[논문리뷰] GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
링크: 논문 PDF로 바로 열기
저자: Xiaohang Tang, Keyue Jiang, Che Liu, Qifang Zhao, Xiaoxiao Xu, Sangwoong Yoon, Ilija Bogunovic
1. Key Terms & Definitions (핵심 용어 및 정의)
- dLLMs (Diffusion Large Language Models): 비자기회귀적(non-autoregressive) 방식으로 토큰을 생성하며, 병렬적인 디코딩과 효율적인 토큰 의존성 학습을 가능하게 하는 생성 모델입니다.
- TIM (Training-Inference Mismatch): 학습 시 사용되는 ELBO 기반의 likelihood 대용값과 추론 시 사용되는 실제 샘플링 프로세스 간의 통계적 차이로 인해 발생하는 성능 저하 및 훈련 불안정성 문제를 의미합니다.
- GDSD (Guided Denoiser Self-Distillation): 본 논문에서 제안하는 프레임워크로, 강화학습을 likelihood 기반의 중요도 샘플링(importance sampling) 대신 에너지 유도(energy-guided) 교사 모델로부터의 직접적인 Logit Matching 기반 자기 증류(self-distillation)로 재정의하여 TIM 문제를 회피합니다.
- TLC (Token-level Logit Centralization): 모델의 로그 확률에서 토큰별 평균을 차감하여 전역적인 상수 오프셋을 제거함으로써, 정규화 상수(partition function)를 직접 계산할 필요 없이 효율적으로 Logit Matching을 수행하게 하는 정규화 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
dLLMs는 기존의 Autoregressive Models(ARMs) 대비 효율적인 생성 성능을 제공하지만, 최적의 성능을 위해 필요한 강화학습(RL) 적용 시 정책 likelihood가 계산 불가능하다는 핵심적인 난관에 직면합니다. 기존 연구들은 ELBO(Evidence Lower Bound)를 likelihood surrogate로 사용하여 이 문제를 해결하고자 했으나, 이는 학습 과정과 실제 추론 분포 간의 구조적 차이인 TIM을 유발합니다 [Figure 1]. 이러한 학습 불일치는 중요도 샘플링 비율의 편향을 초래하여 모델 성능을 저하시키거나 최악의 경우 훈련 붕괴(training collapse)를 일으킵니다. 따라서 본 연구는 ELBO라는 우회적인 경로를 탈피하고, likelihood-free 방식으로 RL 문제를 해결할 수 있는 보다 근본적이고 안정적인 접근 방식을 제안합니다.
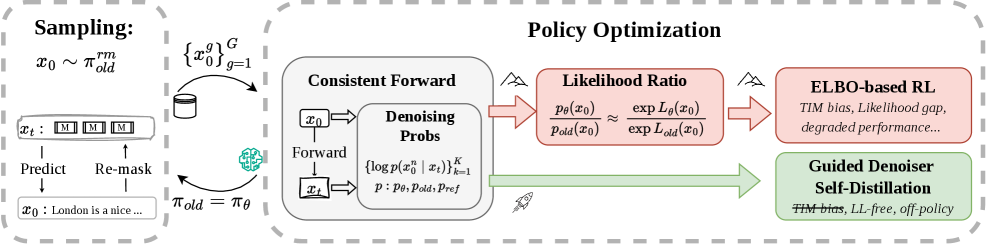
Figure 1 — GDSD 프레임워크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 강화학습을 에너지 유도 denoiser를 교사 모델로 활용하는 자기 증류(self-distillation) 문제로 재정의합니다. 구체적으로, 역방향 KL 정규화된 RL의 최적 정책이 에너지 유도 분포를 가진다는 점에 착안하여, 현재 모델의 denoiser가 이 교사 모델의 Logit과 일치하도록 학습시키는 GDSD 프레임워크를 제안합니다 [Figure 1]. 제안된 GDSD는 정규화 상수(partition function)를 제거하기 위해 TLC 기법을 적용하여, 실질적인 연산 부담을 최소화하면서도 모델이 높은 보상을 받는 시퀀스에 집중하도록 효과적으로 유도합니다. 실험 결과, GDSD는 Dream-7B 기반 모델에서 기존 ELBO 기반의 SOTA 방법론 대비 최대 +19.6%의 테스트 정확도 향상을 기록했습니다 [Table 1]. 또한, LLaDA-8B 모델을 사용한 다양한 벤치마크(Planning, Math, Coding)에서도 정량적으로 일관된 성능 우위를 보였으며, 특히 훈련 과정에서 보상 동역학(reward dynamics)이 기존 방식보다 훨씬 안정적으로 수렴함을 입증했습니다 [Figure 2].
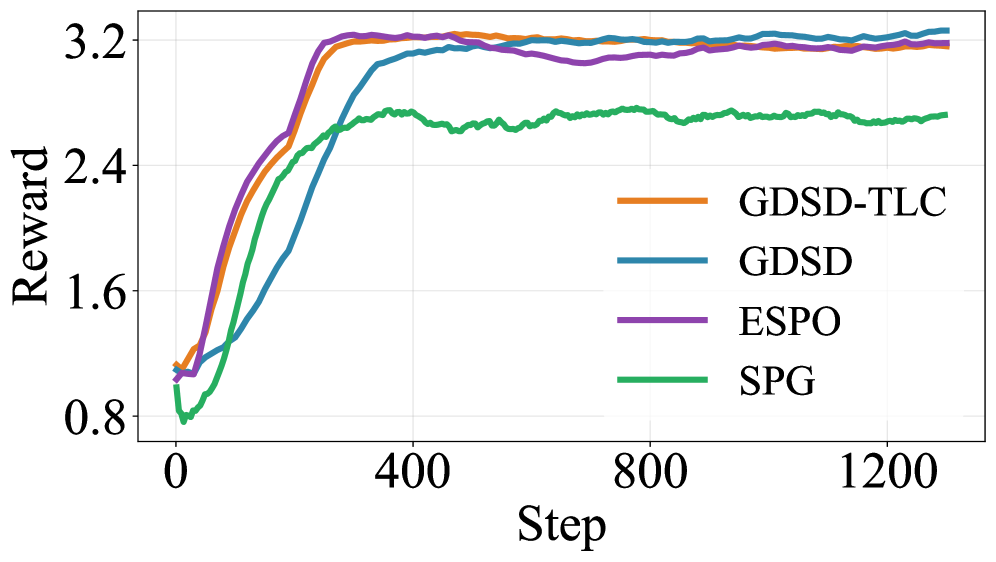
Figure 2 — 훈련 보상 안정성 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 dLLMs의 학습에서 ELBO를 likelihood surrogate로 사용하는 방식이 본질적인 TIM 문제를 유발함을 지적하고, 이를 해결하기 위한 GDSD를 제안했습니다. GDSD는 RL을 likelihood-free 자기 증류 문제로 전환함으로써 훈련의 효율성과 안정성을 크게 높였습니다. 이러한 연구 결과는 dLLMs의 post-training 과정에서 likelihood 추정의 제약을 벗어나 더 견고한 정렬(alignment)이 가능함을 시사합니다. 향후 본 방법론은 컴퓨팅 비용 절감과 학습 안정성을 토대로 reasoning-oriented 모델 개발 및 배포에 있어 중요한 기반 기술로 활용될 것으로 기대됩니다.
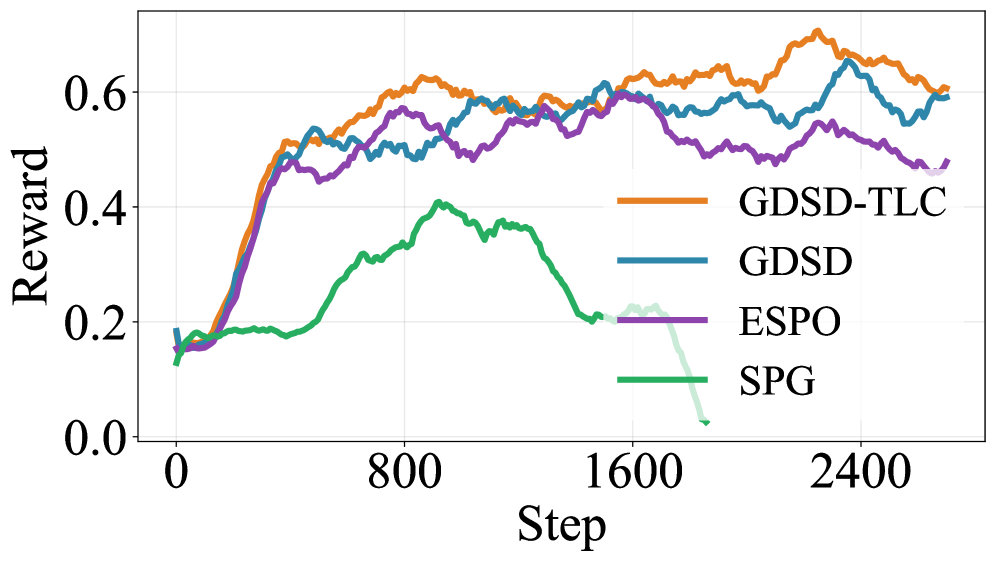
Figure 3 — TLC 및 guidance 계수 영향
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- [논문리뷰] HINT-SD: Targeted Hindsight Self-Distillation for Long-Horizon Agents
- [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Review 의 다른글
- 이전글 [논문리뷰] Function2Scene: 3D Indoor Scene Layout from Functional Specifications
- 현재글 : [논문리뷰] GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
- 다음글 [논문리뷰] GGT-100K: Generative Ground Truth for Generalizable Real-World Image Restoration
댓글