[논문리뷰] Advancing WordArt-Oriented Scene Text Recognition: Datasets and Methods
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xingsong Ye, Yongkun Du, Jiaxin Zhang, Haojie Zhang, Chong Sun, Chen Li, Jing Lyu, Zhineng Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- WATER (WordArt-oriented scene TExt Recognition): 일반적인 Scene Text Recognition(STR)보다 시각적 스타일화, 복잡한 레이아웃 및 텍스트 왜곡이 심한 artistic text를 인식하는 특수 작업입니다.
- WATER-S: 본 연구에서 제안하는 2M 규모의 대규모 합성 데이터셋으로, 툴 기반의
WATER-T와 모델 기반의WATER-Z로 구성됩니다. - WATERec: Arbitrary-shaped 입력을 지원하는 Vision Transformer 인코더와 Autoregressive (AR) Decoder를 결합하여 WordArt 인식 성능을 최적화한 강력한 STR 베이스라인 모델입니다.
- RoPE (Rotary Position Embedding): 고정된 템플릿 없이 가변적인 입력 해상도와 레이아웃을 효과적으로 처리하기 위해 제안 모델에 적용된 위치 인코딩 기법입니다.
- WordArt-Bench: artistic text 인식 성능을 평가하기 위한 벤치마크 데이터셋으로, 본 연구의 모델 및 데이터셋 성능 검증의 핵심 지표로 활용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 예술적 텍스트(WordArt)가 가진 고도의 시각적 스타일화와 불규칙한 레이아웃으로 인해 기존 STR 모델들이 겪는 성능 한계를 해결하고자 합니다. 기존의 STR 데이터셋과 방법론은 주로 규칙적인 텍스트와 고정된 템플릿 입력에 최적화되어 있어, 예술적 텍스트의 복잡한 폰트, 질감, 레이아웃을 처리하는 데 심각한 제약을 보입니다 [Figure 1]. 또한, 실제 환경에서의 WordArt 데이터 수집 및 주석(annotation)은 비용이 매우 높고 데이터 규모가 작아 모델 학습을 위한 충분한 다양성을 확보하기 어렵습니다. 이러한 문제를 극복하기 위해 본 연구는 데이터 생성 파이프라인의 혁신과, 가변적인 입력을 처리할 수 있는 새로운 아키텍처 설계를 통해 WATER 작업의 성능을 향상시키는 것을 목표로 합니다.
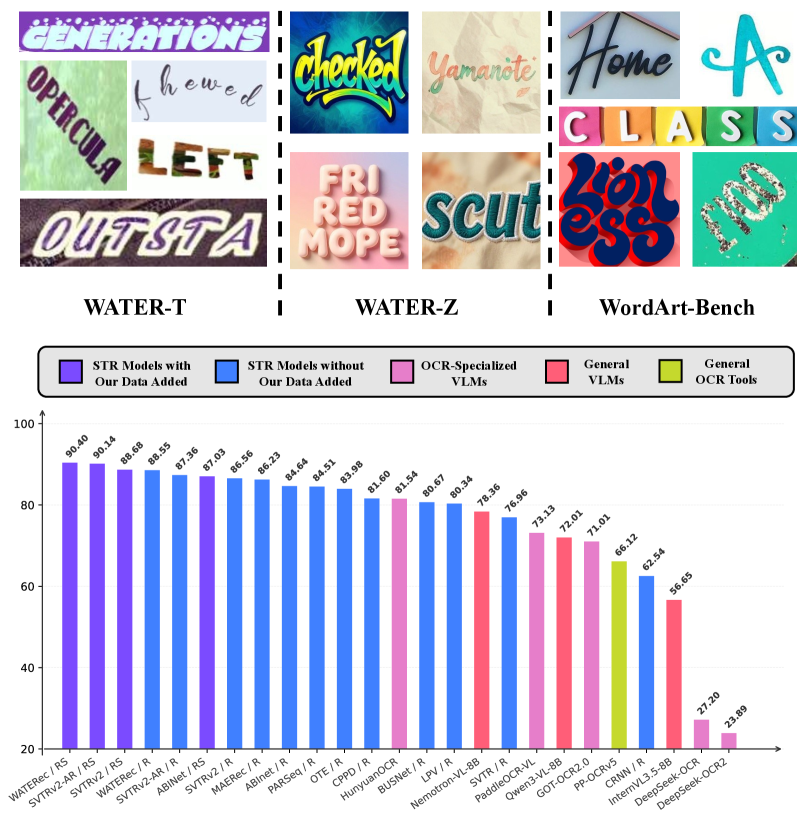
Figure 1 — 합성 데이터셋 예시 및 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 데이터 효율성을 극대화하기 위해 툴 기반의 SynthWordArt와 모델 기반의 Z-Image-Turbo를 활용한 합성 데이터 생성 프레임워크인 WATER-S를 제안합니다 [Figure 2]. 또한, 입력 이미지의 해상도 왜곡 문제를 해결하고 복잡한 레이아웃을 모델링하기 위해, RoPE 기반의 인코더와 Autoregressive 디코더를 갖춘 WATERec 모델을 도입하였습니다 [Figure 3]. 실험 결과, 제안 모델 WATERec은 기존의 여러 STR 베이스라인 대비 탁월한 성능을 보였으며, WordArt-Bench에서 90.40%라는 SOTA 정확도를 달성했습니다. 특히 WATER-S를 추가 학습했을 때 기존 모델 대비 정확도가 일관되게 향상되었으며, 이는 기존 VLM 모델들의 성능(81.54% 이하)을 큰 폭으로 상회하는 수치입니다 [Table 1, Table 2].
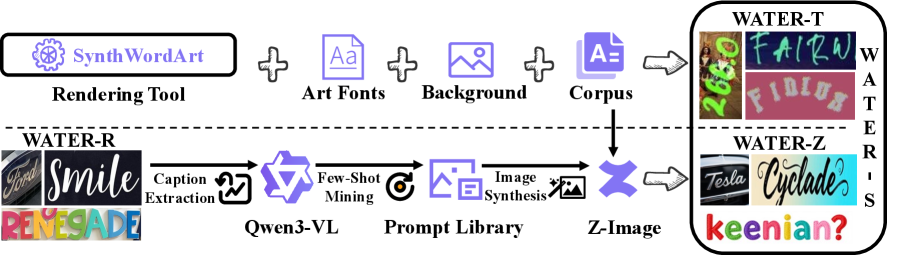
Figure 2 — WATER-S 데이터 생성 파이프라인
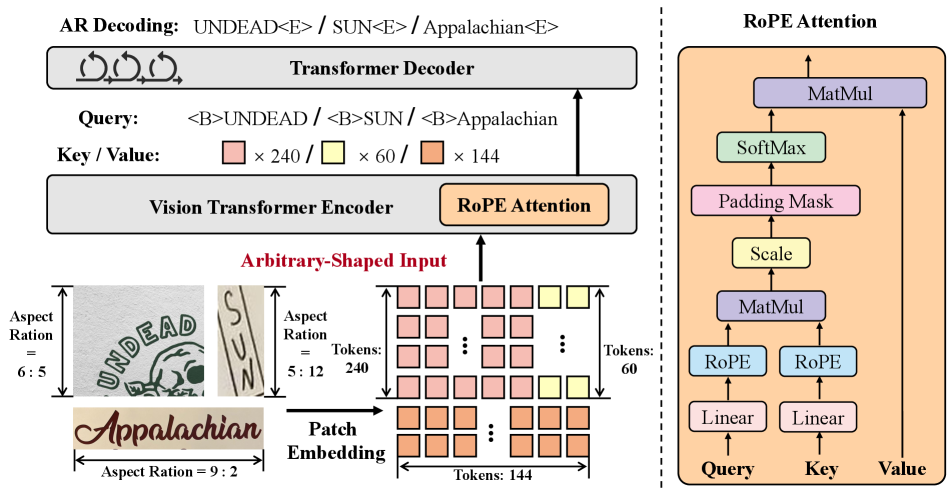
Figure 3 — WATERec 아키텍처 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 대규모 합성 데이터셋 WATER-S와 혁신적인 모델 아키텍처 WATERec을 제안함으로써 artistic text 인식 분야의 새로운 기준을 마련했습니다. 연구 결과는 예술적 텍스트 인식이 더 이상 일반 STR의 한계를 벗어나지 못하는 작업이 아니라, 전용 아키텍처와 데이터 전략을 통해 높은 정확도를 달성할 수 있음을 보여줍니다. 이는 광고 디자인, 포스터, 표지판 등 다양한 실제 응용 시나리오에서 OCR 시스템의 신뢰성을 크게 향상시킬 수 있는 기술적 토대가 될 것입니다. 향후 본 연구의 데이터 생성 파이프라인과 모델 구조는 다국어 및 보다 복잡한 시각적 도메인으로 확장되어 학계 및 산업계에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
- [논문리뷰] Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
- [논문리뷰] Exploring Autonomous Agentic Data Engineering for Model Specialization
- [논문리뷰] Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning
- [논문리뷰] OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
Review 의 다른글
- 이전글 [논문리뷰] World Value Models for Robotic Manipulation
- 현재글 : [논문리뷰] Advancing WordArt-Oriented Scene Text Recognition: Datasets and Methods
- 다음글 [논문리뷰] Are We Ready For An Agent-Native Memory System?
댓글