[논문리뷰] LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
링크: 논문 PDF로 바로 열기
저자: Royden Wagner*, Ömer Şahin Taş*, et al.
키워: long-tail data, visual reasoning, autonomous driving, end-to-end driving, multi-maneuver score, chain-of-thought prompting, vision-language models
1. Key Terms & Definitions
- Long-tail Scenarios : 실세계 자율주행 도메인에서 드물게 발생하는 challenging한 driving event로, 일반적인 데이터 분포에서 벗어나는 (예: 악천후, 공사 구역, 특정 overtake maneuver) 상황들을 의미합니다.
- Multi-maneuver Score (MMS) : 제안된 새로운 평가 Metric으로, Safety, Comfort, Instruction-following을 종합적으로 고려하여 여러 가지 가능한 미래 maneuver에 대한 예측 Trajectory의 품질을 측정합니다. 단일 Expert Trajectory에 대한 L2 error를 넘어서는 평가를 가능하게 합니다.
- Chain-of-Thought (CoT) Prompting : Vision-Language Model (VLM)이 다단계 의사결정을 수행할 수 있도록, Few-shot Example에 Step-by-step reasoning trace(사고 과정)를 추가하여 모델을 안내하는 In-context Learning 기법입니다.
- Semantic Coherence : Reasoning trace에서 설명된 Driving Action이 예측된 Trajectory의 Action과 얼마나 잘 일치하는지를 정량화하는 Metric입니다. Rocchio classification 과 Sentence Embedding 을 활용합니다.
- Vision-Language Models (VLMs) : Language Model을 확장하여 Image 또는 Video 입력을 Conditional로 받아 Textual Output을 생성하는 모델들을 지칭합니다.
2. Motivation & Problem Statement
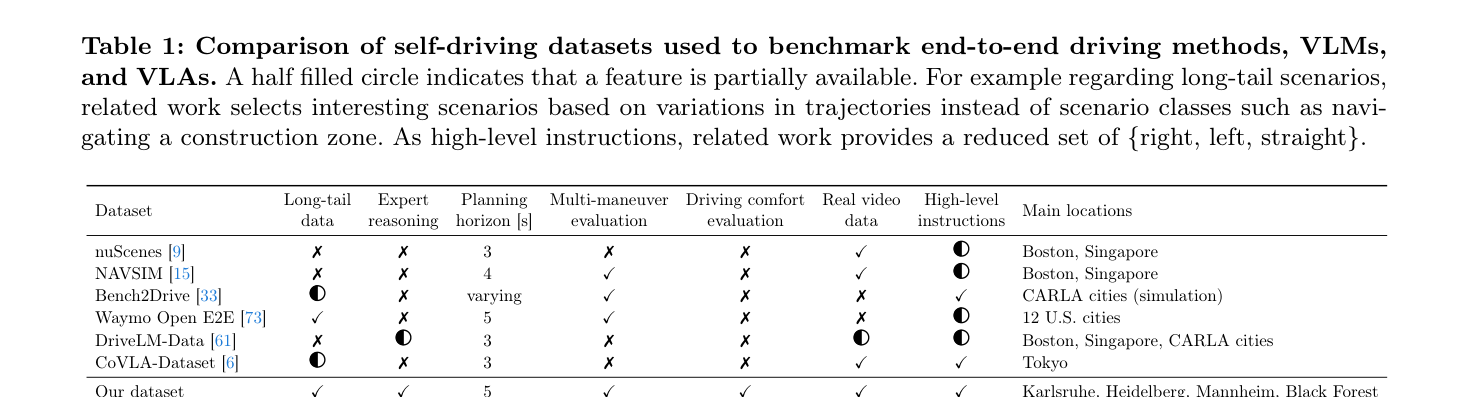
Self-driving 시스템에서 Long-tail Scenarios 에 대한 Generalization 은 여전히 근본적인 도전 과제입니다. 기존 자율주행 Dataset들은 주로 Perception Task에 초점을 맞추고 있으며, 희귀한 상황에서의 Decision-making 이나 Reasoning 과정에 대한 정보가 부족합니다. 또한, 현재 End-to-end Driving Benchmark들은 주로 단일 Expert Trajectory에 대한 L2 error를 기반으로 평가하여, 자율주행의 Multi-modality 를 간과하고 여러 Plausible Maneuver 가능성을 반영하지 못하는 한계를 가집니다. 특히, 고수준의 Driving Instruction과 Human-interpretable Reasoning Trace의 부재는 Contextual Generalization을 저해하고, 모델의 의사결정 과정을 이해하고 개선하는 데 어려움을 초래합니다. 이러한 문제점을 해결하기 위해, 본 연구는 Long-tail Scenarios에 특화된 새로운 Dataset과 평가 Metric을 제안합니다.
3. Method & Key Results
저자들은 Long-tail Driving Scenarios 에 중점을 둔 End-to-end Driving Dataset인 KITScenes LongTail Dataset 을 제안합니다. 이 Dataset은 1000개의 9초 길이 Scenario로 구성되며, Multi-view Video Data (360° FoV, Frame-wise Stitching, 3200 × 2200 px 또는 5746 x 512 stitched 해상도), High-level Instruction, 그리고 Domain Expert가 직접 Multilingual (영어, 스페인어, 중국어)로 주석한 Reasoning Trace를 포함합니다.
평가 Metric으로는 자율주행의 Multi-modality 를 반영하기 위해 Multi-maneuver Score (MMS) 를 도입합니다. MMS는 예측 Trajectory를 Expert-like, Wrong speed, Neglect instruction, Driving off road, Crash의 5가지 Reference Trajectory Category와 비교하며, Jerk 및 Tortuosity에 기반한 Comfort Penalty를 적용하여 0점(crash) 에서 10점(expert-like, no comfort penalty) 까지 점수를 부여합니다.

에서 볼 수 있듯이, MMS는 기존 DrivingScore와 높은 상관관계(Pearson r = 0.59 )를 보이며 L2 error(Pearson r = -0.45 )보다 우수함을 입증했습니다. 또한, Reasoning Trace와 예측 Trajectory 간의 일관성을 측정하는 Semantic Coherence Metric을 제시합니다.
실험 결과, Zero-shot 설정에서는 Pixtral 12B , Qwen3-VL 8B , Gemma 3 12B 와 같은 Open-source VLM들이 Long-tail Scenarios에서 취약한 Planning 성능을 보였습니다. 반면, Gemini 3 Pro 는 4.99 MMS 로 Zero-shot 설정에서 가장 높은 성능을 기록했습니다
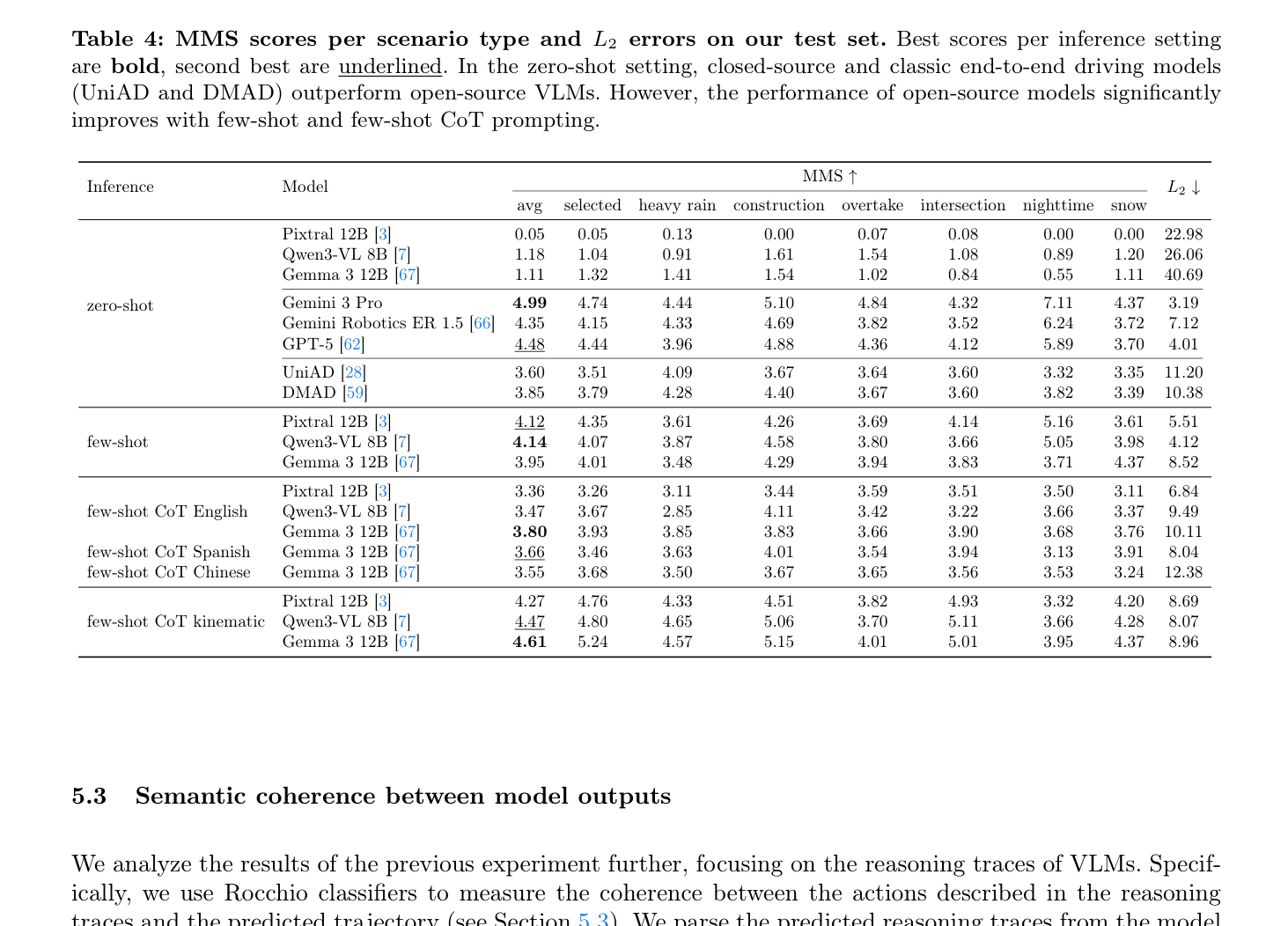
하지만 Few-shot Prompting 과 Few-shot Chain-of-Thought (CoT) Prompting 을 적용했을 때 Open-source VLM들의 성능이 크게 향상되었으며, 특히 CoT Kinematic 방법을 사용한 Gemma 3 12B 는 Test set에서 4.61 MMS , Validation set에서 4.76 MMS 로 가장 높은 MMS를 달성했습니다 [Table 4], [Table 7]. 이는 Reasoning Trace가 모델의 내부 사고 과정에 좋은 Driving Action을 포함하고 있음을 시사합니다. 하지만 [Table 5]에서 Semantic Coherence 점수는 평균 0.27~0.51 로 전반적으로 낮게 나타나, VLM들이 여전히 Reasoning Trace를 Hallucinate하거나 Unreasonable한 Trajectory를 예측할 가능성이 있음을 보여주었습니다.
4. Conclusion & Impact
본 연구는 Real-world의 Long-tail Driving Scenarios 에 대한 Generalization 문제를 해결하기 위해, Multi-view Video, High-level Instruction, Human-labeled Multilingual Reasoning Trace를 포함하는 KITScenes LongTail Dataset 을 제공합니다. 이는 VLM 및 VLA (Vision-Language-Action) 모델의 End-to-end Driving Decision-making 능력을 In-context Learning 방식으로 평가하고 개선하는 데 중요한 Resource가 됩니다. 제안된 Multi-maneuver Score (MMS) 와 Semantic Coherence Metric은 기존 L2 error 기반 평가의 한계를 극복하며, 모델의 안전성, Comfort, Instruction-following 및 Reasoning 일관성을 종합적으로 측정합니다.
이 연구는 Self-driving 분야에서 Generalization 을 향상시키기 위한 In-context Learning의 중요성을 강조하며, 특히 Reasoning Trace가 Kinematic Model과 결합될 때 Trajectory 생성에 효과적으로 기여할 수 있음을 보여줍니다. 학계와 산업계에는 Rare Event에 대한 자율주행 시스템의 Robustness와 Reliability를 높이는 데 기여할 수 있는 Dataset과 평가 프레임워크를 제공합니다. 또한, RL-based Fine-tuning, Reasoning Style 연구, World Model 평가, AI 모델의 Human-like Reasoning Trace 분석 등 다양한 후속 연구 방향을 제시하며, 투명성과 Debugging이 용이한 자율주행 시스템 개발에 중요한 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Diffutron: A Masked Diffusion Language Model for Turkish Language
- 현재글 : [논문리뷰] LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
- 다음글 [논문리뷰] Natural-Language Agent Harnesses
댓글