[논문리뷰] Is Position Bias in Dense Retrievers Built In-or Learned from Data?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Daegon Yu, SeungYoon Han, Woomyoung Park
1. Key Terms & Definitions (핵심 용어 및 정의)
- Position Bias: 문서 내에서 쿼리 관련 정보가 위치한 장소(시작, 중간, 끝)에 따라 retrieval 성능이 달라지는 체계적인 편향 현상.
- Dense Retrievers: 문서를 벡터 공간에 임베딩하여 쿼리와의 유사도를 계산하는 모델로, 본 논문에서는 이들이 가지는 primacy bias 문제를 다룸.
- Position-Controlled Data Construction: 쿼리 관련 증거가 문서의 특정 위치(시작/중간/끝)에만 존재하도록 제어하여 생성한 데이터셋 구축 파이프라인.
- PSI (Position Sensitivity Index): retrieval 성능이 증거 위치에 따라 얼마나 민감하게 변하는지를 측정하는 지표로, 0에 가까울수록 위치에 대해 강건함(robust).
- InfoNCE: bi-encoder 학습에 사용되는 대조 학습(contrastive learning) 손실 함수.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Dense Retrievers가 문서 내 정보 위치에 따라 성능이 크게 변하는 Position Bias 문제를 해결하고자 한다. 기존 연구들은 이러한 편향의 원인을 모델의 아키텍처나 사전 학습(pretraining) 방식에서 찾으려 했으나, 이들만으로는 체계적인 편향 방향을 완벽히 설명하지 못한다. 저자들은 미세 조정(fine-tuning) 데이터의 위치 분포 자체가 학습된 편향을 결정하는 핵심 요인이라는 가설을 세우고 이를 직접적으로 검증하고자 한다. 이는 기존의 관찰 중심 연구를 넘어, 학습 데이터를 의도적으로 통제하여 편향을 완화할 수 있는지를 확인하는 중요한 시도이다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 쿼리 관련 증거의 위치가 제어된 데이터셋을 구축하기 위해 3단계(문서 binning, 위치 특정 쿼리 생성, Multi-Reranker 검증) 파이프라인을 설계하였다 [Figure 1]. 이 데이터셋을 사용하여 인코더 및 디코더 아키텍처가 서로 다른 8개의 모델을 학습시키고 그 결과를 분석하였다. 실험 결과, 학습 데이터의 위치 분포(begin, middle, end)가 모델의 retrieval 선호도를 정확히 결정하는 것으로 나타났으며, 이는 아키텍처와 관계없이 일관되게 관찰되었다 [Figure 1]. Position-balanced training을 적용한 결과, 모델의 PSI가 기존의 편향된 모델 대비 57–87% 감소하였으며, 동시에 표준 Retrieval Benchmark(BEIR 등)에서 경쟁력 있는 성능을 유지하였다 [Table 3]. 또한 표현 수준(representation-level) 분석을 통해, fine-tuning이 문서 임베딩 자체를 학습 데이터의 증거 위치 선호도에 맞게 재구성함을 확인하였다 [Figure 3].
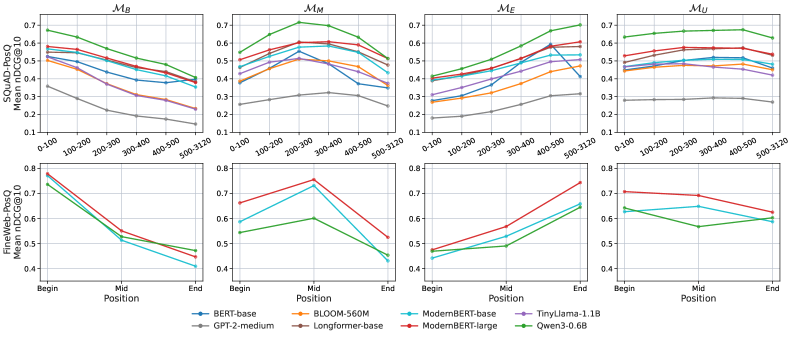
Figure 1 — 학습 데이터 분포에 따른 nDCG@10 변화
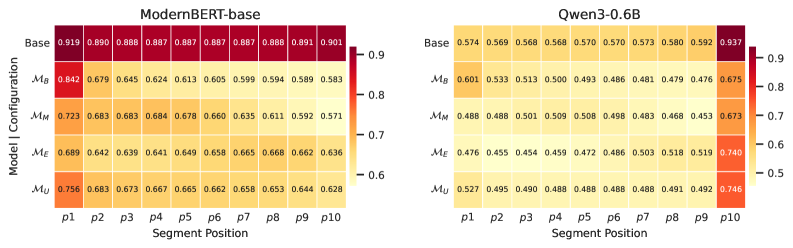
Figure 3 — 문서 위치에 따른 임베딩 유사도 변화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Dense Retrievers의 Position Bias가 모델 아키텍처 못지않게 학습 데이터의 위치 분포에 의해 크게 좌우된다는 점을 명확히 규명하였다. 특히, 데이터셋의 위치 분포를 균형 있게 구성하는 것만으로도 모델의 위치 민감도를 효과적으로 낮출 수 있음을 보여주었다. 이러한 연구 결과는 대규모 언어 모델 기반의 검색 시스템이나 RAG 파이프라인 구축 시, 데이터 큐레이션(data curation)이 모델의 견고함(robustness)을 높이는 실용적이고 핵심적인 전략이 될 수 있음을 시사한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Motion Attribution for Video Generation
- [논문리뷰] Boogu-Image-0.1: Boosting Open-Source Unified Multimodal Understanding and Generation
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Light-Omni: Reflex over Reasoning in Agentic Video Understanding with Long-Term Memory
Review 의 다른글
- 이전글 [논문리뷰] How LoRA Remembers? A Parametric Memory Law for LLM Finetuning
- 현재글 : [논문리뷰] Is Position Bias in Dense Retrievers Built In-or Learned from Data?
- 다음글 [논문리뷰] LaRA: Layer-wise Representation Analysis for Detecting Data Contamination in RL Post-Training
댓글