[논문리뷰] LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jian Yang, Shawn Guo, Wei Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Parallel Loop Transformer (PLT): 공유된 Transformer 블록을 반복적으로 사용하여 latent depth를 확장하면서도, Cross-loop position offsets(CLP)와 G-SWA를 통해 병렬 연산을 가능하게 하여 추론 속도와 효율성을 최적화한 아키텍처입니다.
- Cross-Loop Position Offset (CLP): 이전 루프의 hidden state를 한 토큰씩 우측으로 이동(shift)시켜 루프 간 의존성을 분리함으로써, 병렬적인 루프 실행을 가능하게 하는 메커니즘입니다.
- Gain–Cost Trade-off: 추가적인 루프를 통해 얻는 'representation refinement(이득)'와 CLP로 인해 발생하는 'positional mismatch(비용)' 사이의 균형을 나타내는 PLT 설계의 핵심 분석 지표입니다.
- G-SWA (Gated Sliding-Window Attention): 고정된 첫 번째 루프의 KV 캐시와 현재 루프의 로컬 윈도우 정보를 Head-wise gate를 통해 동적으로 결합하여, 루프 수와 관계없이 메모리 사용량을 O(L·S·d)로 제한하는 기술입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LoopCoder-v2를 통해 PLT에서 루프 횟수(loop count) 선택이 성능에 미치는 영향을 규명하고, 왜 특정 루프 횟수에서 성능이 포화되거나 저하되는지를 분석하고자 합니다. 기존의 Looped Transformer는 sequential한 루프 구조로 인해 루프 수가 늘어날수록 latency와 KV-cache 메모리 비용이 증가하는 한계가 있었습니다. PLT는 이러한 구조적 비용 문제를 해결했으나, 대신 CLP로 인한 positional mismatch라는 새로운 비용을 도입하게 되었습니다. 따라서 저자들은 루프 횟수가 단순한 디자인 선택을 넘어, 모델의 refinement gain과 구조적 cost 사이의 최적점을 찾아야 하는 문제임을 지적합니다 [Figure 1].
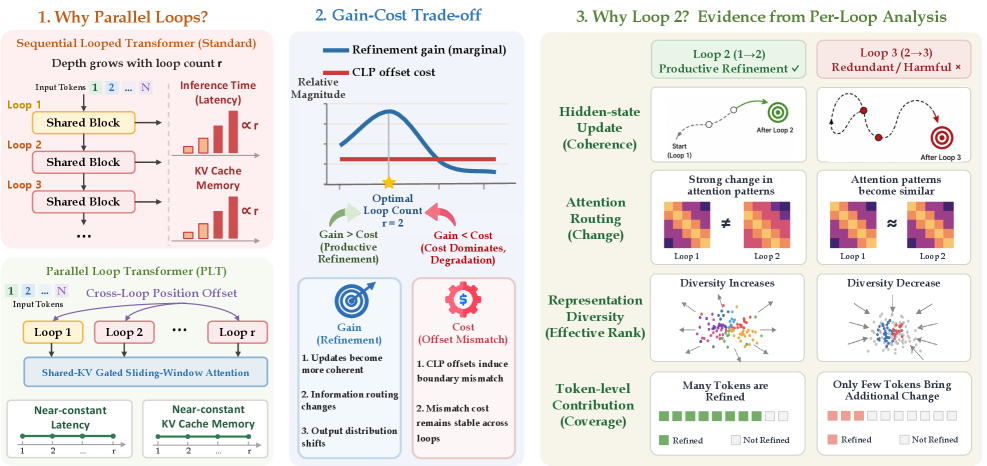
Figure 1 — PLT 루프 횟수 선택의 gain-cost 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 PLT의 루프 횟수 선택을 gain–cost 렌즈로 해석하고, 7B 파라미터의 LoopCoder-v2를 18T 토큰으로 학습시켜 검증하였습니다. 연구 결과, 루프 횟수에 따른 성능은 non-monotonic한 경향을 보이며, $R=2$인 모델이 가장 우수한 성능을 나타냈습니다. 정량적 지표로, SWE-bench Verified에서 $R=2$ 모델은 64.4점을 기록하여, 베이스라인(43.0점) 대비 괄목할만한 성능 향상을 달성하였습니다 [Table 2]. 반면, $R=3$ 이상의 모델은 오히려 성능이 저하되는 양상을 보였습니다. 분석 결과, 두 번째 루프($R=2$)가 가장 생산적인 refinement를 제공하는 반면, 이후 루프는 CLP에 따른 고정 비용($\Omega^{(r)}$) 대비 refinement 이득이 급격히 감소하고 oscillatory한 업데이트를 유발하기 때문임을 확인했습니다 [Figure 3].
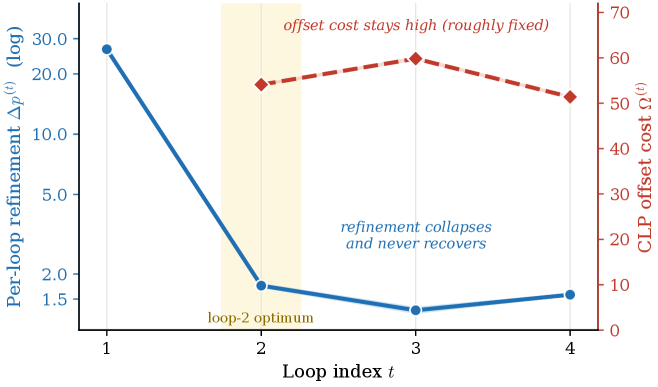
Figure 3 — 루프별 이득(gain)과 비용(cost)의 트레이드오프
4. Conclusion & Impact (결론 및 시사점)
본 연구는 PLT 아키텍처에서 추가 루프가 항상 성능 향상을 보장하지 않으며, 두 번째 루프($R=2$)가 대표적인 생산적 refinement 지점임을 정량적으로 입증하였습니다. 이 분석은 향후 대형 언어 모델의 test-time compute scaling을 설계함에 있어, 무분별한 깊이 확장이 아닌 루프별 기여도와 구조적 비용을 고려한 최적의 설계 가이드라인을 제공합니다. 이는 특히 추론 효율성과 성능의 균형이 중요한 에이전트 및 코드 생성 모델 분야에서 중요한 학술적·산업적 시사점을 가집니다.
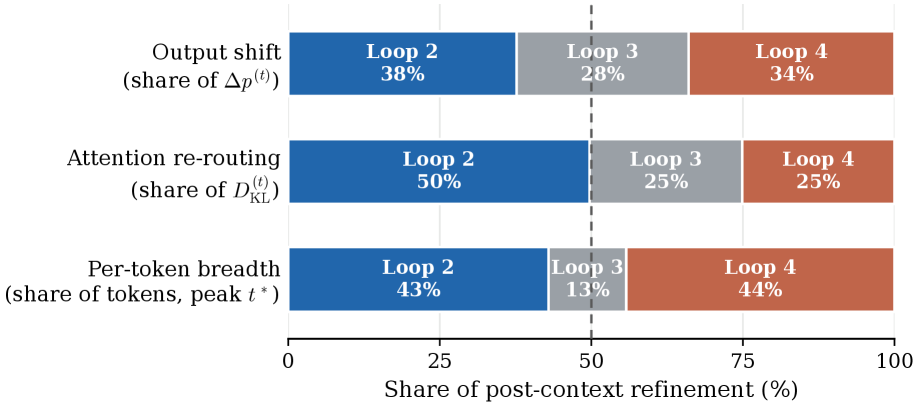
Figure 7 — 루프별 Refinement 분포 및 기여도
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] Multi-LCB: Extending LiveCodeBench to Multiple Programming Languages
- [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
- [논문리뷰] Do Coding Agents Deceive Us? Detecting and Preventing Cheating via Capped Evaluation with Randomized Tests
- [논문리뷰] Latent Reasoning with Normalizing Flows
Review 의 다른글
- 이전글 [논문리뷰] LectūraAgents: A Multi-Agent Framework for Adaptive Personalized AI-Assisted Learning and Embodied Teaching
- 현재글 : [논문리뷰] LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
- 다음글 [논문리뷰] Looped World Models
댓글