[논문리뷰] Bernini: Latent Semantic Planning for Video Diffusion
링크: 논문 PDF로 바로 열기
저자: Bernini Team, Chenchen Liu, Junyi Chen, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM-based Planner: MLLM의 강력한 추론 능력을 활용하여 영상의 타겟 시맨틱 정보를 ViT 임베딩 공간에서 예측하는 모듈입니다.
- DiT-based Renderer: planner가 생성한 시맨틱 가이던스와 텍스트, VAE 피처를 기반으로 실제 픽셀을 합성하는 Flow Matching 기반의 생성 모델입니다.
- SA-3D RoPE (Segment-Aware 3D Rotary Positional Embedding): 다양한 시각적 입력(소스 영상, 참조 이미지 등)을 하나의 통합된 시퀀스로 처리할 때, 각 세그먼트의 정체성을 구분하기 위해 3D RoPE에 위상 변조를 추가한 기법입니다.
- ViT Embedding Space: MLLM과 DiT 사이의 시맨틱 인터페이스로, 저자들이 연구한 'Latent Semantic Planning'의 핵심이 되는 중간 표현 공간입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 현대의 MLLM과 영상 확산 모델(Diffusion Model)이 각각 고도의 추론 능력과 사실적 합성 능력을 갖추고 있음에도 불구하고, 이들을 효과적으로 통합하는 프레임워크가 부족하다는 점에 주목합니다. 기존 연구들은 시맨틱 가이던스를 단순히 텍스트 토큰이나 단순한 쿼리 형태로만 전달하여 복잡한 영상 편집 및 생성 작업에서의 정밀한 제어에 한계를 보였습니다. 저자들은 시맨틱(의도)과 디테일(픽셀 정보)을 분리하여 MLLM이 시맨틱 플래닝을 수행하고 확산 모델이 렌더링을 담당하는 새로운 분업 체계를 제안합니다 [Figure 3].
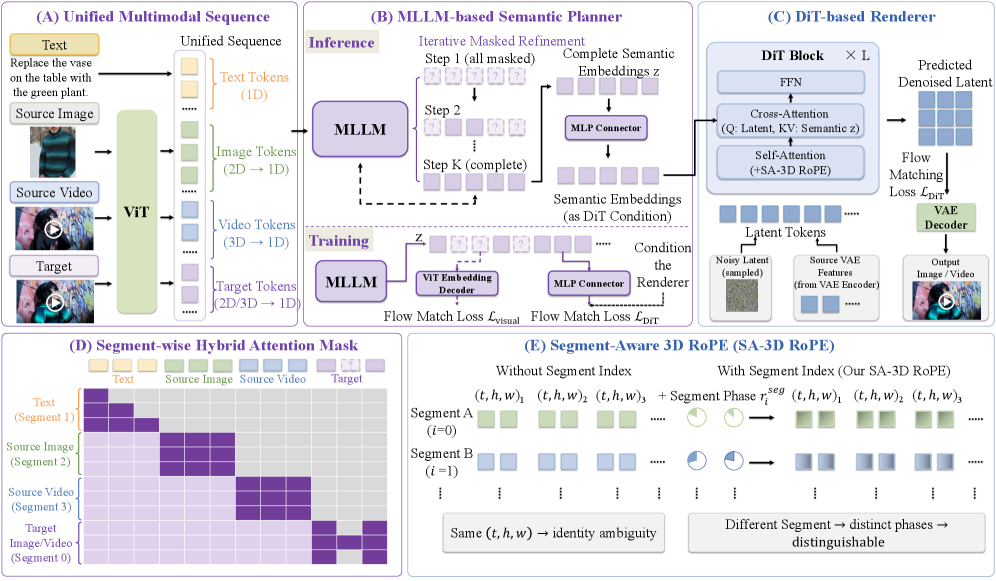
Figure 3 — Bernini 전체 아키텍처
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 MLLM이 타겟 시맨틱을 ViT 임베딩 공간에서 직접 예측하고, DiT 기반의 렌더러가 이를 기반으로 영상을 합성하는 Bernini 프레임워크를 개발하였습니다. MLLM에는 복잡한 편집 의도를 더 잘 반영하기 위해 Chain-of-Thought (CoT) 추론 기법을 도입하였으며, 여러 visual input을 구분하기 위해 SA-3D RoPE를 설계하였습니다 [Figure 3]. 또한 방대한 멀티태스크 데이터셋을 구축하여 모델의 일반화 능력을 극대화했습니다 [Figure 4, 6]. 실험 결과, Bernini는 영상 편집 및 생성 벤치마크인 Bernini-Bench에서 기존 SOTA 모델들(Kling O3, Wan2.7 등)을 상회하는 성능을 보였습니다. 특히 Bernini-V2V 태스크에서 종합 점수 3.49를 기록하며 Wan2.7(3.30) 대비 우위를 점했고, Subject-to-Video 생성의 핵심 지표인 FaceSim 점수에서 78.20을 기록하며 Kling O3(57.20)보다 월등한 identity 보존 성능을 입증했습니다 [Table 6, Table 12].
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 시맨틱 플래닝과 픽셀 렌더링을 분리함으로써 두 모델의 사전 학습된 강점을 유지하면서도 효율적인 고성능 영상 생성/편집 시스템을 구축할 수 있음을 입증했습니다. 이 연구는 MLLM의 추론 능력이 시각적 생성 결과에 직접적인 영향을 미칠 수 있음을 보여주었으며, 향후 고도의 이해력이 요구되는 영상 편집 및 복합적인 생성 인터페이스 발전에 중요한 초석이 될 것으로 기대됩니다. 다만, 모델의 성능이 기반이 되는 MLLM과 DiT의 기초 체력에 의존한다는 점은 향후 개선이 필요한 한계점으로 언급됩니다.
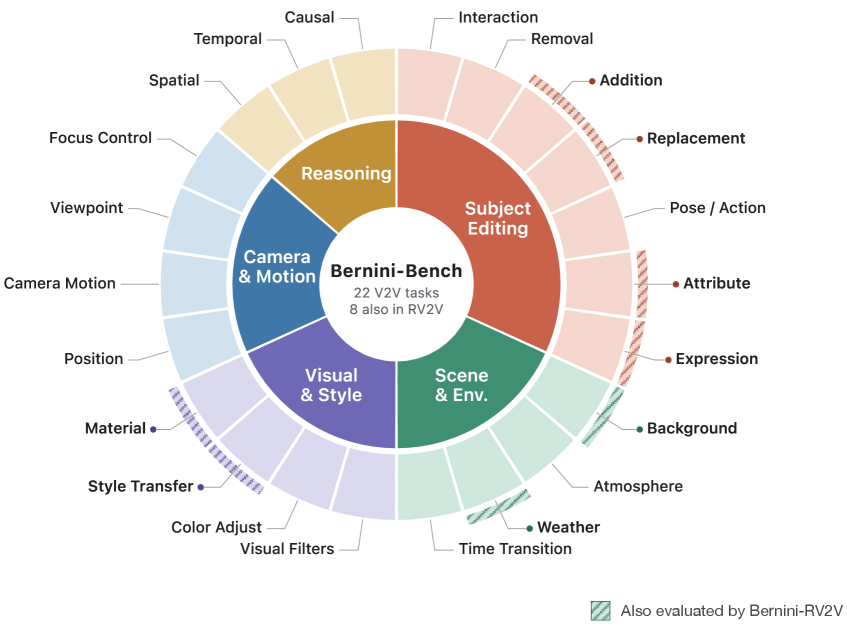
Figure 12 — Bernini-Bench 구성 개요

Figure 14 — SoTA 모델 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LooseControlVideo: Directorial Video Control using Spatial Blocking
- [논문리뷰] Optical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text
- [논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
- [논문리뷰] LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
- [논문리뷰] Faithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] ACC: Compiling Agent Trajectories for Long-Context Training
- 현재글 : [논문리뷰] Bernini: Latent Semantic Planning for Video Diffusion
- 다음글 [논문리뷰] ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning
댓글