[논문리뷰] GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tianyi Xie, Haotian Zhang, Jinhyung Park, Zi Wang, Bowen Wen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRAIL: 3D Asset과 VFM을 활용하여 물리적 재구성 없이 휴머노이드 loco-manipulation 데이터를 생성하는 디지털 파이프라인.
- VFM (Video Foundation Model): 복잡한 사람과 객체 간의 상호작용을 합성하기 위한 비디오 생성 모델.
- HOI (Human-Object Interaction): 휴머노이드 로봇이 환경과 객체를 조작하고 이동하는 전반적인 상호작용 과정.
- Task-General Tracking: 특정 객체나 시퀀스에 국한되지 않고, 객체 인식 및 지형 파악 능력을 통해 범용적으로 로봇을 제어하는 정책.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 휴머노이드 로봇의 loco-manipulation 정책을 학습시키기 위한 데이터 수집의 높은 비용과 확장성 문제를 해결하고자 한다. 기존의 teleoperation이나 모션 캡처 방식은 물리적 환경 구축과 숙련된 배우가 필수적이며, 인-더-와일드(in-the-wild) 영상 기반 재구성 방식은 깊이 정보와 척도(scale), 객체 기하학적 정보의 모호함으로 인해 로봇이 즉시 실행 가능한 궤적을 얻기 어렵다. 이러한 한계를 극복하기 위해 저자들은 3D 환경을 사전에 지정하고, 이를 기반으로 VFM의 priors를 활용하여 로봇 친화적인 데이터를 생성하는 방식을 제안한다 [Figure 1].

Figure 1 — GRAIL 데이터 생성 및 배포 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
GRAIL은 3D Asset에서 시작하여 VFM을 통해 interaction 비디오를 생성하고, 이를 다시 기하학적으로 정밀한 4D HOI 궤적으로 복구하는 3단계 파이프라인을 제안한다 [Figure 2]. 먼저, 로봇의 morphology에 맞춘 캐릭터를 3D 환경에 배치하고, known camera intrinsics 및 extrinsics 하에서 VFM을 통해 상호작용 비디오를 합성한다. 이후, 가시성 및 기하학적 정렬을 유지하는 Joint Optimization을 수행하여 물리적으로 타당한 4D 궤적을 산출한다. 마지막으로, 이를 Unitree G1 휴머노이드에 retargeting하고, Object-Aware Adaptor와 Scene-Aware Tracker를 활용하여 범용 제어 정책을 학습시킨다 [Figure 3]. 실험 결과, 제안 방법은 기존의 HOIDiff나 CHOIS 대비 Tracking SR(Success Rate) 에서 88.9%의 높은 성능을 보였으며, 정량적인 Body Deviation 및 Object Deviation 또한 월등히 낮았다 [Table 1]. 실제 로봇 배치 환경에서 객체 Pick-up 및 계단 오르기 작업 시 각각 84%, 90%의 성공률을 기록하여 실용성을 입증했다 [Table 3].
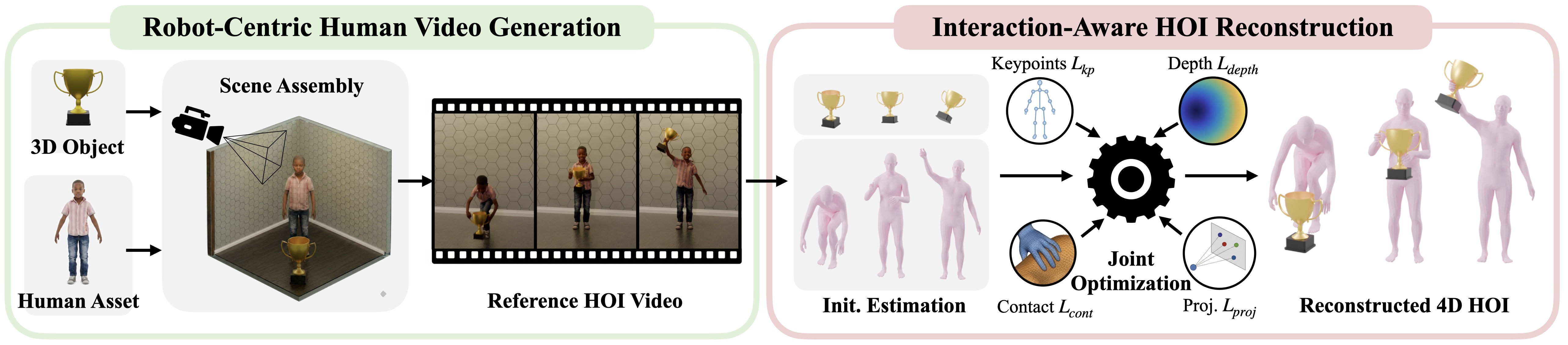
Figure 2 — 3D 에셋 기반 4D HOI 생성
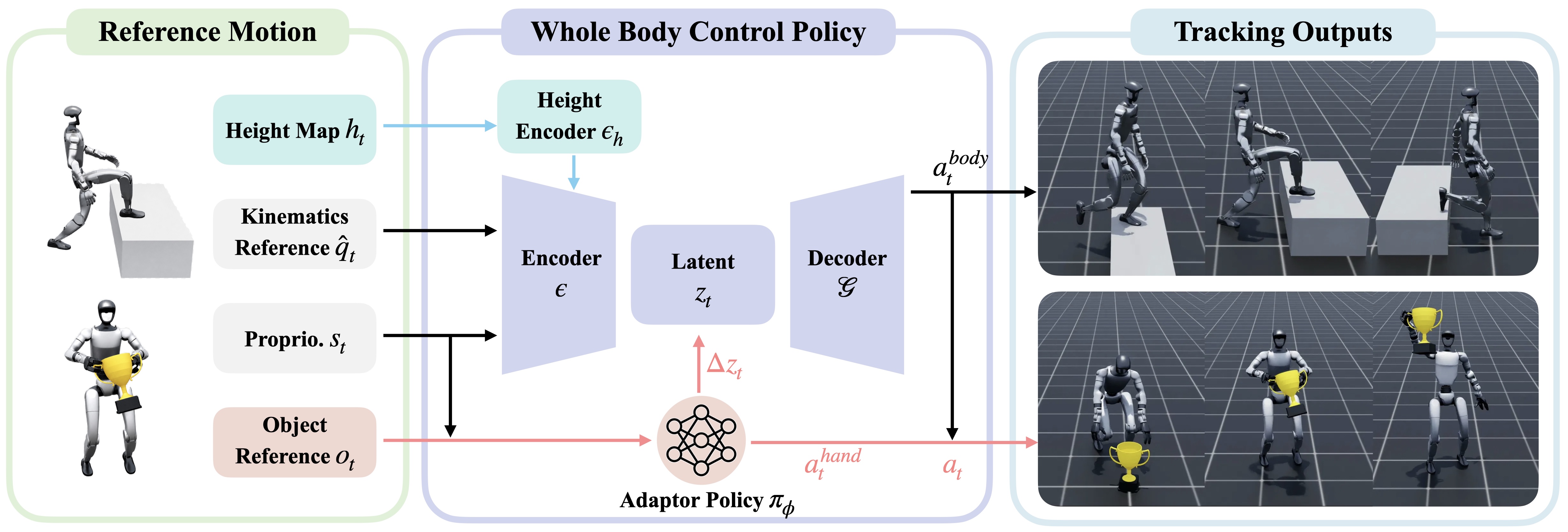
Figure 3 — 제어기 적응을 통한 범용 트래킹
4. Conclusion & Impact (결론 및 시사점)
본 논문은 물리적 제약 없이 대규모 휴머노이드 데이터를 생성하는 GRAIL 프레임워크를 통해 로봇 학습 데이터의 병목 현상을 획기적으로 개선하였다. 사전에 정의된 3D 환경과 VFM의 결합은 기존의 재구성 기법이 가진 모호성을 제거하고 로봇 친화적인 고품질 궤적을 생성한다. 이 연구는 휴머노이드 학습을 위한 데이터 생성 방식을 디지털 중심의 효율적 모델로 전환함으로써, 향후 로봇의 자율적 조작 및 이동 능력 연구에 큰 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?
- [논문리뷰] WildRelight: A Real-World Benchmark and Physics-Guided Adaptation for Single-Image Relighting
- [논문리뷰] UniVBench: Towards Unified Evaluation for Video Foundation Models
- [논문리뷰] Learning Smooth Time-Varying Linear Policies with an Action Jacobian Penalty
- [논문리뷰] Learning Humanoid End-Effector Control for Open-Vocabulary Visual Loco-Manipulation
Review 의 다른글
- 이전글 [논문리뷰] Functional Attention: From Pairwise Affinities to Functional Correspondences
- 현재글 : [논문리뷰] GRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
- 다음글 [논문리뷰] KletterMix: Climbing Toward High-Quality German Pretraining Data
댓글