[논문리뷰] Cosmos 3: Omnimodal World Models for Physical AI
링크: 논문 PDF로 바로 열기
메타데이터
저자: Aditi, Niket Agarwal, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Cosmos 3: Language, image, video, audio, action modality를 통합적으로 처리하고 생성하는 Mixture-of-Transformers 기반의 omnimodal world model.
- MoT (Mixture-of-Transformers): Reasoning을 위한 reasoner tower와 generation을 위한 generator tower를 결합한 아키텍처로, 동일한 transformer block 내에서 독립적인 파라미터 셋을 운영함.
- Physical AI: 물리적 세계와 상호작용하기 위해 로봇 제어, 자율 주행, 스마트 인프라 등을 아우르는 인공지능 분야.
- SDG (Synthetic Data Generation): 물리적 시뮬레이터(NVIDIA Isaac Sim 등)를 활용하여 데이터 부족 문제를 해결하고 모델의 physically grounded reasoning을 강화하기 위해 생성한 대규모 데이터셋.
- Action-Conditioned Generation: 특정 액션 토큰(Action tokens)을 입력으로 받아 향후 시각적 변화나 제어 결과를 생성하는 Physical AI 핵심 기능.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Physical AI 에이전트 학습을 위한 기존의 파편화된 파이프라인은 이해(Understanding)와 생성(Generation) 모듈이 분리되어 있어 데이터 효율성과 확장성이 낮습니다. 저자들은 vision-language 모델(VLM), 비디오 생성 모델, world model, 그리고 action-prediction 모델이 각각의 task-specific pipeline으로 운영되는 현 아키텍처의 한계를 지적합니다. 이를 극복하기 위해 물리적 이해와 미래 예측(simulation) 능력이 결합된 단일 통합 프레임워크가 필수적입니다. [Figure 1]에서 볼 수 있듯이, 본 연구는 language, image, video, audio, action을 동시에 모델링하여 이들을 하나로 묶는 범용 백본(General-purpose backbone)인 Cosmos 3를 제안합니다.
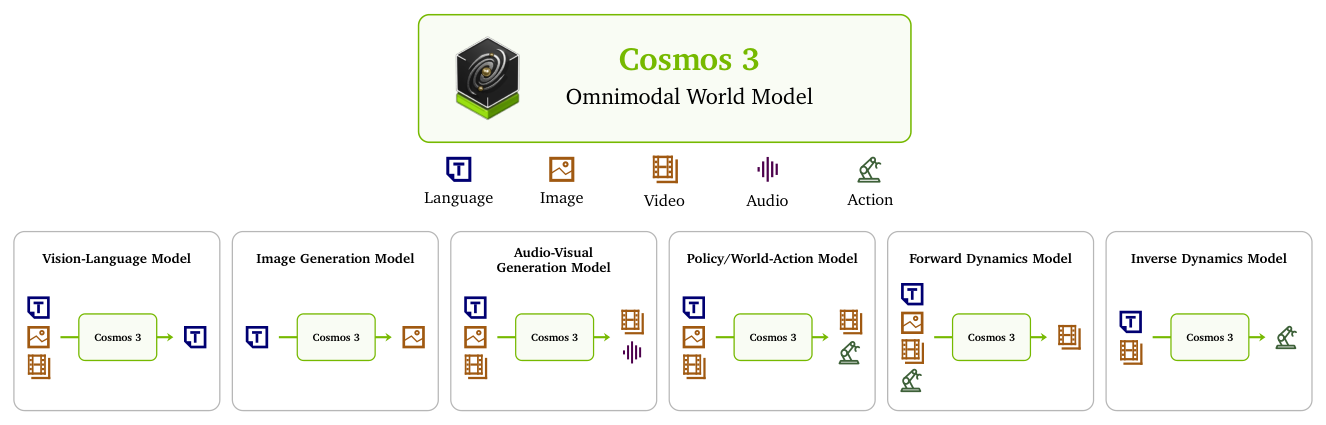
Figure 1 — 전체 모델 아키텍처의 핵심 컨셉을 요약한 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
Cosmos 3는 Mixture-of-Transformers 구조를 통해 reasoner와 generator가 파라미터를 효율적으로 공유하면서도 각각의 임무를 수행하도록 설계되었습니다. 입출력 modalities를 통합하기 위해 각 도메인의 특성에 맞춘 modality-specific encoders를 사용하며, 특히 물리적 상호작용을 위해 action 토큰을 핵심 데이터로 도입했습니다. 학습 효율성을 극대화하기 위해 token-budgeted packed sequences와 look-ahead packing을 적용한 joint data-loader를 구현하여, 다양한 해상도와 시퀀스 길이를 갖는 멀티모달 데이터를 처리합니다. 주요 결과로 Cosmos 3는 벤치마크 테스트에서 기존 전문 모델들을 상회하는 성능을 보였습니다. 특히 텍스트-투-이미지 생성 성능(UniGenBench 점수 91.36)과 로봇 정책 학습(RoboLab 성공률 39.7%)에서 가장 우수한 성능을 기록했습니다. [Table 1]과 [Table 10]은 Cosmos 3가 general reasoning과 generation capabilities 전반에서 state-of-the-art를 달성했음을 보여줍니다. 또한 [Figure 18] 및 [Figure 19]는 오픈 소스 및 공개된 체크포인트 모델 중에서 최상위권 성적을 거두었음을 입증합니다.
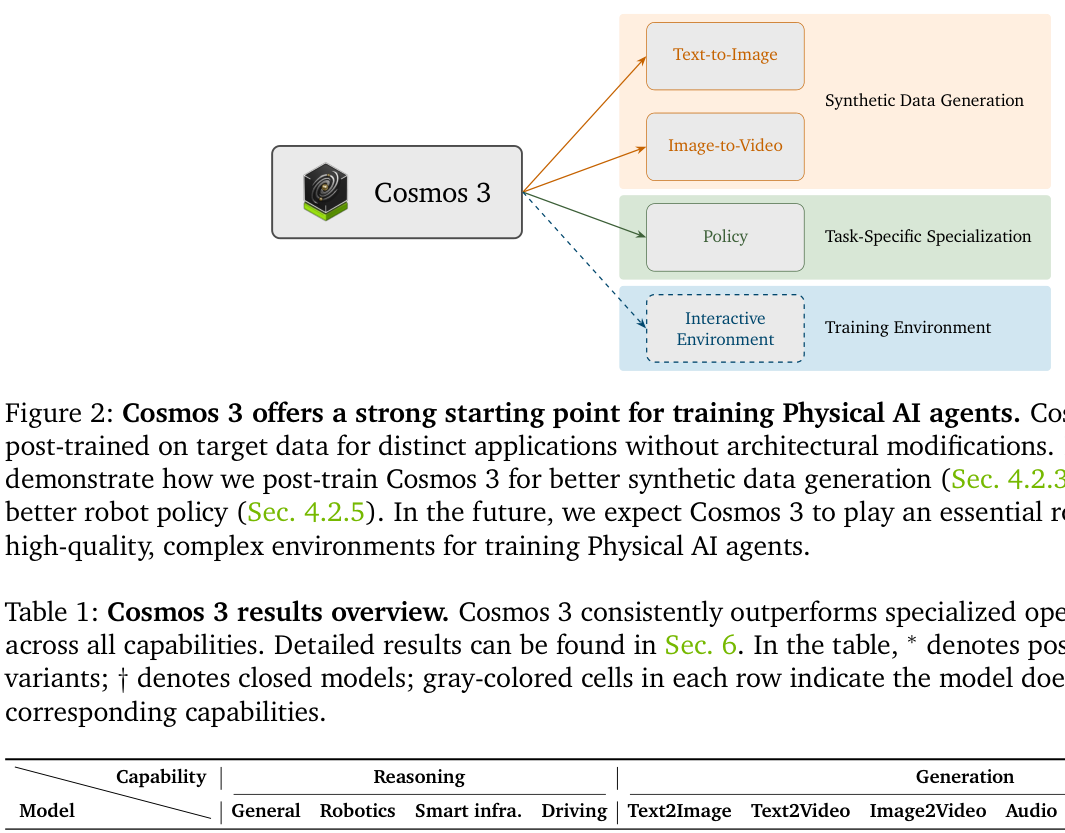
Table 1 — 기존 모델 대비 Cosmos 3의 성능 우위를 보여주는 핵심 결과 테이블
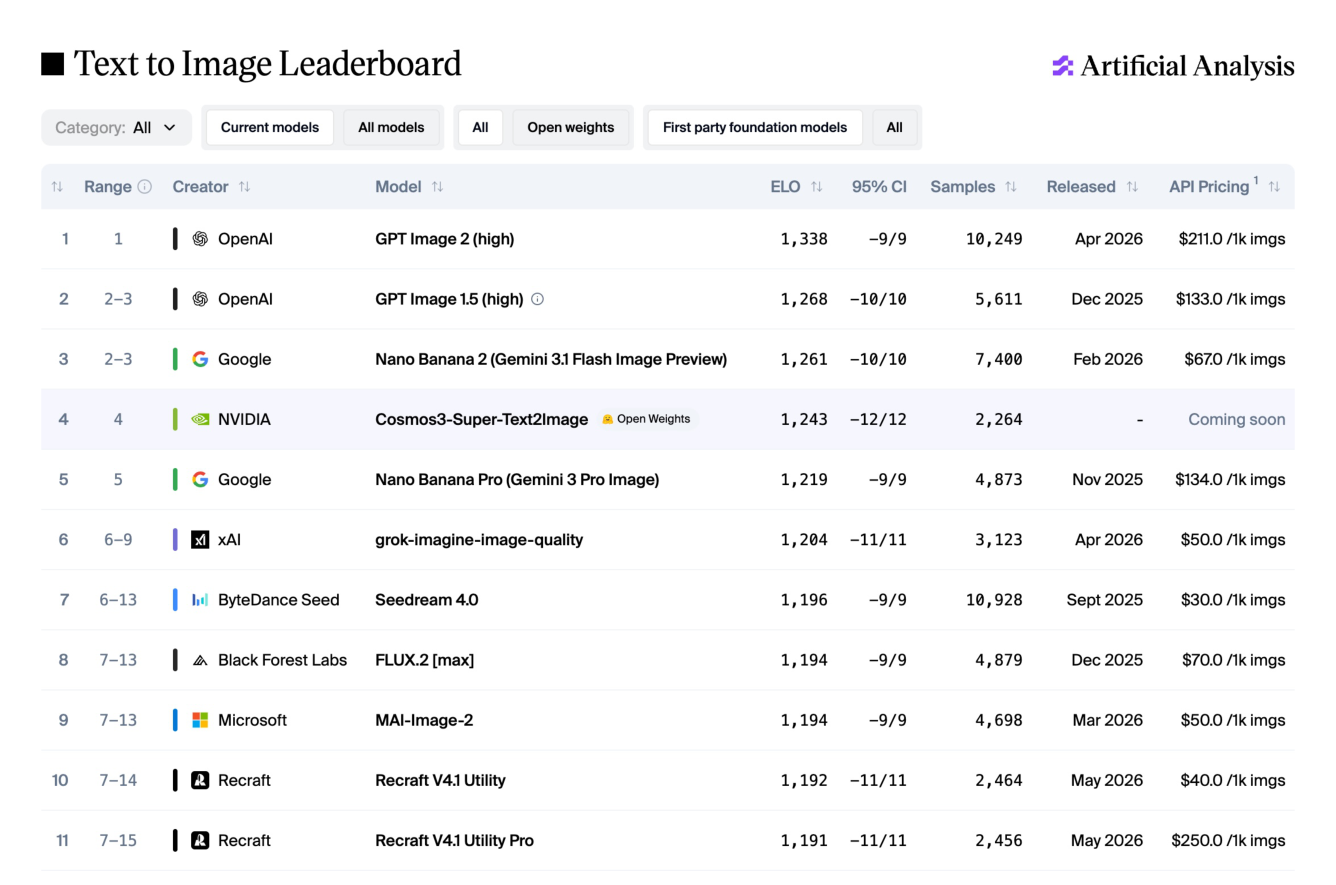
Figure 18 — 모델의 외부 평가 성능을 보여주는 리더보드 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 이해와 생성을 하나의 프레임워크로 통합한 Cosmos 3를 제안하여 Physical AI 연구의 새로운 전환점을 제시합니다. 이 아키텍처는 추가적인 구조 변경 없이도 다양한 타겟 도메인으로의 post-training이 가능하여, embodied agent 학습에 강력한 범용 백본 역할을 수행합니다. 저자들은 코드, 모델 체크포인트, 벤치마크 데이터셋을 오픈 소스로 공개함으로써 Physical AI 관련 연구 및 실제 로봇 배포를 가속화하는 데 크게 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] MoVerse: Real-Time Video World Modeling with Panoramic Gaussian Scaffold
- [논문리뷰] Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
- [논문리뷰] Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
- [논문리뷰] OCC-RAG: Optimal Cognitive Core for Faithful Question Answering
Review 의 다른글
- 이전글 [논문리뷰] BraveGuard: From Open-World Threats to Safer Computer-Use Agents
- 현재글 : [논문리뷰] Cosmos 3: Omnimodal World Models for Physical AI
- 다음글 [논문리뷰] DAR: Deontic Reasoning with Agentic Harnesses
댓글