[논문리뷰] ASPIRE: Agentic /Skills Discovery for Robotics
링크: 논문 PDF로 바로 열기
메타데이터
저자: Runyu Lu, Yubo Wu, Ethan Kou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Code-as-Policy (CaP): 로봇의 동작을 명시적인 Python 프로그램 코드로 표현하여 LLM이 이를 작성, 검토, 수정할 수 있게 하는 프레임워크입니다.
- Robot Execution Engine: 로봇의 perception, planning, control API 호출에 대한 fine-grained multimodal trace를 기록하고, 에이전트가 작성한 코드의 결과를 검증하는 closed-loop 환경입니다.
- Skill Library: 에이전트가 학습 과정에서 발견한 성공적인 repair 패턴과 로봇 제어 지식을 축적하여, 향후 유사한 작업 수행 시 in-context guidance로 재사용하는 저장소입니다.
- Evolutionary Search: 단순한 단일 궤적 수정(single-trajectory refinement)을 넘어, 다양한 작업 시퀀스와 제어 프로그램을 탐색하고 최적화하기 위한 반복적 디버깅 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 로봇 제어 방식이 환경 변화나 실패 상황에서 경험을 누적하지 못하고 매번 초기화되는 문제를 해결하고자 합니다. 기존 연구(Baseline)는 태스크 단위의 coarse한 피드백에만 의존하여 실패 원인을 정확히 진단하기 어렵고, 발견된 해결책을 재사용할 수 없는 폐쇄적인 구조를 가집니다. 특히 복잡한 물리적 상호작용이 필요한 태스크에서 로봇 프로그래밍의 효율성을 극대화하기 위해, 경험을 구조화하여 전이 가능한 지식으로 내재화하는 새로운 시스템이 필수적입니다 [Figure 1].
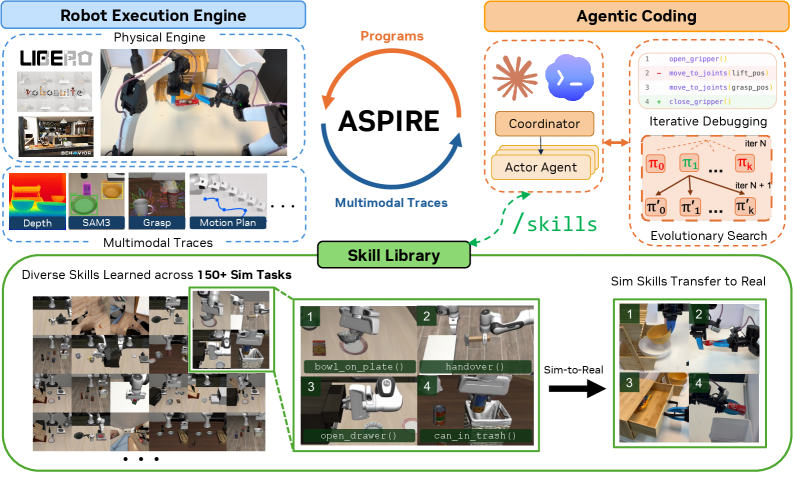
Figure 1 — Aspire 시스템 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Aspire라는 continual learning 로봇 시스템을 제안하며, 이는 로봇 execution engine, skill library, 그리고 evolutionary search라는 세 가지 핵심 구성요소로 동작합니다 [Figure 1]. Aspire는 에이전트가 로봇의 실행 트레이스를 기반으로 실패 원인을 자율적으로 진단하고, 이를 수정하여 검증된 복구 전략을 Skill Library에 저장하는 개방형 루프를 유지합니다 [Figure 2, Figure 3]. 주요 실험 결과, Aspire는 LIBERO-Pro 환경에서 기존 방법론 대비 최대 77% 성공률 향상을 보였으며, Robosuite의 bimanual handover 태스크에서는 72% 향상된 성능을 기록했습니다 [Figure 4]. 특히, LIBERO-Pro Long 태스크에 대한 zero-shot 전이 실험에서 기존 방법론이 4%의 낮은 성공률을 보인 반면, Aspire는 31%의 높은 성공률을 달성하여 전이 능력을 입증했습니다 [Figure 5]. 또한, 시뮬레이션에서 학습된 스킬이 실제 로봇(real-robot) 제어에 전이되어 토큰 비용을 대폭 줄이고 성공률을 개선하는 효과를 확인했습니다 [Table 1].

Figure 4 — 주요 벤치마크 실험 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 로봇 제어 프로그램을 자율적으로 작성 및 개선하고, 그 경험을 재사용 가능한 스킬로 축적하는 Aspire를 성공적으로 구축하였습니다. 이 연구는 로봇 학습이 단순한 end-to-end 정책 학습을 넘어, 코드로 표현된 지식을 축적하고 전이시키는 방향으로 발전할 수 있음을 입증했습니다. 학계에는 로봇 프로그래밍의 자동화와 경험 누적의 새로운 프레임워크를 제시하였으며, 산업계에는 다양한 환경과 로봇 embodiment 간의 효율적인 지식 전이 가능성을 시사합니다.
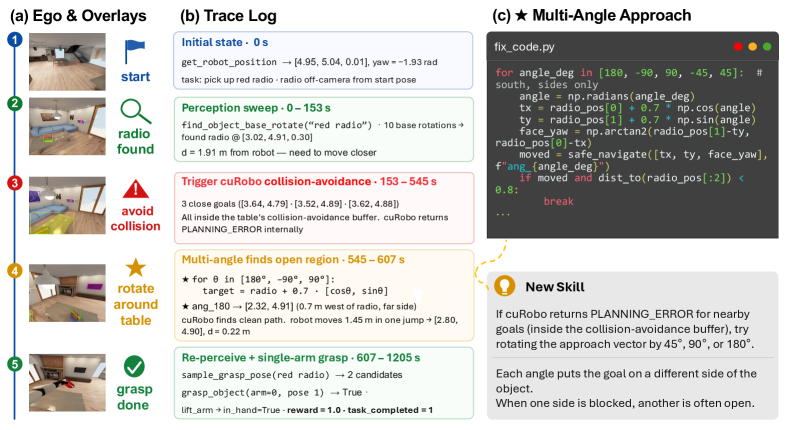
Figure 2 — 로봇 실행 엔진의 디버깅 과정
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
- [논문리뷰] Robots Need More than VLA and World Models
- [논문리뷰] π-StepNFT: Wider Space Needs Finer Steps in Online RL for Flow-based VLAs
- [논문리뷰] TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
- [논문리뷰] RoboBrain 2.5: Depth in Sight, Time in Mind
Review 의 다른글
- 이전글 [논문리뷰] AI translation of literary texts is 'fine', but readers still prefer human translations
- 현재글 : [논문리뷰] ASPIRE: Agentic /Skills Discovery for Robotics
- 다음글 [논문리뷰] AtomiMed: Hierarchical Atomic Fact-Checking for Universal Clinical-Aware Medical Report Evaluation
댓글