[논문리뷰] αDepth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiang Zhang, Yang Zhang, Lukas Mehl, Karlis Martins Briedis, Markus Gross, Christopher Schroers
1. Key Terms & Definitions (핵심 용어 및 정의)
- αDepth: Soft boundary(머리카락, defocus blur 등)에서 발생하는 색상 혼합 및 깊이 모호성을 해결하기 위해 foreground/background의 색상과 깊이를 계층적으로 분해하는 새로운 표현 방식입니다.
- Circular Alpha Representation (CAR): 글로벌 foreground 추출 방식의 한계를 극복하기 위해, Alpha를 삼각함수 공간으로 투영하여 로컬 경계에서의 변화를 연속적으로 모델링하는 기법입니다.
- Depth Ambiguity: Soft boundary 픽셀이 foreground와 background의 색상을 동시에 포함함에 따라 발생하는 깊이 값의 혼선으로, 기존 단일 레이어 depth 모델의 주요 한계점입니다.
- Alpha Valley: 여러 객체가 겹치는 경계에서 기존 vanilla alpha 표현 방식이 불연속적인 값을 생성하여 발생하는 추정 오류 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 모노큘러 이미지에서 고품질의 스테레오 영상을 생성할 때 발생하는 soft boundary 처리 문제를 해결합니다. 기존의 depth 추정 모델은 픽셀당 하나의 깊이 값만 할당하므로, 경계면에서의 색상 혼합으로 인해 발생하는 깊이 모호성을 처리하지 못해 왜곡된 3D 구조를 생성합니다 [Figure 2]. 또한 기존의 matting 기법들은 trimap과 같은 사용자 개입(manual guidance)이 필수적이거나 특정 객체에 국한되어, 복잡한 다중 객체 장면을 자동화된 스테레오 변환 파이프라인에 적용하기에는 비효율적입니다 [Figure 2]. 따라서 본 연구는 사용자 개입 없이 장면 전체의 경계면을 계층적으로 분해할 수 있는 모델링 방식이 필요하다는 점을 명시합니다.
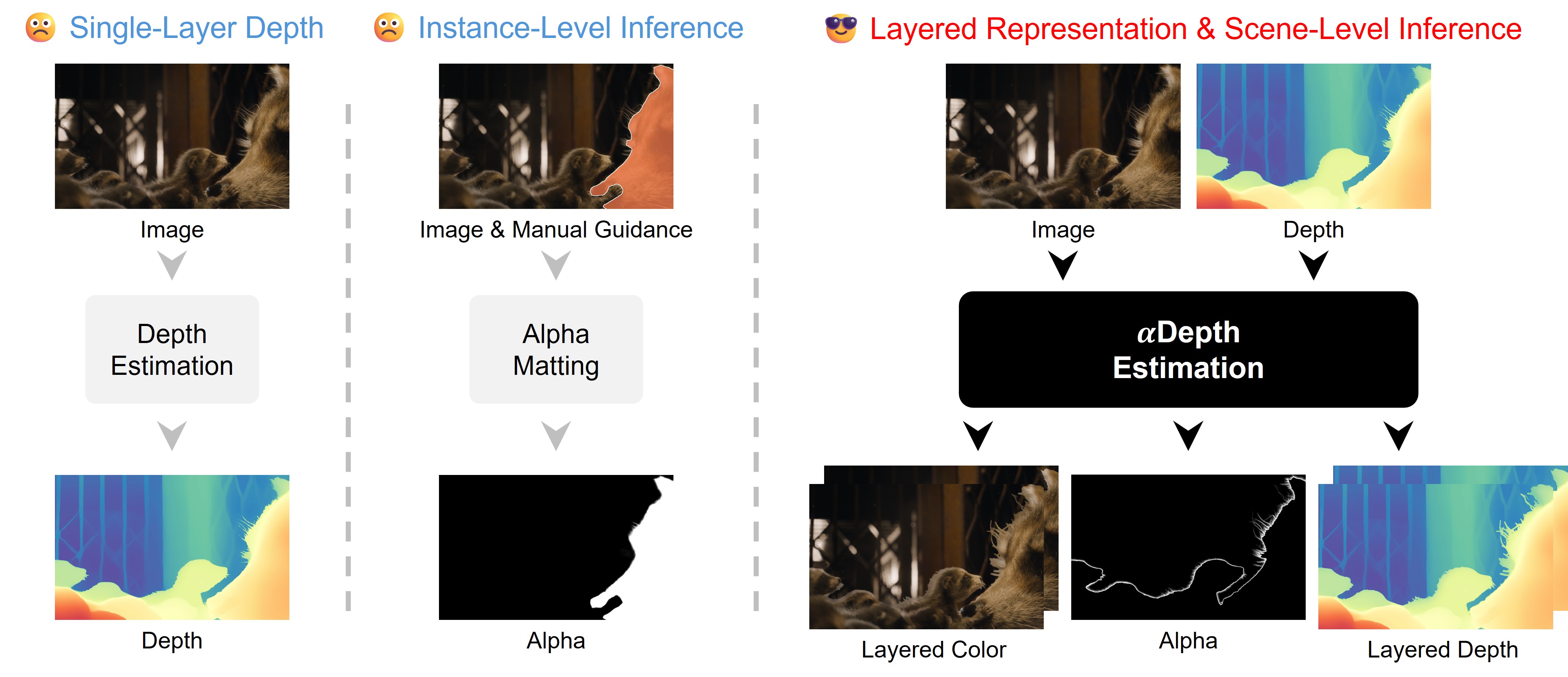
Figure 2 — 기존 패러다임과의 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 αDepth라는 계층적 표현 프레임워크를 제안하며, 핵심 방법론으로 CAR(Circular Alpha Representation)을 도입합니다 [Figure 4]. CAR은 alpha 맵을 $sin(2\pi\alpha)$와 $cos(2\pi\alpha)$의 삼각함수 공간으로 매핑하여 배경과 전경의 불연속성을 연속적인 매니폴드로 변환함으로써, 다중 객체 경계에서도 정확한 alpha 추정을 가능하게 합니다 [Figure 5]. 이후 Dual-path encoder를 통해 의미론적 맥락과 구조적 세부 정보를 추출하고, 다중 브랜치 디코더를 통해 foreground/background의 색상과 깊이를 계층적으로 예측합니다 [Figure 4]. 실험 결과, αDepth는 기존의 단일 레이어 깊이 기반 스테레오 변환 대비 background bleeding 현상과 구조적 왜곡을 효과적으로 제거함을 입증했습니다 [Figure 3]. 정량적 평가에서 αDepth는 다양한 환경(Mono2Stereo, Marvel-10K 등)에서 SOTA 성능을 달성하며, 사용자 개입 없는 single-pass 추론 효율성을 확보했습니다.
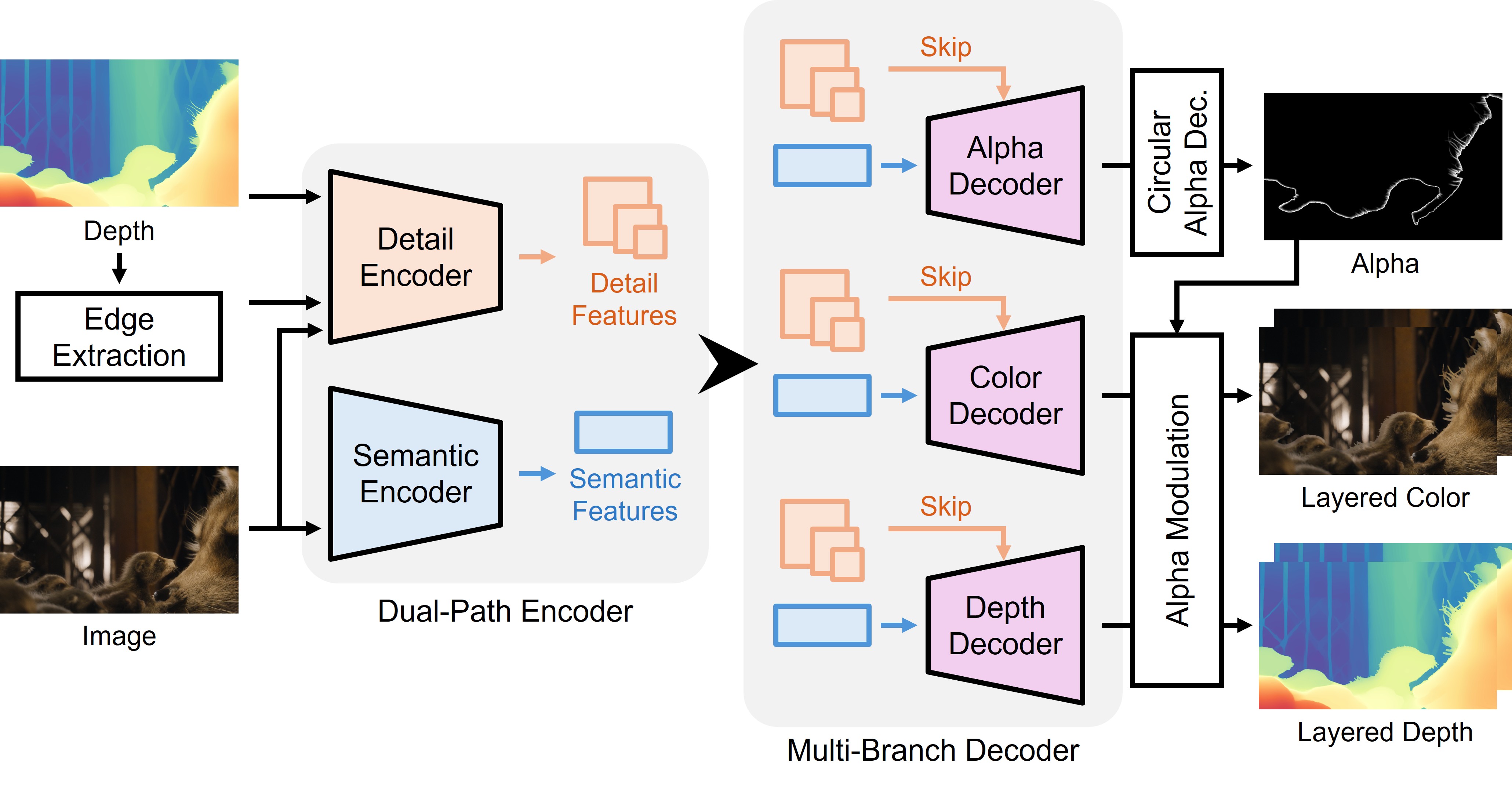
Figure 4 — αDepth 추정 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 soft boundary의 계층적 분해를 통해 스테레오 변환의 품질을 획기적으로 향상시키는 αDepth 프레임워크를 성공적으로 제안하였습니다. CAR의 도입으로 인해 사용자 개입 없이 복잡한 장면의 경계면을 처리할 수 있게 된 점은 학계와 산업계의 자동화된 3D 콘텐츠 생성 워크플로우에 중요한 기여를 합니다. 향후 본 연구는 고품질의 VR/AR 콘텐츠 제작 및 영상 후처리 파이프라인에서 핵심적인 모듈로 활용될 것으로 기대됩니다.

Figure 1 — αDepth 계층적 표현 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GenClaw: Code-Driven Agentic Image Generation
- [논문리뷰] StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Review 의 다른글
- 이전글 [논문리뷰] Ψ-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
- 현재글 : [논문리뷰] αDepth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
- 다음글 [논문리뷰] AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
댓글