[논문리뷰] VenusBench-Mobile: A Challenging and User-Centric Benchmark for Mobile GUI Agents with Capability Diagnostics
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yichen Gong, Zhuohan Cai, Sunhao Dai, Yuqi Zhou, Zhangxuan Gu, Changhua Meng, Shuheng Shen
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- VenusBench-Mobile : 모바일 GUI 에이전트의 일반적인 목적과 사용자 중심의 상호작용 능력을 평가하기 위해 설계된 온라인 벤치마크.
- PUDAM : 모바일 GUI 에이전트의 핵심 역량을 5가지 차원(Perception, Understanding, Decision, Action, Memory)으로 분류한 역량 분류 체계.
- Stability Pass Rate (SPR) : 다양한 환경 변화(언어, 레이아웃 등) 속에서도 에이전트가 동일한 작업을 일관되게 수행할 수 있는지 측정하는 지표.
- MLLM-as-a-Judge : 사전 훈련된 멀티모달 언어 모델을 활용하여 에이전트의 작업 성공 여부를 시각적 및 의미론적으로 자동 검증하는 평가 방식.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존 모바일 GUI 에이전트 벤치마크들이 App-centric이고 작업이 동질적이라는 한계점을 해결하고자 한다. 기존의 온라인 벤치마크들은 특정 앱의 기능적 완성도에만 초점을 맞추어, 실제 사용자가 모바일 환경에서 겪는 복잡하고 의도 중심적인 시나리오를 반영하지 못한다. 특히, 현재의 평가는 에이전트의 성공률(Success Rate)이라는 거친 지표에만 의존하여, 어떤 지점에서 성능 저하가 발생하는지에 대한 진단 능력이 부족하다.
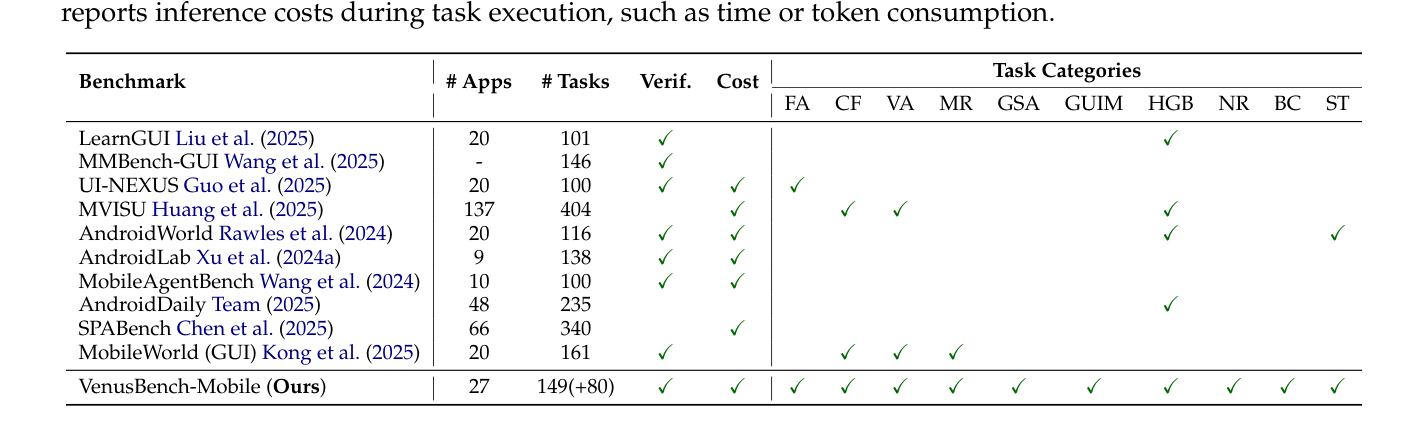
에 나타난 바와 같이, 기존 연구들은 실질적인 사용자 니즈와 환경적 변동성을 충분히 포괄하지 못하고 있어, 실제 환경에서의 배치 가능성을 판단하기 어렵다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 사용자 의도 중심의 10가지 범주, 149개의 작업, 그리고 80개의 환경 변이를 포함하는 VenusBench-Mobile 을 제안한다. 에이전트의 실패 원인을 세밀하게 분석하기 위해 PUDAM 역량 분류 체계를 도입하여 각 작업의 난이도를 4단계(Level 1-4)로 구분하였다.
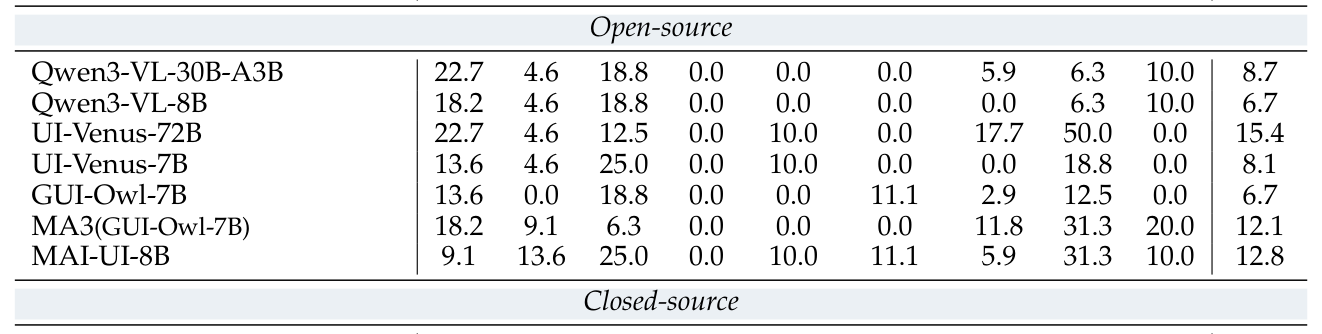
에 따르면, SOTA 모델인 Gemini-3-Pro 가 36.9% 의 성공률을 기록한 반면, 대부분의 오픈소스 모델은 15% 미만의 낮은 성공률을 보여 기존 벤치마크 대비 난도가 대폭 상승했음을 확인하였다. 특히
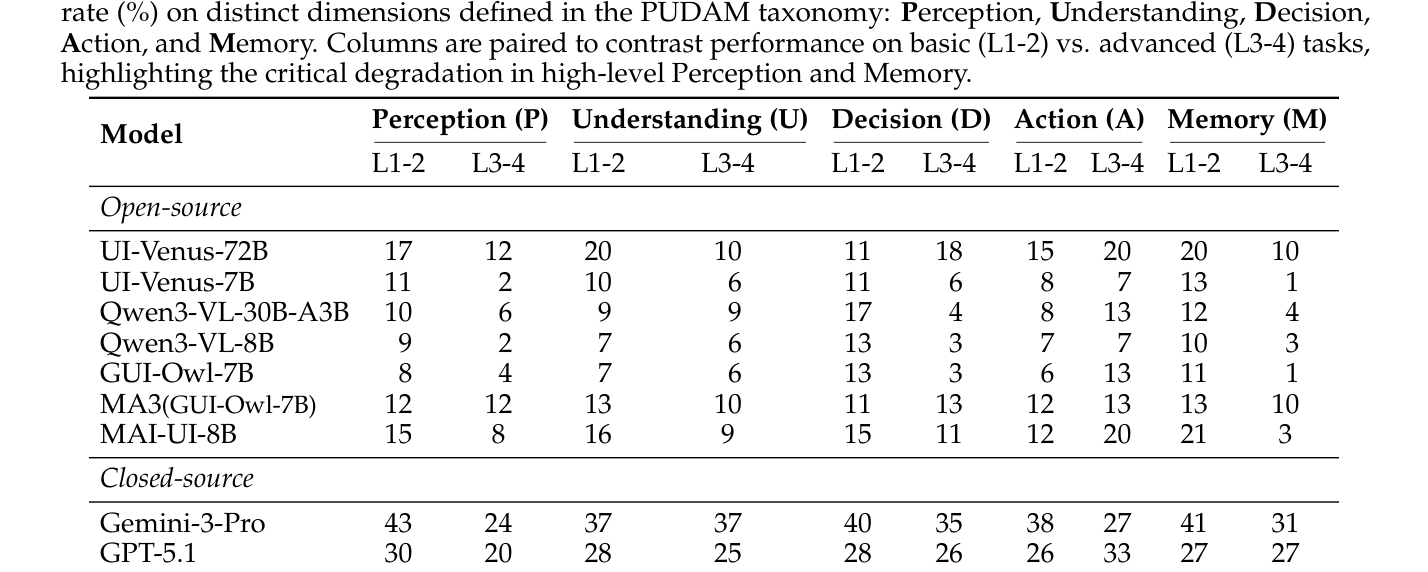
의 진단 분석 결과, 고수준(L3-4) 작업으로 갈수록 Perception 과 Memory 역량에서 급격한 성능 저하가 발생하며, 이는 단순한 모델 크기 확장만으로는 해결하기 어려운 근본적인 병목 현상임을 증명하였다. 또한, 환경 변화에 따른 안정성을 측정한 결과, 대부분의 모델이 0%에 가까운 SPR 을 기록하여 현실 환경에서의 높은 취약성을 드러냈다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 모바일 GUI 에이전트의 평가 패러다임을 기능적 완수에서 사용자 중심의 역량 진단으로 전환하였다. VenusBench-Mobile 을 통해 Perception, Memory 등의 핵심 병목을 식별함으로써, 향후 에이전트 아키텍처가 나아가야 할 기술적 방향성을 제시하였다. 본 벤치마크는 학계와 산업계가 보다 견고하고 신뢰할 수 있는 일반 목적의 모바일 어시스턴트를 개발하는 데 필수적인 평가 가이드라인 역할을 수행할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Can Agent Conquer Web? Exploring the Frontiers of ChatGPT Atlas Agent in Web Games
- [논문리뷰] AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
- [논문리뷰] Confidence-Aware Tool Orchestration for Robust Video Understanding
- [논문리뷰] MobileForge: Annotation-Free Adaptation for Mobile GUI Agents with Hierarchical Feedback-Guided Policy Optimization
- [논문리뷰] DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
Review 의 다른글
- 이전글 [논문리뷰] Tunable Soft Equivariance with Guarantees
- 현재글 : [논문리뷰] VenusBench-Mobile: A Challenging and User-Centric Benchmark for Mobile GUI Agents with Capability Diagnostics
- 다음글 [논문리뷰] Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
댓글