[논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
링크: 논문 PDF로 바로 열기
메타데이터
저자: Lianyu Pang, Tianlin Pan, Cheng Da, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Representation Alignment: 사전 학습된 vision encoder의 표현을 활용하여 diffusion 모델의 중간 특징을 정렬함으로써 학습 수렴과 성능을 가속화하는 기법입니다.
- Token-Subset Alignment: 전체 토큰셋 대신 랜덤하게 샘플링된 토큰 부분집합(subset)에만 정렬 손실 함수를 적용하여 모델의 정렬 안정성을 높이는 방식입니다.
- Pre-mask Token Mixing: 토큰 마스킹으로 인한 정보 손실을 방지하기 위해 마스킹 전 토큰 간의 정보를 교환(sharing)하는 경량화된 블록입니다.
- SiT (Scalable Interpolant Transformers): 연속 시간 확률 보간(stochastic interpolants) 프레임워크를 기반으로 하며, 본 논문에서 핵심 아키텍처로 사용됩니다.
- Alignment-Gradient Distribution: 정렬 손실(alignment loss)의 그래디언트가 특정 공간적 위치에 편향되어 분포하는 현상을 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Representation Alignment 기법이 diffusion 모델의 학습 효율성을 개선함에도 불구하고, 노이즈가 포함된 모델 입력과 깨끗한 이미지 기반의 참조 특징 사이에서 발생하는 근본적인 '불일치(mismatch)' 문제를 해결하고자 합니다. 기존의 Full-token alignment 방식은 모든 토큰에 대해 무조건적인 정렬을 강제하며, 이로 인해 그래디언트가 특정 위치에 편향되게 분포하는 현상이 발생합니다 [Figure 2]. 이러한 편향은 모델이 실제 노이즈 제거 조건에서 유용한 특징을 학습하기보다, 깨끗한 이미지 패턴에만 의존하는 'shortcut' 학습에 치중하게 만듭니다. 결과적으로 기존 방식은 토큰셋에 대한 과도한 의존성을 보이며 다양한 입력 조건에서 정렬 안정성이 낮다는 한계가 존재합니다.
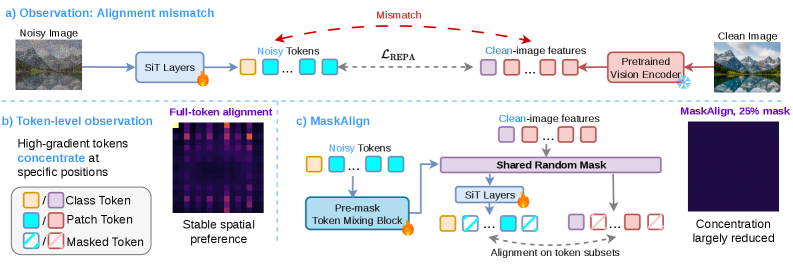
Figure 2 — 토큰 레벨 분석 및 정렬 안정성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 MaskAlign을 제안하여 학습 단계에서 무작위로 샘플링된 토큰 부분집합에만 정렬을 수행함으로써, 특정 토큰셋에 대한 모델의 과의존을 방지하고 안정적인 학습 신호를 제공합니다 [Figure 3]. 모델은 마스킹 전 경량화된 pre-mask token mixing 블록을 통해 토큰 간 정보를 교환하며, 이를 통해 토큰 삭제로 인한 정보 손실을 효과적으로 완화합니다. 실험 결과, MaskAlign은 SiT-XL/2 기준 기존 REPA 대비 8.3 FID 수준에 도달하는 학습 반복(iteration) 수를 약 30배 단축시켰으며, 전반적인 수렴 속도를 획기적으로 개선했습니다 [Figure 1]. 또한 400K 반복 학습 시 정량적으로 FID 성능을 3.4에서 2.8로 개선하는 동시에, 단계별 학습 시간을 REG 방식 대비 11.6% 단축하며 연산 효율성을 입증했습니다 [Table 4].
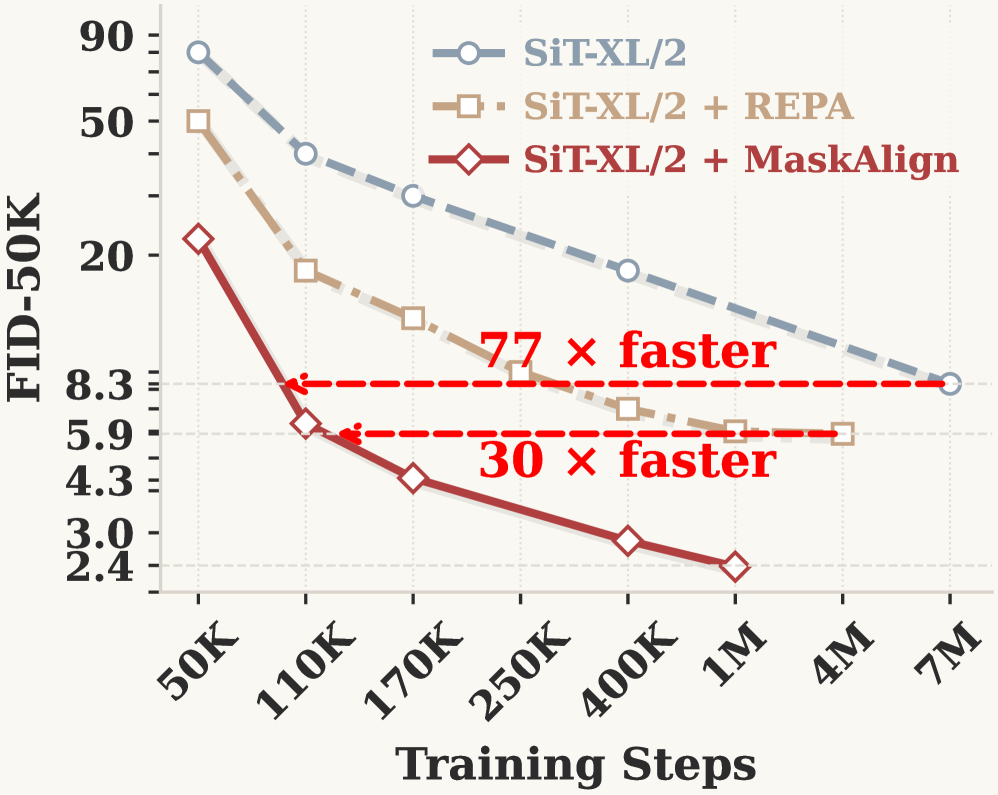
Figure 1 — 학습 수렴 속도 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 토큰 레벨의 정렬 분석을 통해 기존 방식의 학습 편향성을 규명하고, 토큰 부분집합 기반 정렬과 정보 혼합(mixing)을 결합한 MaskAlign을 제시함으로써 효율적인 diffusion 학습의 새로운 방향성을 제시합니다. 이 연구는 연산 자원이 제한적인 환경에서도 고성능 생성 모델을 보다 빠르게 학습할 수 있는 실용적인 방법론을 제공하며, 향후 더 높은 해상도나 텍스트-이미지 생성 등 확장 가능성을 열어두었습니다. 본 기법은 생성 모델 학습의 연산 비용 절감과 품질 향상이라는 두 가지 측면에서 학계와 산업계에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Representation Alignment for Just Image Transformers is not Easier than You Think
- [논문리뷰] FRAPPE: Infusing World Modeling into Generalist Policies via Multiple Future Representation Alignment
- [논문리뷰] Semantic Routing: Exploring Multi-Layer LLM Feature Weighting for Diffusion Transformers
- [논문리뷰] Guiding a Diffusion Transformer with the Internal Dynamics of Itself
- [논문리뷰] LATTICE: Democratize High-Fidelity 3D Generation at Scale
Review 의 다른글
- 이전글 [논문리뷰] Leveraging Morphology for Historical Script Metrological Analysis
- 현재글 : [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- 다음글 [논문리뷰] MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
댓글