[논문리뷰] Ko-WideSearch: A Korean Breadth-Search Benchmark for Exhaustive Set Enumeration by Web Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Minbyul Jeong
1. Key Terms & Definitions (핵심 용어 및 정의)
- Breadth-Search: 단일 정답을 찾는 기존의
Depth중심 벤치마크와 달리, 특정 엔티티에 종속된 전체 집합을 남김없이(Exhaustive) 나열하고 각 항목의 속성까지 완성해야 하는 과업입니다. - Set Enumeration: 대상 엔티티의 전체 멤버십을 식별하고, 이에 대응하는 테이블(표) 형태의 구조화된 데이터를 구축하는 과정입니다.
- Difficulty Tiers (Easy/Medium/Hard):
Table width(열 개수)와2-D composite key(행의 교차 조합)라는 두 가지 독립적인 구조적 변수를 조정하여 설정한 과업 난이도 체계입니다. - Normalization-Aware Comparator: 데이터 형식이 다르더라도 본질적인 의미가 동일할 경우(예: 단위 표기, 날짜 형식 차이) 이를 동일한 값으로 판정하는 평가 도구입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 웹 에이전트 벤치마크가 Depth(단일 정보 탐색) 위주로 편중되어 있으며, 다수의 속성을 포함한 구조적 집합을 완성하는 Breadth 능력에 대한 평가가 부족하다는 점을 지적합니다 [Figure 1]. 특히 한국어 웹 환경은 고유한 구조와 검색 관습을 가지고 있음에도 불구하고, 이러한 광범위한 정보 수집과 구조화 능력을 측정할 적절한 벤치마크가 부재합니다. 또한, 대규모로 정확한 'Gold' 정답셋을 구축하는 것은 비용이 많이 들고 검증이 어려워 기존 연구의 확장을 저해해 왔습니다. 저자들은 이러한 문제를 해결하기 위해 자동화된 생성 및 검증 파이프라인을 기반으로 한 한국어 Breadth-Search 벤치마크를 제안합니다.
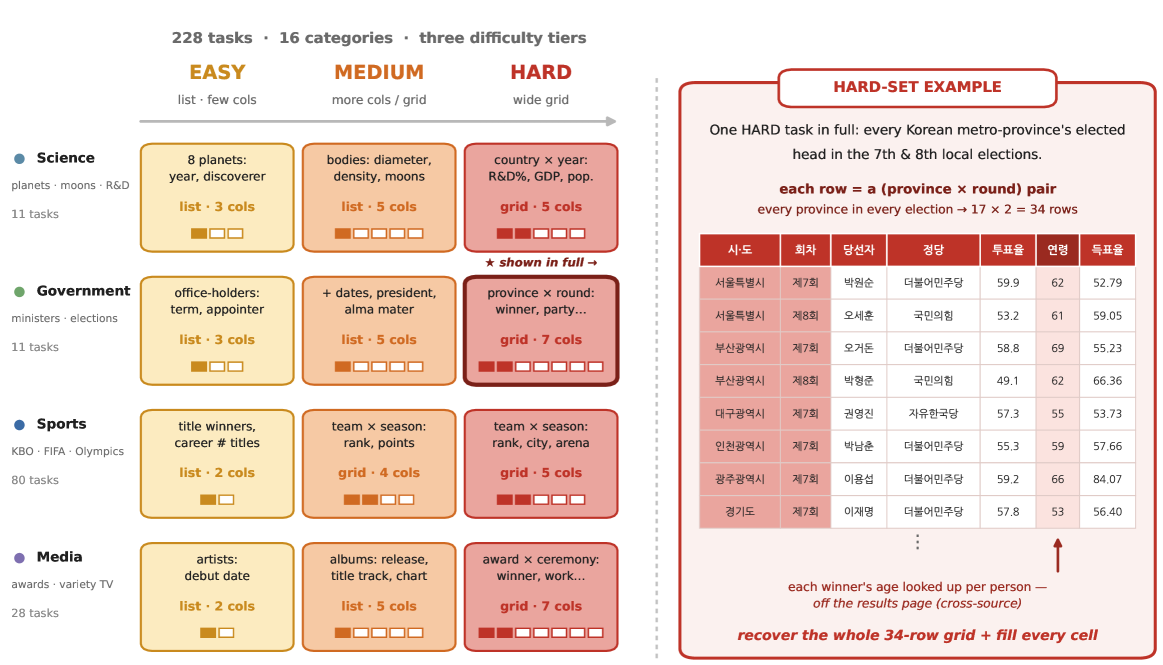
Figure 1 — Ko-WideSearch 예시 및 구성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 190개의 엔티티와 16개 카테고리에 걸쳐 228개의 테이블로 구성된 Ko-WideSearch를 제안하며, 이는 자동화된 build-and-verify 파이프라인을 통해 구축되었습니다 [Figure 1]. 제안된 파이프라인은 세 개의 독립적인 검증 게이트(비암기성, 완전성, 교차 소스 속성 검증)를 통과한 데이터만을 사용하여 정답셋의 신뢰성을 확보합니다. 모델 성능 평가는 Item-F1, Column-F1, Row-F1, 그리고 Table success 지표를 사용하여 엄격하게 수행됩니다 [Figure 3]. 실험 결과, 최신 Frontier 모델들조차 Item-F1(멤버십 복구)은 90% 이상을 기록하지만, Row-F1(전체 행 완성)은 50% 수준에 머무르는 '성능 격차'를 보였습니다 [Table 2]. 특히 난이도(Easy에서 Hard)가 올라갈수록 테이블 너비와 교차 키 복잡성으로 인해 Table success율이 급격히 하락하는 경향을 확인하였습니다 [Figure 4]. 또한, 더 많은 검색 횟수나 자원을 투입하는 것이 성능 향상으로 직결되지 않음을 입증하여, 현재 에이전트들이 검색 자체보다 구조화된 정보의 '완성' 단계에서 병목을 겪고 있음을 시사합니다 [Figure 5].
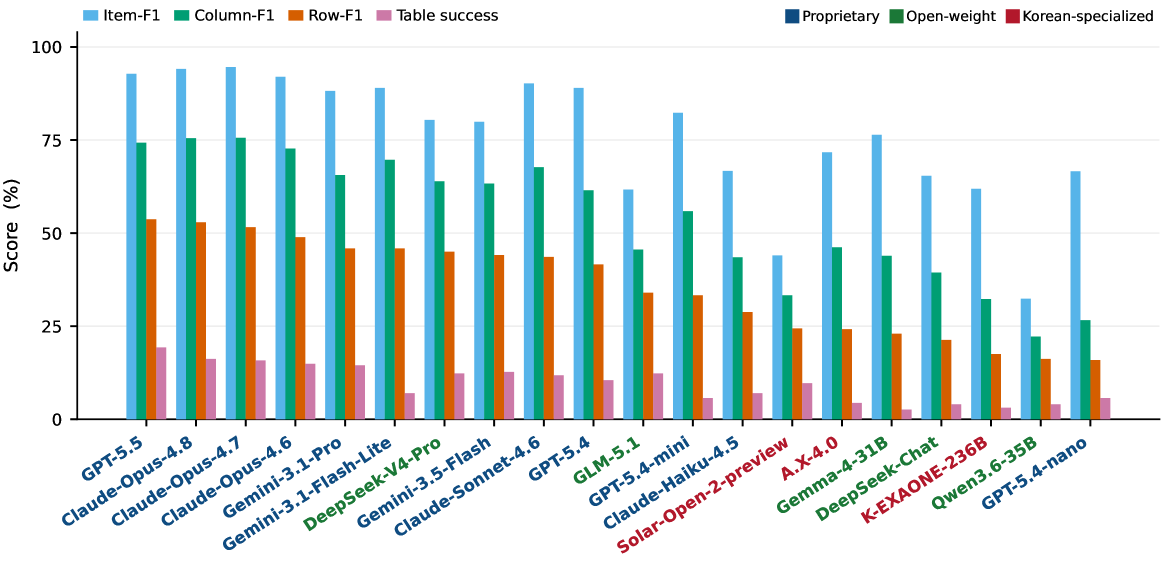
Figure 3 — 모델별 성능 지표 비교
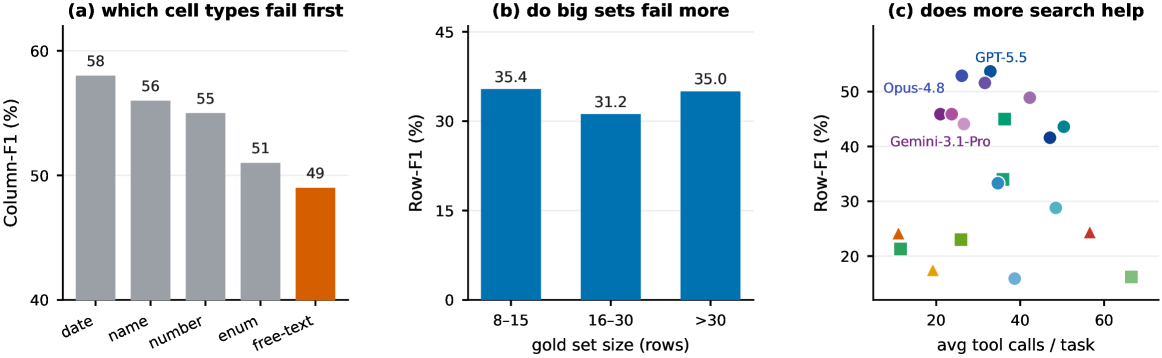
Figure 5 — 에이전트 실패 분석 및 상관관계
4. Conclusion & Impact (결론 및 시사점)
본 논문은 한국어 웹 에이전트의 구조적 정보 수집 및 집합 나열 능력을 정밀하게 측정하는 Ko-WideSearch를 구축하고, 에이전트들의 성능 한계를 명확히 규명하였습니다. 연구 결과는 단순히 검색 능력을 넘어, 방대한 정보를 테이블 형태로 구조화하고 무결성을 유지하는 것이 차세대 에이전트 개발의 핵심 과제임을 보여줍니다. 저자들은 모델의 표절이나 데이터 오염을 방지하기 위해 파이프라인과 스코어러를 오픈 소스로 배포하고, 데이터셋은 요청 기반으로 제공하는 전략을 취했습니다. 이 연구는 향후 한국어 AI 에이전트가 복잡한 웹 환경에서 더 고도화된 정보 통합 및 정확한 데이터 생성 능력을 갖추도록 유도하는 중요한 학술적 기반이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agentic Abstention: Do Agents Know When to Stop Instead of Act?
- [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
- [논문리뷰] Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
- [논문리뷰] SlimSearcher: Training Efficiency-Aware Web Agents via Adaptive Reward Gating
- [논문리뷰] Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] GBC: Gradient-Based Connections for Optimizing Multi-Agent Systems
- 현재글 : [논문리뷰] Ko-WideSearch: A Korean Breadth-Search Benchmark for Exhaustive Set Enumeration by Web Agents
- 다음글 [논문리뷰] Learning to Fold: prizewinning solution at LeHome Challenge 2026 (1st place online, 2nd offline)
댓글