[논문리뷰] V-Bridge: Bridging Video Generative Priors to Versatile Few-shot Image Restoration
링크: 논문 PDF로 바로 열기
저자: Shenghe Zheng, Junpeng Jiang, et al.
키워: Video Generation, Image Restoration, Prior Transfer, Few-shot Learning, Generative Models, Data Efficiency, Progressive Refinement, Foundation Models
1. Key Terms & Definitions
- Video Generative Models : 방대한 비디오 코퍼스(corpora)에서 학습되어 풍부한 structural, semantic, dynamic priors를 내재화한 large-scale 모델.
- Image Restoration : Deblurring, denoising, dehazing 등 degraded input에서 high-fidelity 이미지를 복원하는 low-level vision task.
- Few-shot Image Restoration : 극히 제한된 task-specific training data만으로 image restoration task를 수행하는 것.
- Progressive Generative Process : Image restoration을 degraded input에서 high-fidelity output으로 점진적으로 품질이 향상되는 step-wise quality evolution으로 재해석하여 비디오 생성과 유사하게 모델링하는 방법.
- Drift Correction Module : Pre-trained video models의 resolution bias를 완화하고 fine-grained texture 및 color fidelity를 향상시키기 위해 도입된 lightweight 보조 메커니즘.
2. Motivation & Problem Statement
기존 image restoration 방법론은 주로 task-specific modeling에 초점을 맞추어 각 degradation type별로 상당한 supervision(백만 개 이상의 샘플)을 요구했습니다. 이는 (a) Traditional Image Restoration `
![Figure 1: Left: Image restoration is formulated as progressive video generation with frame drift correction. Right: Leveraging video generative priors leads to stronger generalization under limited data compared to current image restoration method [25].](/paper-images/2026-03-16/2603.13089/figure_1.png) Figure 1: Left: Image restoration is formulated as progressive video generation with frame drift correction. Right: Leveraging video generative priors leads to stronger generalization under limited data compared to current image restoration method [25].
Figure 1: Left: Image restoration is formulated as progressive video generation with frame drift correction. Right: Leveraging video generative priors leads to stronger generalization under limited data compared to current image restoration method [25].
에서 볼 수 있듯이 task-specific 모델이 일반화하기 어렵다는 한계를 가집니다. 또한, (b) All-in-One Image Restoration [Figure 1]`과 같은 통합 모델도 여전히 방대한 training data가 필요하여 large-scale video generative models에 내재된 rich하고 transferable한 visual prior를 충분히 활용하지 못했습니다. 저자들은 이러한 한계를 극복하고, video generative models의 spatio-temporal consistency 및 generative priors를 leverage하여 data-efficient하면서도 versatile한 few-shot image restoration을 달성하는 새로운 접근 방식이 필요하다고 지적합니다.
3. Method & Key Results
저자들은 V-Bridge 라는 framework를 제안하며, image restoration을 static regression problem이 아닌 progressive generative process 로 재해석합니다. 이는 degraded image를 초기 상태(I_LQ)로, high-fidelity reconstruction을 최종 상태(I_HQ)로 간주하여 점진적인 품질 향상 궤적을 비디오 생성처럼 시뮬레이션합니다 [Figure 1] `
 Figure 2: Overview of the proposed pipeline. The upper part shows data construction and training, where paired low- and high-quality images are used to build pseudo-temporal sequences for progressive restoration learning. A progressive resolution training strategy is adopted to improve fine-grained detail modeling, and an auxiliary generative model is trained for final-frame correction. The lower part shows inference, where the model generates a restoration trajectory and uses the refined last frame as the final output.
Figure 2: Overview of the proposed pipeline. The upper part shows data construction and training, where paired low- and high-quality images are used to build pseudo-temporal sequences for progressive restoration learning. A progressive resolution training strategy is adopted to improve fine-grained detail modeling, and an auxiliary generative model is trained for final-frame correction. The lower part shows inference, where the model generates a restoration trajectory and uses the refined last frame as the final output.
`. 방법론은 다음과 같이 구성됩니다:
- Pseudo-Temporal Data Construction :
(I_LQ, I_HQ)쌍을 pseudo-temporal sequence(I_0, ..., I_T)로 변환합니다.I_0 = I_LQ,I_T = I_HQ로 설정하고 중간 프레임(I_t)은 선형 보간((1 - α_t)I_LQ + α_t I_HQ)을 통해 생성하여 temporally consistent한 supervision을 제공합니다. - Progressive Curriculum Training : coarse-to-fine 전략을 채택하여 training resolution을 점진적으로 증가시킵니다(예: 512 , 720 , 960 ). 이 접근 방식은 모델이 먼저 low-resolution에서 global structural coherence를 학습한 다음 high-frequency details를 refinement하도록 돕습니다.
- Drift Correction Module : Base video generation model의 output(
x^LR)과 ground-truth high-resolution image(x^HR) 간의 resolution gap을 보완하기 위해 short corrective trajectory를 학습하는 auxiliary modelg_φ를 도입합니다. 이는 pre-trained resolution bias를 완화하고 fine-grained texture 및 color fidelity를 향상시킵니다.
주요 실험 결과는 다음과 같습니다:
- Data Efficiency : V-Bridge는 기존 방법론들이 사용하는 training data의 2% 미만 (단 1,000 개의 multi-task training samples)으로 competitive하거나 심지어 superior한 성능을 달성합니다.
- FoundIR Benchmark : `
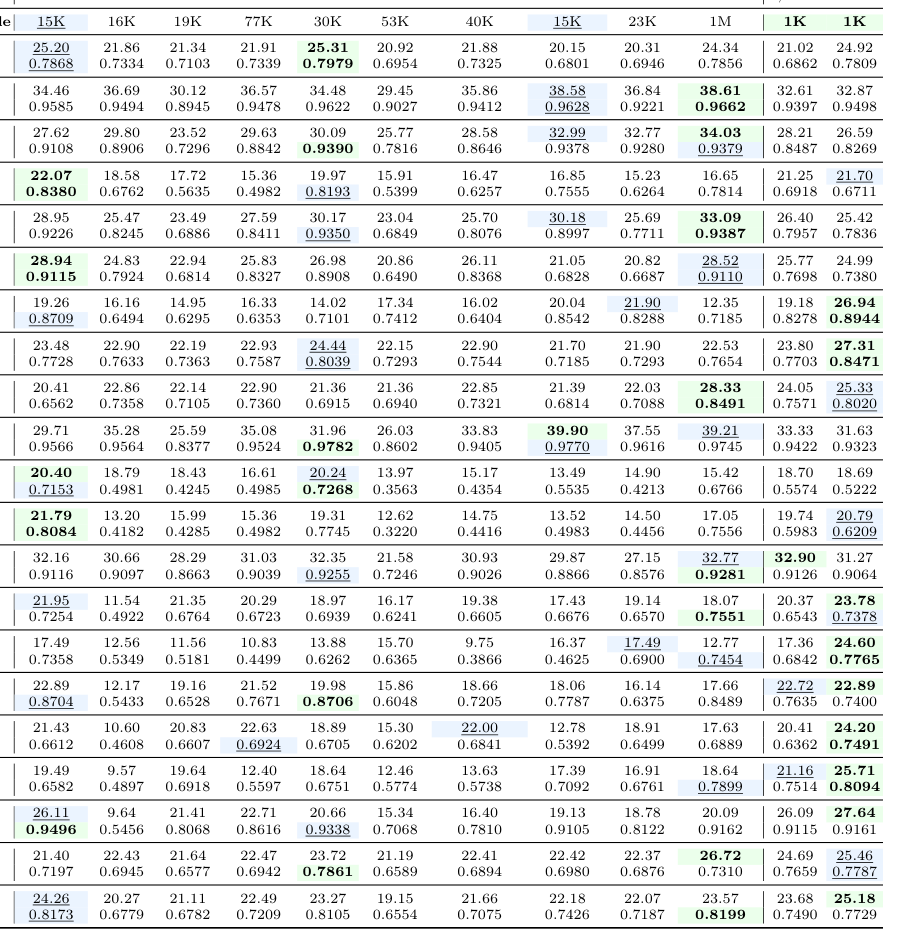 Table 1: Quantitative comparison (SSIM, PSNR, both higher is better) on the FoundIR test set. FoundIR-G denotes the generalist model of FoundIR and DC denotes Drift Correction. Underlining and boldface denote the second-best and best methods, respectively.
Table 1: Quantitative comparison (SSIM, PSNR, both higher is better) on the FoundIR test set. FoundIR-G denotes the generalist model of FoundIR and DC denotes Drift Correction. Underlining and boldface denote the second-best and best methods, respectively.
`에서 볼 수 있듯이, FoundIR test set에서 제안된 방법론(with drift correction)은 PSNR에서 1.4 dB 향상, SSIM에서 0.024 향상을 보여주며, FoundIR-Generalist (1M samples 학습)보다 여러 metrics에서 우수한 성능을 보입니다.
- Generalization Capability : V-Bridge는 눈 제거(snow removal) 와 같은 unseen task에도 효과적으로 일반화되며
[Figure 1][Table 6][Figure 9], 다양한 외부 벤치마크에서도 우수한 cross-dataset generalization을 입증했습니다. 이는 15배에서 1,000배 더 많은 데이터로 학습된 baseline보다 뛰어난 결과입니다. - Data Scaling Law :
[Table 5]에 따르면, training data 규모가 0.2K 에서 8K 로 증가함에 따라 성능이 일관되게 향상되어 강력한 data efficiency와 generalization capability를 보여줍니다.
4. Conclusion & Impact
본 연구는 pre-trained video generative models의 restoration capability를 few-shot training을 통해 unlock하는 V-Bridge framework를 성공적으로 제시했습니다. Image restoration을 progressive generative refinement process로 재해석하고 chain-like frame reasoning을 활용함으로써, video foundation models이 powerful하고 transferable한 visual prior로 기능할 수 있음을 보여주었습니다. 이 연구는 매우 적은 task-specific samples만으로 강력한 restoration capability를 활성화하여 video generative models이 video synthesis를 넘어 광범위한 잠재력을 가짐을 입증했습니다. 이는 low-level vision 분야에서 generative modeling과 전통적인 접근 방식 간의 경계를 허물고, general visual foundation models 의 새로운 디자인 패러다임을 제시하며, 최소한의 supervision으로 broad cross-domain adaptability를 가능하게 하는 통합 visual model을 향한 길을 열었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Think While Watching: Online Streaming Segment-Level Memory for Multi-Turn Video Reasoning in Multimodal Large Language Models
- 현재글 : [논문리뷰] V-Bridge: Bridging Video Generative Priors to Versatile Few-shot Image Restoration
- 다음글 [논문리뷰] VQQA: An Agentic Approach for Video Evaluation and Quality Improvement
댓글