[논문리뷰] LaRA: Layer-wise Representation Analysis for Detecting Data Contamination in RL Post-Training
링크: 논문 PDF로 바로 열기
저자: Minju Gwak, Minseo Kwak, Dongseok Lee, Guijin Son, Alan Ritter, Jaehyung Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- RL Post-Training: 대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위해 보상 기반의 강화 학습을 적용하는 파이프라인.
- Data Contamination: RL 학습 데이터 내에 벤치마크나 평가용 샘플이 포함되어 모델이 이를 암기하거나 과적합(Overfitting)하는 현상.
- RSM (Representation Shift Magnitude): 입력 데이터에서 핵심 정보를 제거했을 때 발생하는 모델의 내부 표현(Hidden representation) 변화량을 측정한 지표.
- DC (Directional Collapse): 데이터 변경에 따른 표현 변화가 특정 방향으로 편향되는 정도를 측정한 지표로, 표현의 다양성 상실을 나타냄.
- RSI (Representation Stability Index): 의미를 보존하는 변형(Paraphrasing)에도 불구하고 모델의 표현이 얼마나 일관되게 유지되는지를 나타내는 지표.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RL post-training 과정에서 발생하는 data contamination이 모델의 평가 신뢰성과 일반화 성능을 저해한다는 문제를 지적한다. 기존의 탐지 방식은 주로 token likelihood나 entropy 등 출력(Output-level) 신호에 의존해왔다. 하지만 RL은 개별 토큰이 아닌 전체 추론 궤적에 대한 보상을 최적화하므로, 이러한 출력 통계는 비신뢰적이다 [Figure 1]. 따라서 저자들은 출력 데이터의 보정 문제나 목표 최적화 불일치를 극복하기 위해, 모델 내부의 기하학적 구조를 직접 분석하는 representation-level 접근 방식을 제안한다.
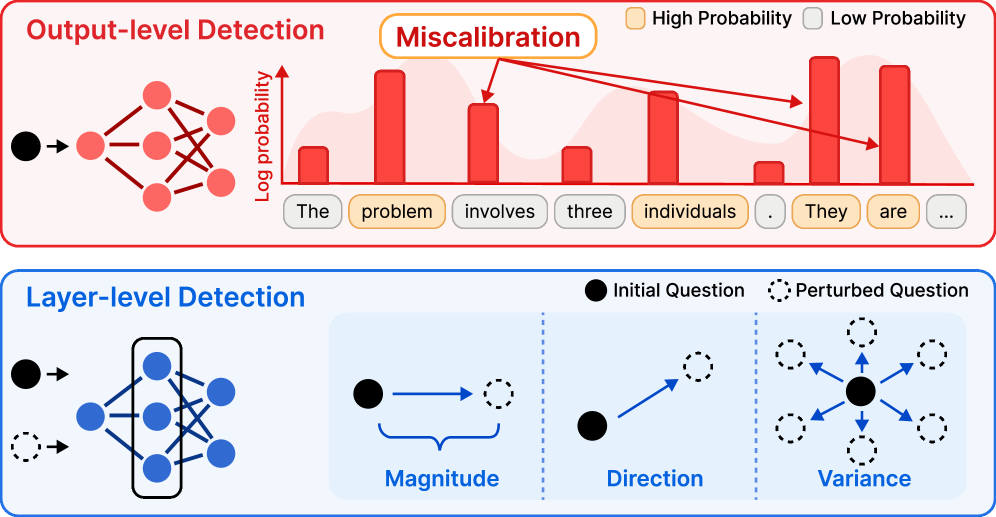
Figure 1 — 출력 수준과 표현 수준 탐지의 차이
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 LaRA (Layer-wise Representation Analysis) 프레임워크는 데이터 변형에 따른 내부 표현의 기하학적 변화를 추적하여 오염 여부를 판별한다 [Figure 2]. 핵심 방법론은 입력 샘플에 대해 핵심 정보를 제거(Blanking)하거나 유사한 표현으로 변형(Paraphrasing)한 뒤, 각 transformer layer별로 RSM, DC, RSI 세 가지 지표를 추출하는 것이다 [Figure 3]. 이를 표준화하여 결합한 점수 **$S_{LaRA}$**를 통해 오염된 샘플을 탐지한다 [Table 1]. 실험 결과, 제안 모델은 기존 output-level 베이스라인 대비 AUC와 TPR@FPR=5%에서 월등한 성능을 보였다. 특히 Eurus와 LIMR 모델 대상 실험에서 **$S_{LaRA}$**는 오염된 샘플이 학습 과정에서 더욱 명확한 기하학적 이상을 나타냄을 증명했으며, 출력 기반 방식인 SC (Self-Critique)와 결합 시 탐지 성능이 더욱 향상되었다 [Table 2].
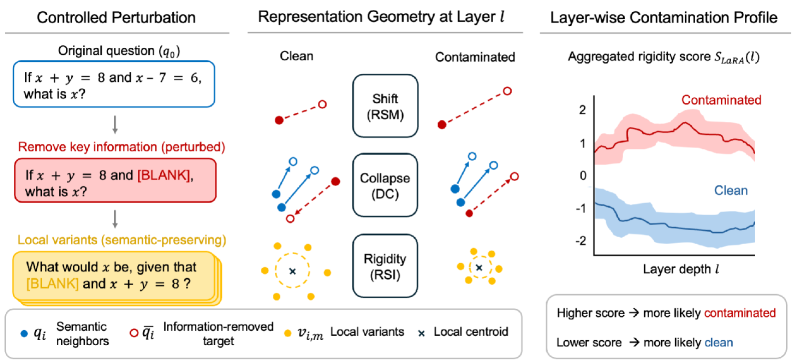
Figure 2 — LaRA 프레임워크 전체 개요
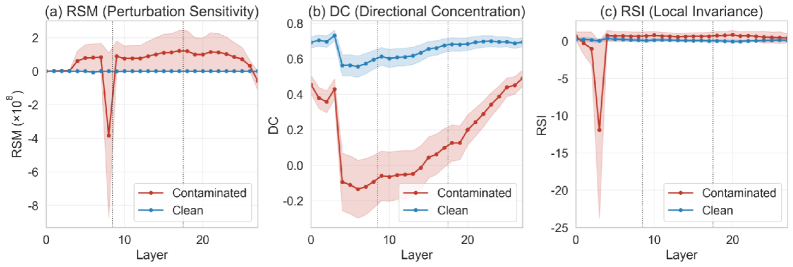
Figure 3 — 오염 모델의 층별 표현 기하학 패턴
4. Conclusion & Impact (결론 및 시사점)
본 논문은 RL post-training 모델의 오염 탐지를 위해 내부 표현의 기하학적 분석이라는 새로운 패러다임을 제시했다. 제안된 LaRA는 출력 기반 지표의 한계를 보완하며, 모델 내부의 은밀한 암기 흔적을 효과적으로 잡아낸다. 이 연구는 LLM 평가의 투명성을 높이고, 오염된 데이터가 모델 성능 보고에 미치는 왜곡을 방지함으로써 학계와 산업계의 모델 신뢰성 향상에 크게 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] WanSong v1.0 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] Is Position Bias in Dense Retrievers Built In-or Learned from Data?
- 현재글 : [논문리뷰] LaRA: Layer-wise Representation Analysis for Detecting Data Contamination in RL Post-Training
- 다음글 [논문리뷰] Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
댓글