[논문리뷰] VQQA: An Agentic Approach for Video Evaluation and Quality Improvement
링크: 논문 PDF로 바로 열기
저자: Yiwen Song, Tomas Pfister, et al.
키워: VQQA, Multi-agent framework, Prompt optimization, Vision-Language Models, Test-Time Training, Video generation, Semantic gradient, Closed-loop refinement
1. Key Terms & Definitions
- VQQA (Video Quality Question Answering) : Video Quality Question Answering의 약어로, 비디오 평가와 반복적인 프롬프트 개선을 위한 통합적인 Multi-Agent 프레임워크입니다.
- VLM (Vision-Language Model) : 시각 및 언어 정보를 모두 이해하고 처리할 수 있는 모델로, 본 논문에서는 비디오 평가의 Critique 생성 및 Holistic 평가에 활용됩니다.
- Semantic Gradient : VLM이 생성한 Critiques를 통해 제공되는 인간이 해석 가능한, 실행 가능한 피드백으로, Prompt를 최적화하는 데 사용됩니다.
- Test-Time Training (TTT) : 추론 시점에 모델을 정제하거나 적응시키는 최적화 패러다임으로, VQQA에서는 Prompt Optimization에 적용됩니다.
- Global Selection : Prompt Refinement 과정에서 Semantic Drift를 방지하기 위해 Original Prompt에 대한 Candidate Video Set의 Holistic 평가를 수행하고 최적의 비디오를 선택하는 메커니즘입니다.
2. Motivation & Problem Statement
비디오 생성 모델의 빠른 발전에도 불구하고, 복잡한 사용자 의도에 모델 Output을 맞추는 것은 여전히 큰 과제입니다. 사용자는 Compositional Errors, Temporal Inconsistencies, Physical Hallucinations 등 다양한 문제에 직면하며, 이는 반복적인 Prompt Engineering을 요구합니다. 기존 연구들은 이러한 문제를 해결하는 데 한계를 보입니다. 전통적인 평가 Metric (예: Fréchet Video Distance (FVD) , Inception Score (IS) )은 기본적인 시각적 분포를 측정하지만, 복잡한 Compositional Alignment를 놓치고 Actionable Feedback을 제공하지 못합니다. Vision-Language Models (VLMs) 기반의 평가 방식 (예: VQAScore , VideoScore2 )은 Passive Observer 역할을 하여 새로운 Task에 적응하거나 Actionable Feedback을 제공하는 유연성이 부족합니다. 또한, 기존 Test-Time Optimization 방법론은 계산 비용이 높거나 (예: VISTA 의 Pairwise Tournaments), 모델 Internal에 대한 White-box Access를 필요로 하여 (예: Video-TTT , EvoSearch ) Commercial API와 호환되지 않는 단점이 있습니다. 이러한 한계점들로 인해 시각적 결함을 진단하고 Black-box Natural Language Interface를 통해 비디오를 반복적으로 개선할 수 있는 해석 가능한 Closed-loop 시스템에 대한 절실한 필요성이 제기됩니다.
3. Method & Key Results
저자들은 이러한 문제를 해결하기 위해 VQQA 라는 Unified Multi-Agent Framework를 제안합니다. VQQA는 동적인 Question-Answering Paradigm을 활용하여 비디오 평가를 Passive Metric에서 Actionable Feedback으로 전환합니다. VQQA는 세 가지 전문 Agent를 통해 작동합니다. 첫째, Question Generation (QG) Agent 는 비디오, Prompt 및 Conditions를 분석하여 Video-Prompt Alignment , Visual Quality , Condition Fidelity 의 세 가지 차원에 걸쳐 Targeted Visual Queries를 동적으로 생성합니다. 둘째, Question Answering (QA) Agent 는 생성된 비디오를 Queries에 대해 평가하고, 질문당 0-100 점 범위의 Normalized Scores를 할당하여 Critical Visual Flaws의 Detailed Diagnostic Map을 구성합니다. 셋째, Prompt Refinement (PR) Agent 는 낮은 점수를 받은 QA 쌍을 Semantic Gradient 로 사용하여 다음 Iteration을 위한 Optimized Prompt ( pt+1 )를 생성하며, 이는 여러 Localized Error를 동시에 완화합니다.
Semantic Drift 를 방지하기 위해 VQQA는 Global Selection 메커니즘을 사용합니다. Global VLM Rater 는 Candidate Set V의 각 비디오에 Global Score (GS) 를 할당하고, Original Prompt와 가장 잘 일치하는 비디오 v*를 선택합니다
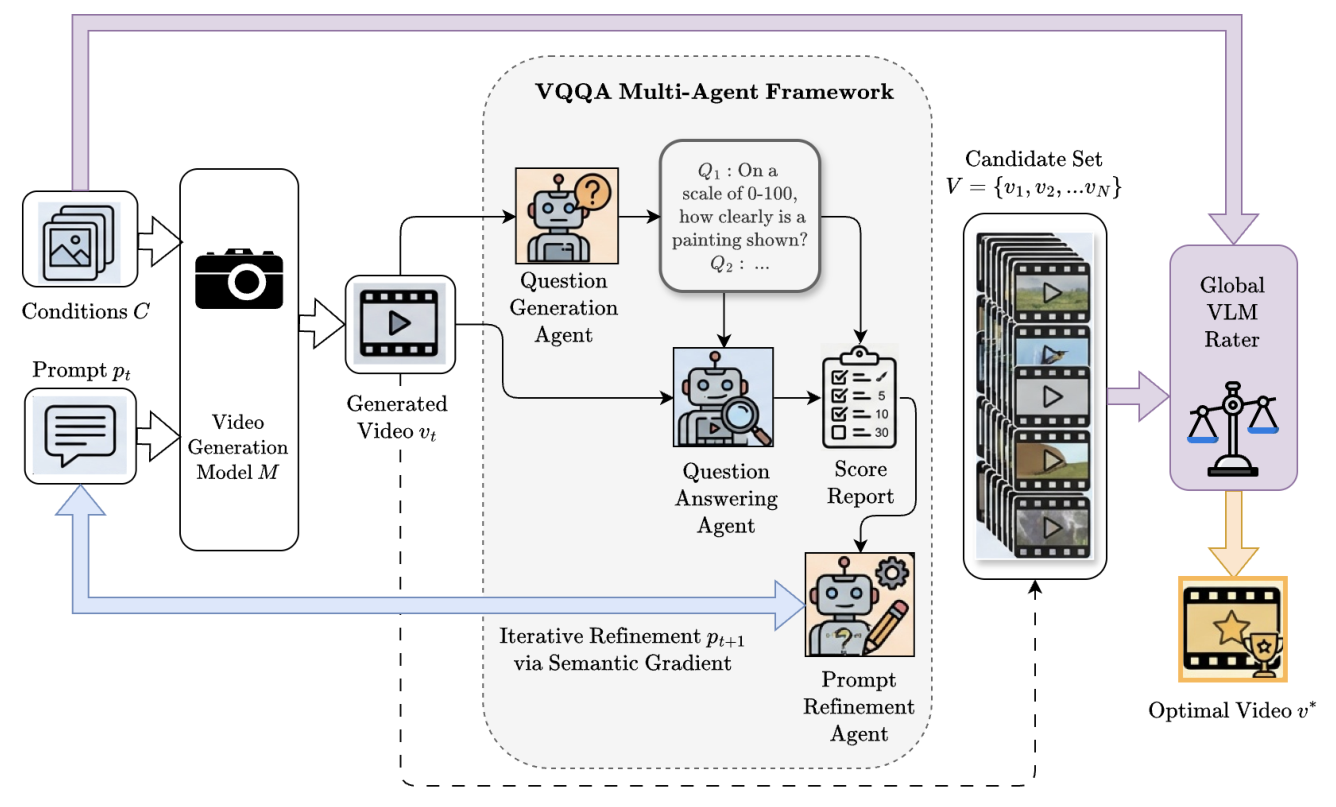 Figure 3: The VQQA framework: Given generation conditions C and a prompt pt, the model M produces a video vt. The multi-agent framework uses a Question Generation (QG) agent to formulate visual queries Q and a Question Answering (QA) agent to evaluate the video and produce a score report. These outputs inform the Prompt Refinement (PR) agent, which uses semantic gradient to update the prompt for the next iteration. Finally, a Global VLM Rater assesses the candidate set of generated videos against the original conditions to select the optimal video v.*
Figure 3: The VQQA framework: Given generation conditions C and a prompt pt, the model M produces a video vt. The multi-agent framework uses a Question Generation (QG) agent to formulate visual queries Q and a Question Answering (QA) agent to evaluate the video and produce a score report. These outputs inform the Prompt Refinement (PR) agent, which uses semantic gradient to update the prompt for the next iteration. Finally, a Global VLM Rater assesses the candidate set of generated videos against the original conditions to select the optimal video v.*
. 또한, Inference Cost와 Quality의 균형을 맞추기 위해 Target Satisfaction 또는 Performance Saturation 을 기반으로 하는 Dynamic Stopping Criterion을 적용하여 효율적인 종료를 보장합니다
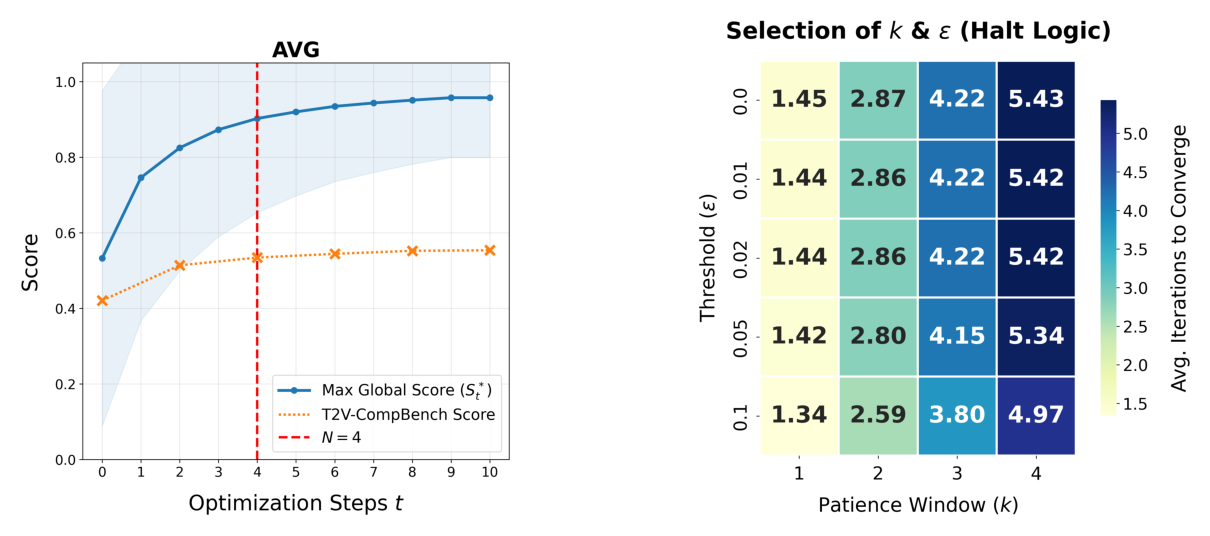 Figure 4: Convergence analysis of VQQA on T2V-CompBench. Evaluations are performed for CogVideoX-5B generations using Gemini-3-Pro. (a) Correlations between the maximum global score S and the T2V-CompBench metric across optimization steps. The blue shaded region indicates ±1 standard deviation of S* across the 1400 evaluated samples. The detailed performance breakdown for each individual category is provided in Appendix C.4. (b) Sensitivity analysis of average iterations to converge given the patience window k and saturation threshold ε (Equation (8)).*
Figure 4: Convergence analysis of VQQA on T2V-CompBench. Evaluations are performed for CogVideoX-5B generations using Gemini-3-Pro. (a) Correlations between the maximum global score S and the T2V-CompBench metric across optimization steps. The blue shaded region indicates ±1 standard deviation of S* across the 1400 evaluated samples. The detailed performance breakdown for each individual category is provided in Appendix C.4. (b) Sensitivity analysis of average iterations to converge given the patience window k and saturation threshold ε (Equation (8)).*
. VQQA는 Model-Agnostic하게 설계되어 Task-Specific Fine-tuning 없이 다양한 모델과 Modalities에 일반화될 수 있습니다.
주요 정량적 결과 :
- T2V-CompBench 평가에서
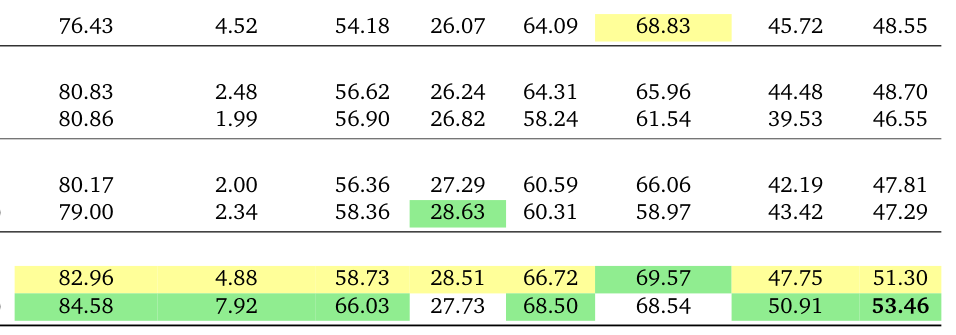 Table 1: T2V-CompBench evaluation results on CogVideoX-5B. Performance is reported using N = 5 for Best-of-N strategy, and 4 optimization rounds for VQQA. Vanilla generation results are obtained from the official leaderboard. Best and second-best scores are highlighted in green and yellow. All numbers are percentages.
Table 1: T2V-CompBench evaluation results on CogVideoX-5B. Performance is reported using N = 5 for Best-of-N strategy, and 4 optimization rounds for VQQA. Vanilla generation results are obtained from the official leaderboard. Best and second-best scores are highlighted in green and yellow. All numbers are percentages.
, VQQA 는 Gemini-3-Pro 를 사용하여 53.46% 의 최고 평균 점수를 달성했으며, Vanilla Generation 대비 +11.57% , 가장 강력한 Baseline인 VQAScore 대비 +4.76% 의 Absolute Improvement를 보였습니다. 특히 Consistent-Attribute ( +22.94% ), Spatial Understanding ( +14.31% ), Numeracy ( +13.85% ) 카테고리에서 상당한 개선을 이루었습니다.
- VBench2 벤치마크에서는 [Table 2], VQQA 의 Gemini-3-Pro 변형이 50.41% 로 가장 높은 Total Score를 기록하여, Vanilla Baseline 대비 +8.43% , VQAScore 대비 +3.46% Absolute Increase를 나타냈습니다.
- VBench-I2V 벤치마크 [Table 3]에서 VQQA 는 Gemini-3-Pro 와 함께 모든 평가 축에서 최고 성능을 달성했으며, Vanilla Generation 대비 +1.24% , Best-of-N Baseline 대비 +0.23% 개선되었습니다. 또한, 평균 1.6 Iterations 만에 Task의 Stopping Criterion을 만족하며 효율성을 입증했습니다.
- Global Selection 에 대한 Ablation Study [Figure 5] 결과, Global Selection을 생략하면 Semantic Drift로 인해 전체 평균 점수가 1.02% 감소함을 확인했습니다.
- Inference Cost 분석 [Table 7]에서는 VQQA 가 T2V-CompBench (k=0) 에서 평균 1.245 Iterations 만에 수렴하여 약 7.23 회의 VLM Calls 를 필요로 했으며, 이는 표준 Best-of-5 (N=5) Baseline과 유사한 수준의 Inference Footprint입니다.
4. Conclusion & Impact
본 논문은 비디오 생성 모델의 Passive Evaluation을 Active Closed-loop Refinement Process로 전환하는 새로운 Multi-Agent Framework인 VQQA 를 소개합니다. VQQA 는 동적으로 생성되는 Visual Questions와 Vision-Language Model (VLM) Critiques를 Semantic Gradient 로 활용하여 Black-box Natural Language Interface 를 통해 정밀하고 반복적인 Prompt Optimization을 가능하게 합니다. Text-to-Video (T2V) 및 Image-to-Video (I2V) Task 모두에 걸친 광범위한 평가는 VQQA 가 강력한 Baseline 대비 적은 Iteration으로 상당한 개선을 이끌어내며, Open-Weights 및 Proprietary Model 모두에 걸쳐 Seamless하게 일반화됨을 입증합니다. 궁극적으로 VQQA 는 복잡한 인간의 의도에 시각적 생성 모델을 Aligning하기 위한 Scalable, Task-Agnostic Solution을 제공하여, 더욱 Controllable하고 Interpretable한 AI-driven 콘텐츠 생성의 길을 열었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] V-Bridge: Bridging Video Generative Priors to Versatile Few-shot Image Restoration
- 현재글 : [논문리뷰] VQQA: An Agentic Approach for Video Evaluation and Quality Improvement
- 다음글 [논문리뷰] Video Streaming Thinking: VideoLLMs Can Watch and Think Simultaneously
댓글