[논문리뷰] Playful Agentic Robot Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Junyi Zhang, Jiaxin Ge, Hanjun Yoo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Code-as-Policy (CaP): LLM 또는 LMM을 사용하여 환경의 Perception과 Control API를 호출하는 실행 가능한 Python 프로그램을 생성하는 로봇 제어 프레임워크.
- RATs (Robotics Agent Teams): Play-time 동안 스스로 Exploratory Task를 제안하고, 이를 실행·검증·진단하여 성공적인 행동을 재사용 가능한 Code Skill로 추출하는 에이전트 시스템.
- Skill Library (ℒ): 학습된 로봇 행동들이 코드 형태로 저장된 데이터베이스로, 이후의 Downstream Task 수행 시 검색 및 재사용이 가능함.
- Failure Memory (ℳ): 반복적인 실패 사례에서 얻은 교훈(예: 선행 조건 결여, 수정 사항)을 저장하여 향후 Retry 시 활용하는 기억 장치.
- Goldilocks Principle: 과도하게 쉽거나 어려운 작업 대신, 학습 진행도와 novelty를 고려하여 에이전트가 가장 효율적으로 학습할 수 있는 수준의 난이도를 가진 작업을 선택하는 전략.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Code-as-Policy 시스템이 외부 명령에 의존하는 Task-driven 방식으로 작동하여, 실제 작업이 주어지기 전에는 재사용 가능한 Skill을 습득하지 못한다는 한계를 해결하고자 한다. 자연 지능에서 착안한 '놀이(Play)'의 개념을 로봇 학습에 도입하여, 명시적인 외부 보상이 없는 상태에서도 에이전트가 스스로 실용적인 기술을 축적하는 Playful Agentic Robot Learning을 제안한다. 이를 통해 에이전트는 배치 전 사전 학습(Pre-deployment)을 통해 역량을 강화할 수 있다. 본 연구의 핵심 프레임워크인 RATs의 구성과 놀이 과정을 Figure 1과 Figure 2에서 확인할 수 있다 [Figure 1], [Figure 2].

Figure 1 — RATs 기반의 놀이 학습 프레임워크 개념도
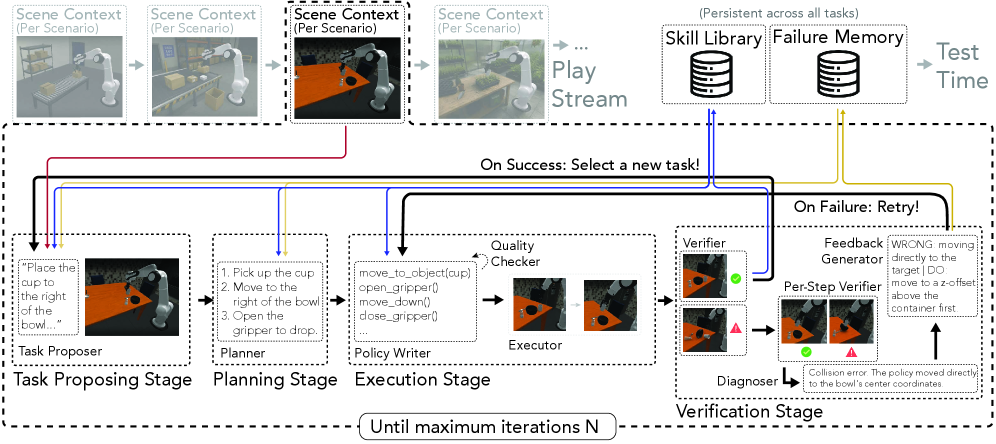
Figure 2 — RATs의 놀이 및 스킬 학습 루프 상세
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Task Proposer, Execution, Memory-Management 팀으로 구성된 RATs를 통해 놀이 기반의 지속적 Skill 학습을 수행한다. Task Proposer는 Novelty와 Learnability를 고려하여 최적의 탐색 작업을 선정하고, Execution 팀은 Write-Execute-Verify-Diagnose 루프를 통해 코드를 작성 및 실행한다. 실패 시에는 Failure Memory가 진단 정보를 제공하며, 성공한 행동은 Skill Library에 저장되어 향후 재사용된다. LIBERO-PRO 벤치마크 실험 결과, RATs는 기준 모델인 CaP-Agent0 대비 약 20.6%p 높은 성공률을 기록하였다 [Table 1]. 또한, MolmoSpaces 환경에서도 평균 성공률이 21.0%에서 38.0%로 크게 개선됨을 확인하였다 [Table 2]. 특히 학습된 Skill을 다른 에이전트 환경에 적용한 Cross-environment Transfer 실험(RoboSuite)에서도 8.9%p의 성능 향상을 보여, 별도의 Fine-tuning 없이도 높은 범용성을 입증하였다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 놀이(Play)가 로봇 에이전트가 외부 보상 없이도 재사용 가능한 Skill을 체계적으로 습득할 수 있는 효율적인 메커니즘임을 입증하였다. RATs 프레임워크를 통해 구축된 Skill Library는 기존 코드 기반 로봇 시스템의 한계를 보완하며, 하드웨어 성능을 극대화할 수 있는 플러그인 형태로 활용될 수 있다. 이 연구는 범용적인 로봇 지능 개발을 위해 사전 학습 단계로서의 '놀이'가 갖는 학계 및 산업적 가치를 제시하며, 향후 더 복잡하고 물리적인 환경에서의 확장 가능성을 열어두었다.

Figure 3 — 시뮬레이션 환경에서의 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
- [논문리뷰] LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
- [논문리뷰] μ_0: A Scalable 3D Interaction-Trace World Model
- [논문리뷰] ActiveMimic: Egocentric Video Pretraining with Active Perception
댓글