figure 3]. 이러한 통찰을 바탕으로 제안된 MemFT는 기존 SFT 대비 암기 충실도와 효율성을 크게 향상시켰습니다 [Table 2]. 특히, 어려운 'Stubborn Token'에 학습 가중치를 재분배함으로써, 동일한 파라미터 예산 내에서 암기 정확도를 크게 개선하는 성과를 거두었습니다.
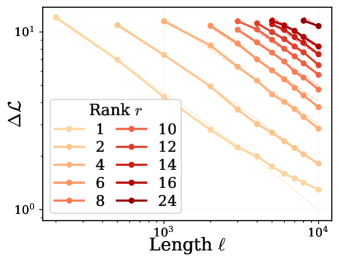
Figure 2 — 메모리 법칙의 실증적 검증
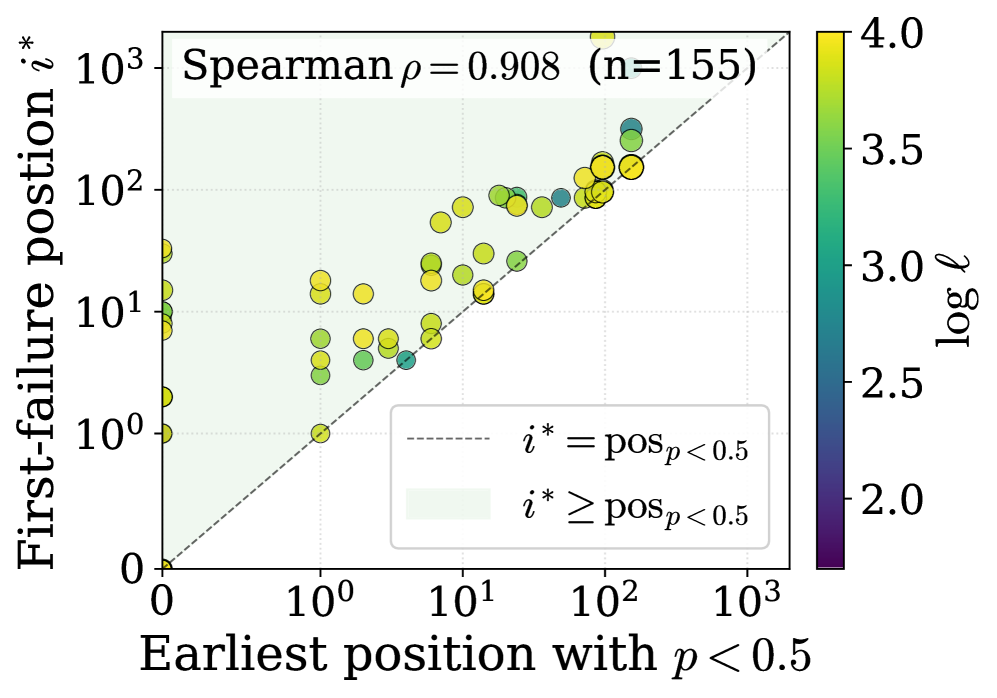
Figure 3 — 디코딩 실패와 토큰 확률의 관계
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LoRA를 기반으로 Parametric Memory의 용량과 그 역학을 지배하는 물리적 법칙을 최초로 정립하였습니다. 이 연구는 단순히 지식을 주입하는 것을 넘어, 모델이 언제 그리고 왜 특정 정보를 기억하는지에 대한 미시적인 메커니즘을 밝혀냄으로써 LLM의 지식 통합 및 유지보수 연구에 중대한 기여를 합니다. 향후 본 연구에서 제시된 방법론은 실질적인 보안 지식 암기나 운영 체제 수준의 지식 업데이트 시스템 구축에 중요한 학술적·산업적 근거를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From RGB Generation to Dense Field Readout: Pixel-Space Dense Prediction with Text-to-Image Models
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
Review 의 다른글
- 이전글 [논문리뷰] Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence
- 현재글 : [논문리뷰] How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
- 다음글 [논문리뷰] Is Position Bias in Dense Retrievers Built In-or Learned from Data?
댓글