[논문리뷰] LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
링크: 논문 PDF로 바로 열기
저자: Jinwoo Ahn, Ingyu Seong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- KV Cache : Transformer 기반 Large Language Model (LLM)의 autoregressive inference 과정에서 이전 토큰들의 Key 및 Value 벡터를 저장하여, 불필요한 재연산을 방지하고 efficiency를 높이는 메모리 캐시.
- KV Cache Eviction : LLM inference 시 증가하는 KV Cache 의 메모리 footprint를 줄이기 위해, 중요도가 낮은 Key-Value 쌍을 캐시에서 선별적으로 제거하는 과정.
- Lookahead Tokens : LOOKAHEADKV 프레임워크에서 도입된 학습 가능한 special token으로, 명시적인 draft generation 없이 미래 attention pattern을 예측하여 token importance score 를 추정하는 데 사용됨.
- Lookahead LoRA : LOOKAHEADKV의 parameter-efficient module 중 하나로, Lookahead Tokens 의 representation 학습을 강화하고 token importance score 예측 정확도를 높이기 위해 특정 token에 대해서만 선택적으로 활성화되는 low-rank adapter module.
- Time-to-First-Token (TTFT) : LLM이 사용자의 프롬프트에 대한 첫 번째 응답 토큰을 생성하는 데 걸리는 시간을 나타내는 지표로, inference latency의 핵심 구성 요소.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 LLM의 Context Length가 급증하면서 KV Cache 의 크기가 입력 시퀀스 길이에 비례하여 선형적으로 증가하며, 이는 long-context task 에서 메모리 병목 현상을 야기하여 inference scalability에 큰 제약을 초래하고 있습니다. 기존의 KV Cache Eviction 방법론들은 크게 두 가지 한계를 가집니다. 첫째, SnapKV 와 같은 prompt-based heuristic 은 낮은 latency 를 제공하지만, token importance score 예측의 정확도가 떨어져 eviction quality가 낮습니다. 둘째, SpecKV 나 Lookahead Q-Cache (LAQ) 와 같은 draft-based approach 는 작은 draft model을 사용하거나 SnapKV 로 partial response를 생성하여 미래 attention pattern을 ‘glimpse’하고 이를 통해 중요도를 추정하여 정확도를 높이지만, computationally expensive한 draft generation 단계가 pre-filling overhead 를 발생시켜 Time-to-First-Token (TTFT) 을 크게 증가시킵니다 [Figure 2]. 이러한 accuracy-overhead trade-off 는 latency-sensitive application 에서 long-context LLM 의 실용적인 배포를 어렵게 만들며, explicit draft generation 없이도 높은 정확도와 낮은 latency를 동시에 달성할 수 있는 새로운 KV Cache Eviction 방법론이 절실히 요구됩니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 한계를 극복하기 위해 explicit draft generation 없이 미래 attention pattern을 'glimpse'하여 KV Cache Eviction 을 수행하는 경량화된 프레임워크인 LOOKAHEADKV를 제안합니다. LOOKAHEADKV는 LLM의 Transformer Layer에 parameter-efficient module 을 추가하며, 이 모듈은 Lookahead Tokens 와 Lookahead LoRA 로 구성됩니다
 Figure 1: An overview of LOOKAHEADKV (a) Training. During training, lookahead tokens and lookahead LoRA are trained to predict the ground-truth importance scores obtained with pre-generated model response via a KL divergence loss. (b) Inference. During prefill, LOOKAHEADKV utilizes the learned modules to identify essential tokens and compress the KV cache, facilitating memory-efficient decoding.
Figure 1: An overview of LOOKAHEADKV (a) Training. During training, lookahead tokens and lookahead LoRA are trained to predict the ground-truth importance scores obtained with pre-generated model response via a KL divergence loss. (b) Inference. During prefill, LOOKAHEADKV utilizes the learned modules to identify essential tokens and compress the KV cache, facilitating memory-efficient decoding.
. Lookahead Tokens 는 학습 가능한 special token들로, true model response의 attention pattern을 예측하는 query 역할을 하며, Lookahead LoRA 는 이 token들이 더 풍부한 representation을 학습하고 token importance score 를 정확하게 예측하도록 돕습니다. 이 모듈들은 모델의 true response에서 얻은 ground-truth importance score 를 목표로 KL divergence loss 를 사용하여 fine-tuning되며, 기존 LLM의 가중치는 frozen 상태로 유지됩니다 [Figure 1].
실험 결과, LOOKAHEADKV는 광범위한 long-context understanding benchmark ( LongBench , RULER , LongProc , MT-Bench )에서 기존의 SnapKV , PyramidKV , StreamingLLM , SpecKV , LAQ 등 모든 경쟁 baseline 대비 일관되게 우수한 성능 을 보여주었습니다. 특히, 다양한 모델 (예: LLaMA3.1-8B, Qwen3-8B)과 cache budget 설정에서 LOOKAHEADKV는 LongBench 및 RULER 점수를 가장 높게 기록하여 그 effectiveness 와 robustness 를 입증했습니다
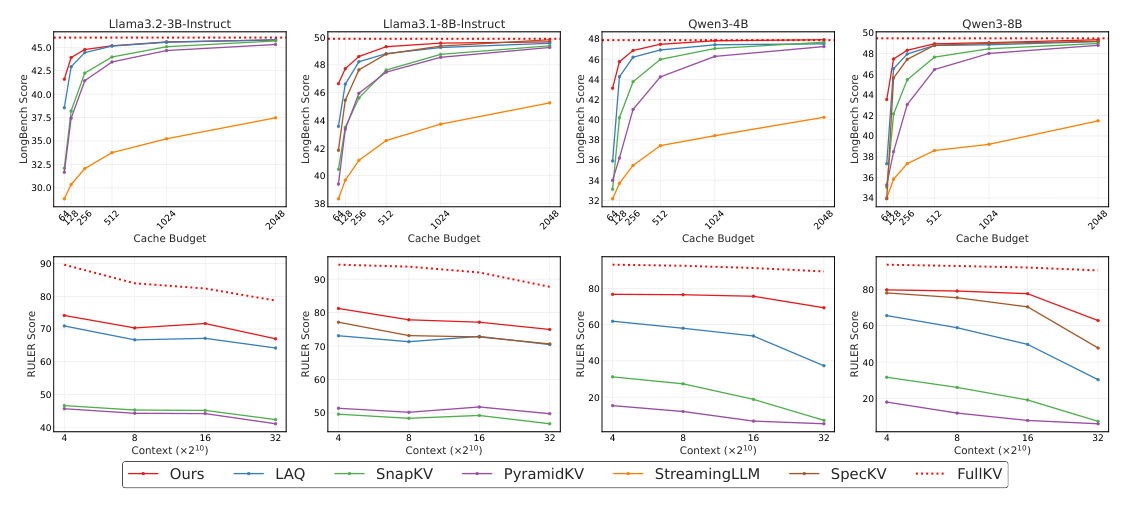 Figure 4: Top row: Average LongBench results across multiple budgets and models. Bottom row: Average RULER results across varying context lengths with a fixed budget of 128. Across all tested models, budgets and context lengths, LOOKAHEADKV consistently demonstrates superior performance.
Figure 4: Top row: Average LongBench results across multiple budgets and models. Bottom row: Average RULER results across varying context lengths with a fixed budget of 128. Across all tested models, budgets and context lengths, LOOKAHEADKV consistently demonstrates superior performance.
. Efficiency 측면에서, LLaMA3.1-8B 모델을 사용한 분석에서 LOOKAHEADKV는 32K context length에서 LAQ 대비 TTFT overhead를 14.5x 까지 줄여, prefill latency 를 2.16% 미만 으로 유지하는 negligible eviction overhead 를 달성했습니다
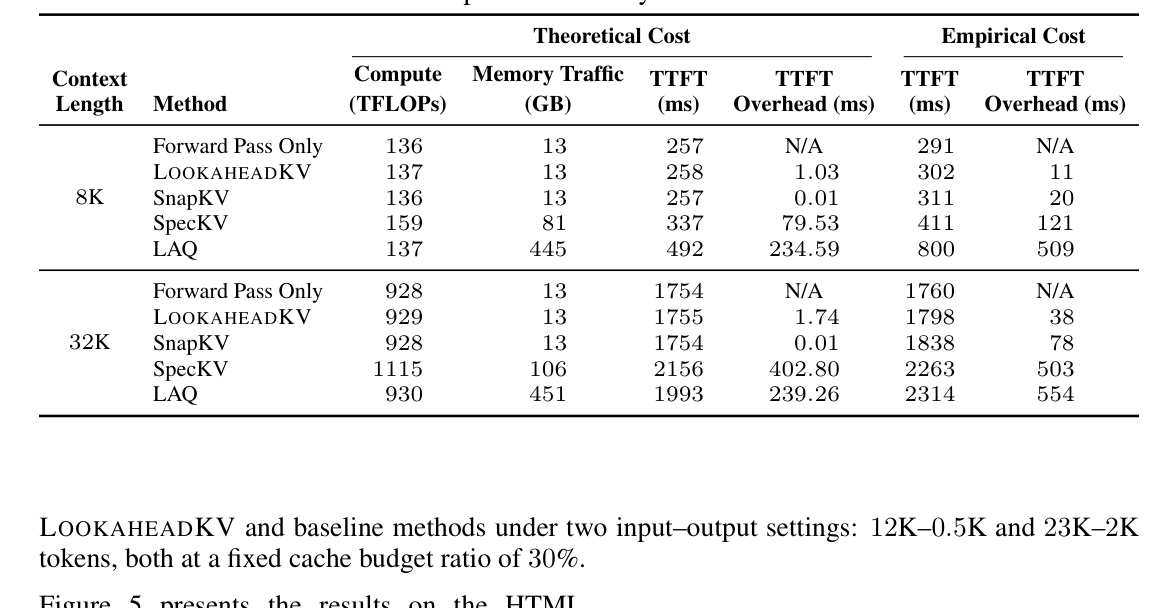 Table 3: Theoretical and empirical cost analysis of LLaMA3.1-8B at C = 128.
Table 3: Theoretical and empirical cost analysis of LLaMA3.1-8B at C = 128.
. 이러한 결과는 LOOKAHEADKV가 Draft-based approach의 높은 정확도를 유지하면서도 그들의 가장 큰 단점인 computational overhead를 효과적으로 해결했음을 보여줍니다.
4. Conclusion & Impact (결론 및 시사점)
이 논문은 KV Cache Eviction 의 정확성과 효율성 사이의 trade-off 를 효과적으로 해결하는 novel framework인 LOOKAHEADKV를 제안합니다. LOOKAHEADKV는 explicit한 Draft Generation 없이 Learnable Lookahead Tokens 와 Lookahead LoRA 를 활용하여 미래 attention pattern을 예측함으로써, 기존 Draft-based method에 필적하는 eviction quality를 달성하면서도 TTFT overhead를 최대 14.5x 까지 크게 줄였습니다. 이러한 결과는 LOOKAHEADKV가 다양한 long-context benchmark 와 모델에서 일관되게 우수한 성능 과 negligible inference overhead 를 제공함을 입증합니다. 이 연구는 long-context LLM 의 memory efficiency 와 inference latency 문제를 동시에 해결하는 중요한 기여를 하며, 특히 resource-constrained 환경이나 latency-sensitive 한 응용 분야에서 long-context LLM 을 실용적으로 배포하는 데 핵심적인 영향을 미칠 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
- [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
Review 의 다른글
- 이전글 [논문리뷰] LMEB: Long-horizon Memory Embedding Benchmark
- 현재글 : [논문리뷰] LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
- 다음글 [논문리뷰] MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
댓글