[논문리뷰] Domain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tong Ye, Hang Yu, Tengfei Ma, Xuhong Zhang, Jianguo Li, Peng Di, Peiyu Liu, Jianwei Yin, Wenhai Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Domino: 본 논문에서 제안하는 도메인 특화 데이터 합성 프레임워크로, 참조 예시로부터 도메인의 핵심 원리를 유도(induce)하여 데이터를 생성함.
- Minimal Sufficient Representation ($D^*$): 도메인의 본질적인 특성은 유지하면서 개별 샘플의 잡음(noise)이나 중복 정보를 제거한 최소한의 잠재 표현.
- Contrastive Disentanglement: 도메인 수준의 패턴과 샘플 수준의 고유 특성을 분리하기 위해 도입된 기법으로, Overfitting을 방지하고 일반화 성능을 향상함.
- Implicit Domain: 자연어로 명확하게 기술하기 어려운 도메인(예: 시시각각 변하는 코딩 문제의 트렌드 등)을 지칭함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 도메인 특화 적응(Domain-Specific Adaptation) 과정에서 발생하는 데이터 확보 문제를 해결하고자 한다. 기존 연구들은 도메인 정의가 자연어로 명확히 기술되어야 한다는 Deduction(연역) 기반의 패러다임에 의존하고 있어, 도메인 특성이 암시적(Implicit)인 경우 적합하지 않다. 또한, 단순히 소량의 참조 데이터로 SFT를 수행하는 경우 모델이 샘플의 지엽적인 특성만을 암기하는 Overfitting 문제가 발생하여 실제 환경에서의 일반화 성능이 저하된다. 따라서 저자들은 참조 예시로부터 도메인의 핵심 규칙을 귀납적으로 학습하여, 암시적 도메인에서도 고품질의 합성 데이터를 생성할 수 있는 새로운 프레임워크를 제안한다. [Figure 1]은 Domino가 도메인 특성을 어떻게 잠재 임베딩으로 인코딩하여 합성 프로세스를 가이드하는지 보여준다.
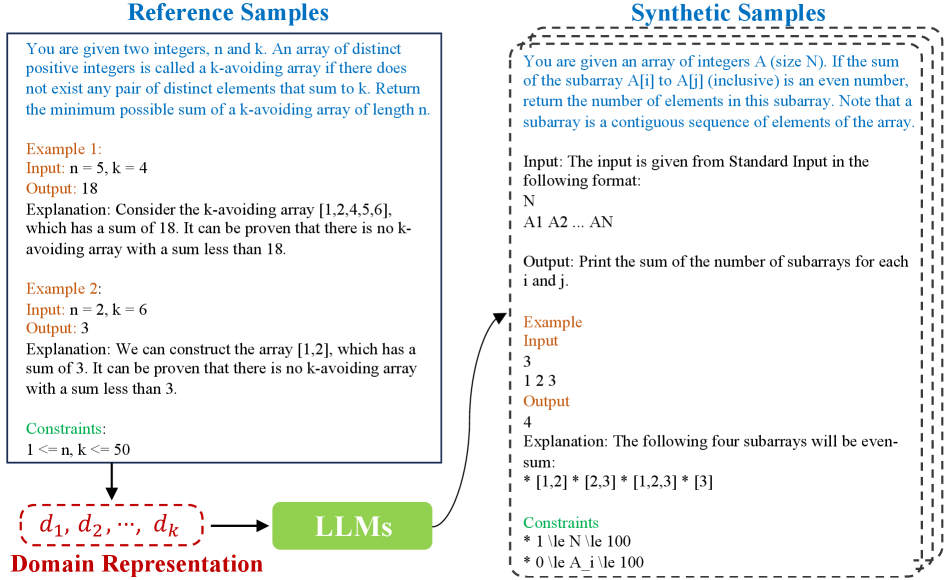
Figure 1 — Domino의 도메인 특성 인코딩 및 합성 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
Domino는 Prompt Tuning을 활용하여 도메인 정보를 학습하고, Contrastive Disentanglement 목적 함수를 통해 도메인 패턴과 샘플 특성을 분리한다. 구체적으로, 전체 손실 함수는 $\mathcal{L} = \mathcal{L}_1 + \lambda\mathcal{L}_2$로 정의되며, 여기서 $\mathcal{L}_1$은 도메인 재구성을 위한 우도(Likelihood)를, $\mathcal{L}_2$는 샘플 간 대조를 통해 최소한의 표현을 강제하는 역할을 한다. 이론적으로 저자들은 Domino가 기존 방법 대비 합성 데이터의 지원 범위(Support)를 확장하여 다양성을 확보함을 입증하였다. 실험 결과, Domino를 사용하여 생성된 데이터로 Fine-tuning을 수행했을 때, Live Code Generation 벤치마크에서 기존의 Instruction-tuned 모델 대비 Pass@1 정확도가 최대 4.63% 향상되는 성과를 거두었다. 또한, Live Code Execution 도메인에서도 일관된 성능 우위를 보이며, 복잡한 프롬프트 엔지니어링 없이도 효과적인 도메인 적응이 가능함을 검증하였다 [Table 1]. [Figure 2]는 Domino의 전반적인 아키텍처와 학습 프로세스를 나타낸다.
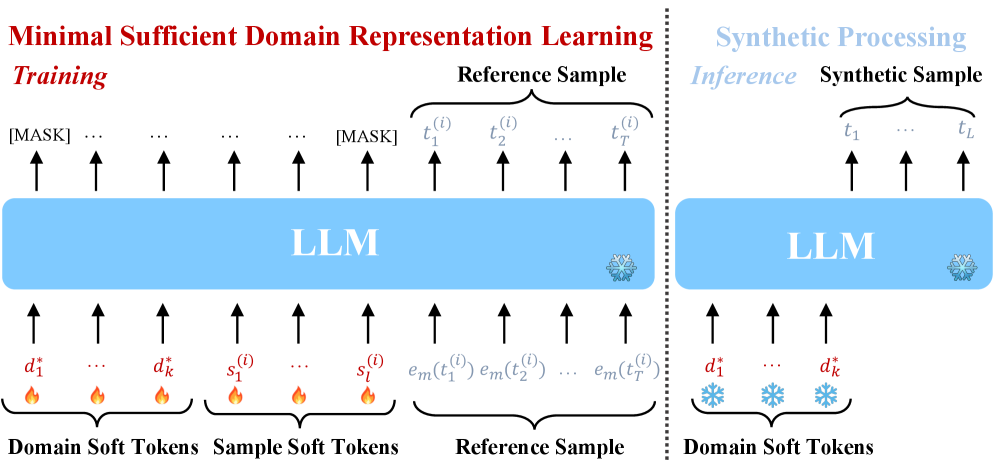
Figure 2 — Domino의 전체 학습 및 합성 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 암시적으로 정의된 도메인으로부터 데이터를 효과적으로 합성하는 Domino 프레임워크를 성공적으로 제안하였다. 이 연구는 도메인 특화 적응을 위해 필수적이었던 수동 프롬프트 설계나 명시적인 도메인 정의의 의존성을 제거했다는 점에서 큰 학술적, 산업적 의의를 갖는다. Domino가 제안하는 귀납적 데이터 합성 패러다임은 향후 급변하는 기술 트렌드나 기밀 비즈니스 도메인 등 데이터 확보가 어려운 영역에서 LLM의 범용성을 크게 확장할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GAPrune: Gradient-Alignment Pruning for Domain-Aware Embeddings
- [논문리뷰] You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
- [논문리뷰] Realiz3D: 3D Generation Made Photorealistic via Domain-Aware Learning
- [논문리뷰] A Causal Language Modeling Detour Improves Encoder Continued Pretraining
- [논문리뷰] PRL-Bench: A Comprehensive Benchmark Evaluating LLMs' Capabilities in Frontier Physics Research
Review 의 다른글
- 이전글 [논문리뷰] Diagnosing Harmful Continuation in Answer-Correct Long-CoT Training Traces
- 현재글 : [논문리뷰] Domain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
- 다음글 [논문리뷰] From Activation to Causality: Discovery of Causal Visual Representations in the Human Brain
댓글