[논문리뷰] From Pixels to Words -- Towards Native One-Vision Models at Scale
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haiwen Diao, Jiahao Wang, Penghao Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- NEO-ov: 외부 visual encoder나 어댑터 없이 raw pixel과 word를 직접 처리하여 단일 백본에서 학습되는 Native vision-language foundation model입니다.
- Native Modeling: visual signal을 LLM 외부에서 압축하는 대신, patch-level 토큰을 통해 end-to-end로 LLM 내부에서 직접 모델링하는 아키텍처 접근 방식입니다.
- Unified Visual Serialization: 단일 이미지, 다중 이미지, 비디오 프레임을 동일한 시퀀스 구조로 통합하여 시공간적 관계를 모델이 직접 학습하도록 설계한 방식입니다.
- THW-decoupled Attention: temporal(T), spatial height(H), spatial width(W)의 독립적인 head 차원을 할당하여 시공간적 정보를 정교하게 모델링하는 Attention 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 modular VLM이 가진 복잡한 파이프라인과 파편화된 visual-language 정보를 해결하기 위해 단일화된 Native one-vision 아키텍처를 제안한다. 기존 연구들은 강력한 성능에도 불구하고 외부 visual encoder를 통해 시각 정보를 사전에 압축하기 때문에, 세밀한 spatial 구조나 temporal 역학 관계를 포착하는 데 한계가 있다. 또한, 이미지와 비디오 처리 모듈이 분리되어 있어 범용적인 one-vision 모델 구축을 가로막는 고착화된 아키텍처적 제약이 존재한다. [Figure 1]
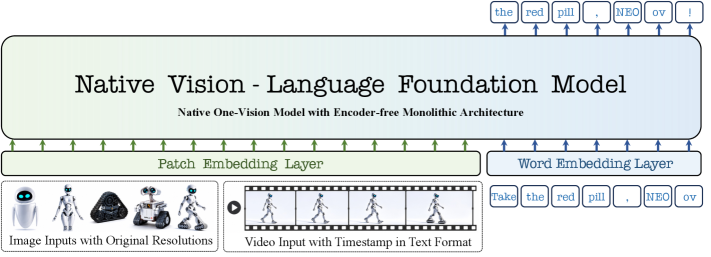
Figure 1 — NEO-ov 모델 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 encoder-free 기반의 NEO-ov 프레임워크를 제안하여, raw visual input에서 pixel-word correspondence를 직접 학습하는 monolithic Backbone을 구성하였다. 본 모델은 Unified Visual Serialization과 Unified Spatial-Temporal Attention을 통해 이미지부터 비디오까지의 모든 시각적 입력을 동일한 Representation 공간에서 처리한다 [Figure 2]. 특히, 학습 과정은 Pre-training, Mid-training, Supervised Fine-tuning의 3단계로 구성되어 모델의 범용성을 극대화한다 [Figure 3].
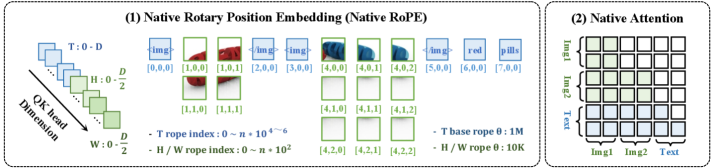
Figure 2 — 시공간 Attention 구조

Figure 3 — 3단계 학습 레시피 개요
실험 결과, NEO-ov는 2B 및 8B 파라미터 규모에서 기존의 Native VLM들을 압도하는 성능을 기록했다. 특히 MMMU, HallB, InfoVQA와 같은 reasoning-intensive 벤치마크에서 뛰어난 성능을 보이며, 동일한 규모의 modular counterparts와 대등한 수준에 도달했다 [Table 1]. 또한, Spatial Intelligence 벤치마크(예: VSI-Bench, Mindcube)에서 기존 spatial-specialist 모델들을 상회하는 결과를 달성하여, 일반적인 Native 구조로도 고도의 공간적 추론이 가능함을 입증했다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 단일 백본에서 단일 이미지, 다중 이미지, 비디오, 공간적 지능까지 모두 처리하는 NEO-ov를 통해 Native multimodal 모델링의 가능성을 확장했다. 이 연구는 modular VLM의 구조적 한계를 극복하고 모델 간의 경계를 없앰으로써 더욱 효율적이고 범용적인 multimodal Foundation Model을 위한 새로운 방향을 제시한다. 학계와 산업계에서는 본 모델을 통해 더 단순하면서도 파워풀한 end-to-end multimodal 아키텍처 연구가 가속화될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] See like a Robot: Robot-Centric Pointmaps for Vision-Language-Action Models
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence
- [논문리뷰] SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
- [논문리뷰] Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
Review 의 다른글
- 이전글 [논문리뷰] Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
- 현재글 : [논문리뷰] From Pixels to Words -- Towards Native One-Vision Models at Scale
- 다음글 [논문리뷰] GE-Sim 2.0: A Roadmap Towards Comprehensive Closed-loop Video World Simulators for Robotic Manipulation
댓글