[논문리뷰] Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
링크: 논문 PDF로 바로 열기
저자: Kewei Zhang, Jin Wang, Sensen Gao, Chengyue Wu, Yulong Cao, Songyang Han, Boris Ivanovic, Langechuan Liu, Marco Pavone, Song Han, Daquan Zhou, Enze Xie
1. Key Terms & Definitions
- VLM (Vision-Language Model): Vision-Language-Action (VLA) 모델로 확장되어, 시각 및 언어 입력을 기반으로 자율주행 시나리오에서 인지, 추론 및 계획을 통합하는 모델을 지칭합니다.
- Block-Diffusion: 출력을 고정된 크기의 Block으로 분할하여 각 Block 내에서는 Bidirectional Attention을, Block 간에는 Causal Attention을 적용하여 KV-Cache 재활용을 가능하게 하는 Diffusion Model의 한 형태입니다.
- Scaffold: 자율주행 VLA 모델의 JSON 형식 출력에서 Schema에 의해 결정되는 구조적이고 확정적인 토큰(예: Key, 괄호, 구두점)을 의미하며, 이는 예측할 필요 없이 미리 채워져 Inference Workload를 줄입니다.
- Scaffold Speculative Decoding (SS):
Block-DiffusionVLM에서Scaffold토큰을 자동으로 Accept하고,MDM (Masked Diffusion Modeling)Head가 Value 토큰을 병렬로 Draft한 후,AR (Autoregressive)Head가 Draft를 순차적으로 Verify하여 Inference Latency를 크게 줄이는 Decoding 기법입니다. - Latency: 데이터 전송 지시 후 전송이 시작되기까지 걸리는 시간으로, 실시간 자율주행 시스템에서
Inference Efficiency의 중요한 지표입니다. - Throughput: 초당 처리되는 토큰 수(
Tokens Per Second, TPS)를 나타내며,Latency와 함께Inference Efficiency를 평가하는 핵심 지표입니다.
2. Motivation & Problem Statement
본 논문은 End-to-End Autonomous Driving을 위한 Vision-Language-Action (VLA) 모델이 직면한 High-Fidelity Trajectory Planning과 Efficient Inference 간의 상충 관계 문제를 해결하고자 합니다. 기존 Autoregressive (AR) VLA 모델은 Edge Hardware에서 Memory-Bandwidth-Bound이며, Exposure Bias Drift에 취약하여 5초 계획의 초기 단계에서 발생하는 작은 오류가 물리적으로 비현실적인 기동으로 증폭될 수 있는 한계가 있습니다. 또한 Batch Size 1에서 Single-Token Decoding은 GPU Memory Bandwidth에 제약을 받아 효율적인 차량 내 배포를 어렵게 합니다. Figure 1은 기존 VLA 패러다임의 한계를 명확히 보여줍니다. 반면, Full-Sequence Diffusion 기반 VLM은 KV-Cache Reuse를 막고, Perceive-Then-Plan Causality를 위반하는 Logical Leakage 문제를 발생시켜 End-to-End Latency가 AR Baseline보다 훨씬 높습니다. 이 연구는 이러한 AR 및 Diffusion 기반 VLA의 비효율성과 정확도 문제를 동시에 해결하여 Real-Time On-Vehicle Deployment의 요구사항을 충족하는 것을 목표로 합니다.
3. Method & Key Results
저자들은 Autonomous Driving의 Structured JSON-Like Outputs 특성을 활용하여 Block-Diffusion VLA인 Fast-dDrive를 제안합니다. 이 방법론은 출력의 구조적 토큰을 Section Scaffold로 고정하고, Semantic Unit 내에서 Bidirectional Refinement를 수행하며, Unit 간에는 엄격한 Causal Ordering을 강제합니다. Figure 2는 Fast-dDrive의 Training Pipeline을 보여주며, Structured JSON Output이 4개의 Semantic Section으로 분해되고 Template Token이 Frozen Scaffold로 사용됨을 나타냅니다. Fast-dDrive는 Section-Aware Structured Diffusion (SASD), Scaffold Speculative Decoding (SS), 그리고 Shared-Prefix Multi-Trajectory Rollouts와 같은 주요 구성 요소를 포함합니다.
SASD는 Scaffold-Based Training Scheme으로, Block Boundary를 Semantic Section과 일치시키고, Safety-Critical Planning을 우선시하는 Section-Weighted Cross-Entropy와 Section-Adaptive Beta Noise Schedule을 사용합니다. 이는 100% Structural Correctness를 보장하고 Denoising Workload를 약 30% 줄이며, Inference Overhead는 없습니다. Scaffold Speculative Decoding (SS)는 Scaffold Token을 자동으로 Accept하고, MDM Head가 Value Token을 병렬로 Draft한 후 AR Head가 Draft를 순차적으로 Verify하여 AR-Equivalent Quality를 유지하면서 Latency를 현저히 낮춥니다. Figure 3은 Scaffold Speculative Decoding의 작동 방식을 시각적으로 설명합니다. Shared-Prefix Multi-Trajectory Rollouts는 Deterministic Prefix를 한 번 디코딩한 후 Trajectory Section에만 Stochasticity를 도입하여 Shared KV Cache에서 여러 Trajectory Rollouts를 Fork하고 평균화함으로써 Prediction Variance를 효과적으로 억제합니다.
실험 결과, Fast-dDrive는 WOD-E2E Test Set에서 SOTA인 ADE@3s와 ADE@5s를 달성했으며, Diffusion-Based VLA 중 가장 높은 RFS를 기록했습니다. 특히, Scaffold Spec 모드에서 기존 AR Baseline 대비 12배의 Throughput Speedup을 달성했습니다. nuScenes Validation Set에서는 Average L2 Error를 0.32m로 줄여 22%의 개선을 보였습니다. 이는 Fast-dDrive가 High-Capacity VLA와 Real-Time On-Vehicle Deployment의 Efficiency Demand 사이의 간극을 효과적으로 메운다는 것을 입증합니다. Table 4에 따르면, Fast-dDrive (Scaffold Spec + SGLang)는 AR Baseline 대비 약 11.8배 낮은 Latency (665ms vs 7855ms)와 약 11.8배 높은 TPS (608.5 vs 51.6)를 보였습니다.
4. Conclusion & Impact
본 연구는 Block-Diffusion VLA인 Fast-dDrive를 통해 Autonomous Driving Output의 내재된 구조를 활용하여 Planning Accuracy와 Inference Efficiency를 동시에 개선하는 데 성공했습니다. Deterministic Schema Token을 Frozen Scaffold로 처리하고, Diffusion Block을 Semantic Section과 정렬하며, Safety-Critical Token에 Training 시 우선순위를 부여함으로써, Fast-dDrive는 Full-Sequence Diffusion Baseline 대비 6배 높은 Throughput으로 State-of-the-Art Trajectory Accuracy를 달성했습니다.
이 연구는 Structured Generation과 Efficient Decoding이 상충하는 목표가 아니라 상호 보완적이라는 원칙을 보여줍니다. 특히 Shared-Prefix Multi-Trajectory Rollout Scheme은 Block Diffusion이 AR Model에서는 불가능한 Low-Cost Test-Time Scaling Axis를 자연스럽게 허용함을 입증합니다. 이러한 결과는 모델 출력이 알려진 구조를 가질 때, 해당 구조를 Diffusion Process에 Encoding하는 것이 Quality와 Speed 모두에서 복합적인 이득을 가져온다는 더 넓은 원칙을 제시하며, Autonomous Driving 분야의 Real-Time Deployment 가능성을 크게 향상시킬 것으로 기대됩니다.
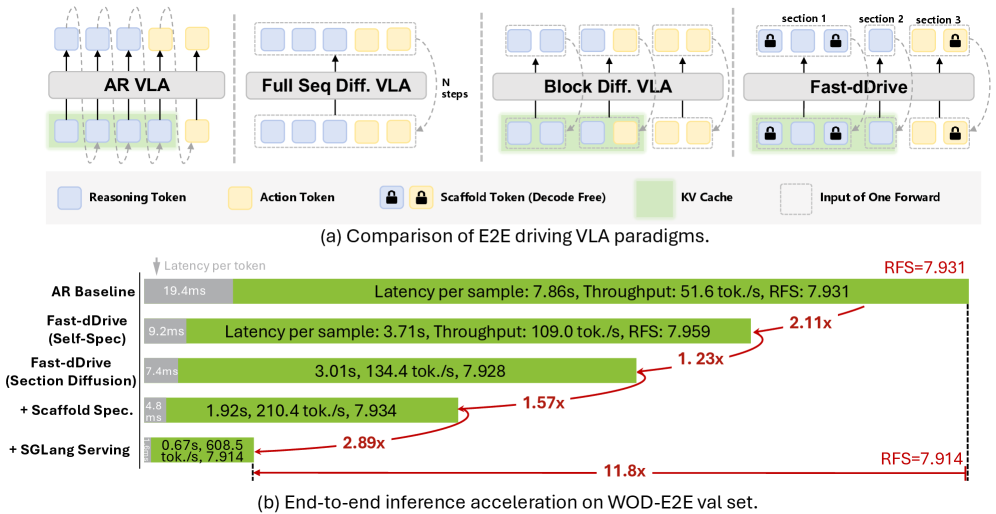
Figure 1 — VLA 패러다임 비교
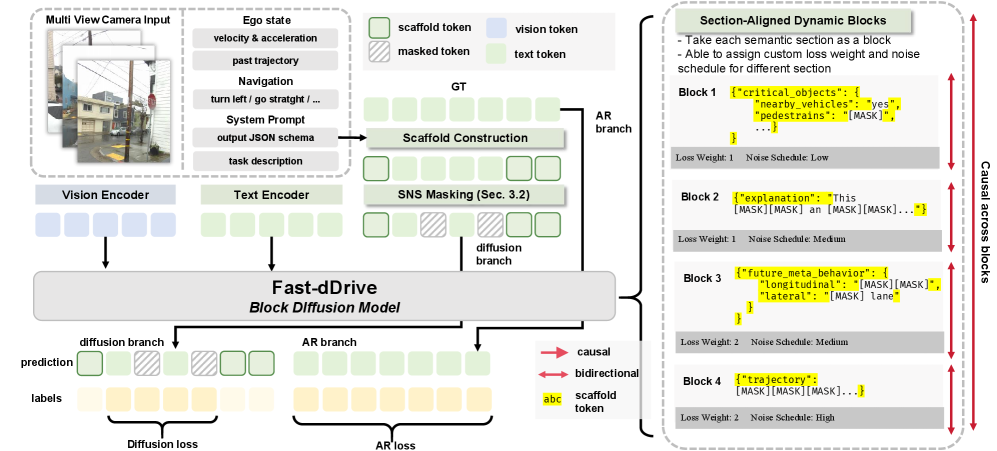
Figure 2 — Fast-dDrive 훈련 파이프라인
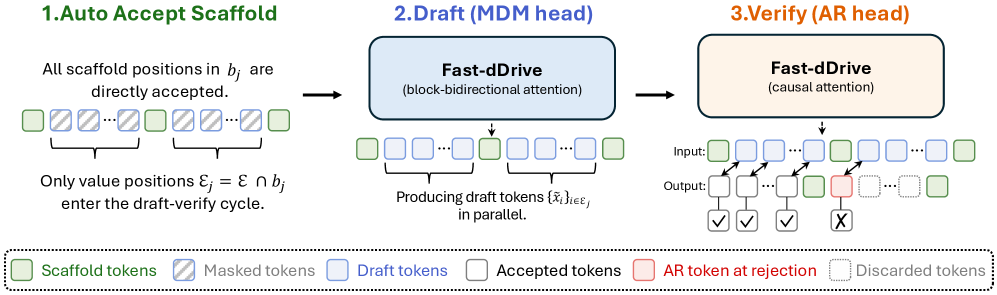
Figure 3 — Scaffold Speculative Decoding
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
- [논문리뷰] The DAWN of World-Action Interactive Models
- [논문리뷰] ECoLAD: Deployment-Oriented Evaluation for Automotive Time-Series Anomaly Detection
- [논문리뷰] UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
- [논문리뷰] OpenREAD: Reinforced Open-Ended Reasoing for End-to-End Autonomous Driving with LLM-as-Critic
Review 의 다른글
- 이전글 [논문리뷰] Everything at Every Scale: Scale-Invariant Diffusion with Continuous Super-Resolution
- 현재글 : [논문리뷰] Fast-dDrive: Efficient Block-Diffusion VLM for Autonomous Driving
- 다음글 [논문리뷰] From Pixels to Words -- Towards Native One-Vision Models at Scale
댓글