[논문리뷰] Rethinking Token-Level Policy Optimization for Multimodal Chain-of-Thought
링크: 논문 PDF로 바로 열기
저자: Zhaojie Liu, Jiangxia Cao, Hengrui Zhang, Hangyi Kuang, Yunheng Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Chain-of-Thought (CoT) : Large Vision-Language Models (LVLMs)가 시각적 접지(perceptual grounding)와 다단계 추론(multi-step inference)을 교차하는 추론 궤적을 구성하는 능력.
- Reinforcement Learning with Verifiable Rewards (RLVR) : 검증 가능한 보상(verifiable rewards)을 사용하여 CoT 추론을 최적화하고 성능을 개선하는 강화 학습 방법론. GRPO, DAPO 등이 이에 속한다.
- Perception-Exploration Policy Optimization (PEPO) : 시각적 인식(visual perception)과 탐색(exploration)을 결합하여 LVLM의 CoT 추론을 개선하는 토큰 수준(token-level) 정책 최적화 프레임워크.
- Visual Similarity (VS) : 응답 토큰의 hidden state와 모든 vision token의 hidden state 간의 평균 코사인 유사성으로, 각 토큰의 시각적 접지 정도를 정량화하는 지표.
- Token-level Entropy (H) : 정책 모델의 출력 logits에서 파생된 토큰 수준 엔트로피 시퀀스로, 불확실한 추론 단계 또는 전환 지점을 반영하여 모델이 여러 추론 응답을 탐색하는 영역을 나타낸다.
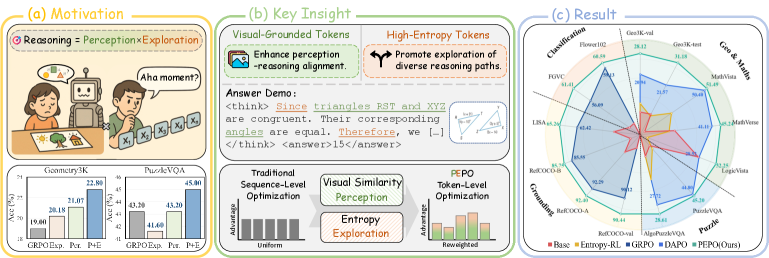
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal Chain-of-Thought (CoT) 추론은 Large Vision-Language Models (LVLMs)가 시각 정보와 다단계 추론을 통합하는 데 필수적이다. 그러나 기존 Reinforcement Learning with Verifiable Rewards (RLVR) 방법들은 CoT를 균일하게 처리하며, 시각적 접지(visual grounding)의 다양한 정도를 구분하지 않고 거친 granularily로 추론을 최적화하는 한계를 가진다. 이는 특히 시각적 접지가 응답 정확성을 결정하는 중요한 요소임에도 불구하고, 텍스트 추론이 gradient update에 더 광범위하게 기여하여 최적화 불균형을 초래한다. 또한, 기존의 entropy 기반 토큰-레벨 최적화 방식은 주로 텍스트 불확실성(textual uncertainty)을 포착하며, 시각적 의미(visual semantics)와의 연관성이 약하고 추론 관련성을 충분히 구별하지 못한다. 저자들은 이러한 한계를 극복하기 위해 시각적 접지와 탐색적 추론 dynamics의 미세한 결합을 놓치고 있는 기존 RLVR 프레임워크에 주목한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
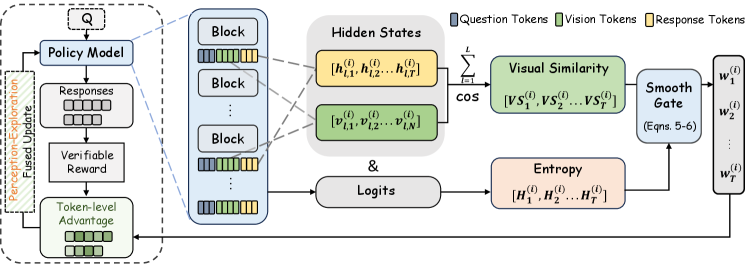
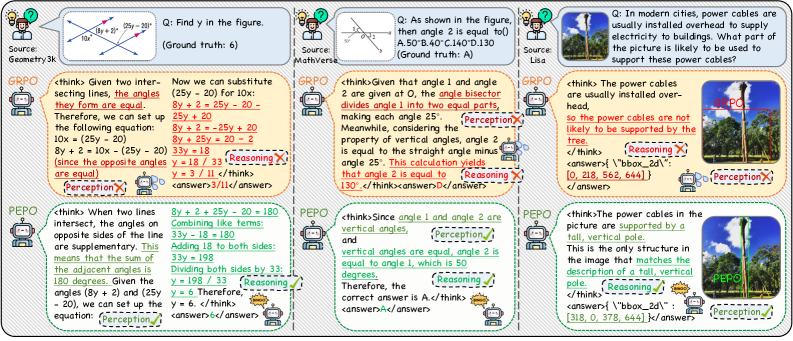
저자들은 시각적 인식과 탐색의 상호 보완적 역할을 활용하는 토큰 수준 정책 최적화 프레임워크인 Perception-Exploration Policy Optimization (PEPO)를 제안한다 [cite: 1, Figure 1]. PEPO는 hidden state 유사성으로부터 Perception prior를 도출하고, 이를 토큰 entropy와 smooth gating mechanism을 통해 통합하여 토큰 수준 advantages를 생성한다. 이 advantage는 시퀀스 수준 advantage를 재조정하여 시각적으로 접지되고 탐색적인 추론 토큰에 정책 gradient update를 유도한다 [cite: 1, Figure 1, Figure 4].
구체적으로, PEPO는 각 응답 토큰의 hidden state와 vision token state 간의 cosine similarity를 계산하여 토큰별 visual grounding score를 도출한다. 이 score는 보조 branch나 추가적인 supervision 없이 Perception prior로 활용된다. 탐색을 통합하기 위해, PEPO는 토큰 수준 entropy를 Perception prior와 결합하는 smooth gating mechanism을 사용하며, 이는 정규화된 토큰 가중치(normalized token weight)를 생성한다 [cite: 1, Figure 4]. 이 가중치 w_t는 A_t^(i) = [(1-λ) + λw_t^(i)] A^(i) 공식을 통해 시퀀스 수준 advantage A^(i)를 토큰 수준 advantage A_t^(i)로 정교화한다. 여기서 λ는 훈련 스텝에 따라 0에서 1로 선형적으로 증가한다.
다양한 멀티모달 벤치마크에 대한 광범위한 실험에서 PEPO는 기존 RL baseline 대비 일관되고 견고한 개선을 보여준다. Geometry3K, MathVista-mini, MathVerse-mini, LogicVista 벤치마크에서 PEPO_G_는 Qwen2.5-VL-3B 모델에서 GRPO 대비 평균 +3.67점 , InternVL3-2B 모델에서 +3.51점 의 성능 향상을 달성했다 [cite: 1, Table 1]. DAPO 대비해서는 Qwen2.5-VL-3B에서 +0.45점 , InternVL3-2B에서 +5.15점 향상되었다 [cite: 1, Table 1]. Visual grounding (RefCOCO, LISA-Grounding)에서는 PEPO가 IoU@50에서 +0.86 향상을 보였으며, Few-shot classification (FGVC Aircraft, Flower102)에서는 평균 정확도가 각각 +5.32점 및 +1.46점 상승했다 [cite: 1, Table 2, Table 3]. Scalability analysis에서는 ViRL39K 데이터셋을 활용하여 훈련했을 때, PEPO_G_가 GRPO 및 PAPO_G_ 대비 평균 +3.87점 높은 성능을 기록하며 더 큰 데이터셋과 복잡한 추론 태스크에서 우수한 Scalability를 입증했다 [cite: 1, Table 5]. PEPO의 계산 오버헤드는 전체 훈련 비용의 1% 미만으로, 효율성 또한 뛰어났다 [cite: 1, Table 6].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Large Vision-Language Models (LVLMs)를 위한 토큰 수준 강화 학습 프레임워크인 Perception-Exploration Policy Optimization (PEPO)를 제안한다. PEPO는 시각적 유사성(visual similarity)과 토큰 엔트로피(token entropy)를 smooth gating mechanism을 통해 결합함으로써, Perception grounding과 추론 탐색(reasoning exploration)을 동시에 모델링하는 fine-grained advantage estimation을 가능하게 한다. 두 가지 다른 아키텍처를 기반으로 한 광범위한 실험은 PEPO가 geometry reasoning, visual puzzles, visual grounding, few-shot classification 등 다양한 task에서 GRPO 및 DAPO보다 지속적으로 우수한 성능을 보이며, 동시에 대규모 멀티모달 데이터셋에서 훈련 안정성과 scalability를 유지함을 입증했다. 이 연구는 Perception과 exploration을 통합하는 것이 LVLM의 멀티모달 추론 발전에 있어 원칙적이고 효과적인 접근 방식임을 확증한다. 이러한 결과는 멀티모달 AI 시스템의 추론 능력 향상에 크게 기여하며, 특히 복잡한 시각-언어 상호작용이 요구되는 실제 응용 분야에 대한 잠재적 영향이 클 것으로 예상된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ExpSeek: Self-Triggered Experience Seeking for Web Agents
- [논문리뷰] Single-Rollout Asynchronous Optimization for Agentic Reinforcement Learning
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
Review 의 다른글
- 이전글 [논문리뷰] Regulating AI Agents
- 현재글 : [논문리뷰] Rethinking Token-Level Policy Optimization for Multimodal Chain-of-Thought
- 다음글 [논문리뷰] SIMART: Decomposing Monolithic Meshes into Sim-ready Articulated Assets via MLLM
댓글