[논문리뷰] MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
링크: 논문 PDF로 바로 열기
저자: Haozhan Shen, Shilin Yan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM (Multimodal Large Language Model) : 시각 및 텍스트 데이터를 모두 이해하고 처리할 수 있는 대규모 언어 모델로, GUI 탐색과 같은 시각적 워크플로우에서 조건부 추론을 수행하는 데 사용됩니다.
- MM-CondChain : 시각적으로 Grounded된 Deep Compositional Reasoning을 위한 새로운 벤치마크로, 다단계 조건부 추론 체인을 통해 MLLM의 능력을 평가합니다.
- VPIR (Verifiable Programmatic Intermediate Representation) : 논리 구성과 자연어 렌더링을 분리하기 위해 제안된 실행 가능한 Python-like predicate 형태의 중간 표현으로, 각 계층의 조건이 기계적으로 검증 가능하도록 합니다.
- Path F1 : MM-CondChain 벤치마크의 주요 평가 지표 중 하나로, True-path Accuracy와 False-path Accuracy의 Harmonic Mean을 계산하여 모델의 균형 잡힌 성능을 측정합니다.
- Hard Negatives : 최소한의 Perturbation으로 인해 True-path와 거의 동일한 구조와 워딩을 가지지만, 실행 경로와 결과가 달라지는 Counterfactual Instance를 의미하며, 미묘한 시각적 Grounding 및 Deep Compositional Reasoning을 요구합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal Large Language Models ( MLLM )은 GUI 탐색과 같은 복잡한 시각적 워크플로우를 처리하는 데 점점 더 많이 사용되고 있지만, 이러한 Deep Compositional Reasoning 능력에 대한 평가는 여전히 부족합니다. 기존 벤치마크들은 주로 Shallow-compositions나 독립적인 제약 조건에 초점을 맞춰, 시각적 증거에 기반한 다단계 조건부 추론 체인(Chained Compositional Conditionals)을 깊이 있게 다루지 못합니다. 이는 MLLM 이 여러 시각적 요소를 추론하고 그 결과에 따라 실행 경로를 따라야 하는 복잡한 작업에서 신뢰할 수 없는 성능을 보이게 합니다. 또한, 기존 벤치마크의 Hard Negatives 는 대개 단일 계층의 작은 변화에 국한되어, 모델이 피상적인 패턴 매칭에 의존하도록 유도하는 한계가 있습니다. 이러한 제약 사항들로 인해 현재의 MLLM 이 시각적으로 Grounded된 Deep Compositional Reasoning을 얼마나 신뢰할 수 있게 따르는지 체계적으로 평가하기 어렵다는 문제가 제기됩니다. MM-CondChain 은 이러한 문제점을 해결하기 위해 Deep Compositional Reasoning 능력에 대한 보다 심층적인 평가를 목표로 합니다
 Figure 1: MM-CondChain targets visually grounded deep conditional reasoning beyond prior benchmarks.
Figure 1: MM-CondChain targets visually grounded deep conditional reasoning beyond prior benchmarks.
.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 시각적으로 Grounded된 Deep Compositional Reasoning을 평가하기 위한 벤치마크인 MM-CondChain 을 제안합니다. 이 벤치마크는 다단계 제어 흐름을 특징으로 하며, 각 단계는 시각적으로 검증 가능한 조건에 의해 Gate되어 실행 경로가 결정됩니다. 벤치마크의 확장성 및 정확성을 보장하기 위해, 저자들은 VPIR (Verifiable Programmatic Intermediate Representation) 기반의 Agentic Synthesis Pipeline을 도입합니다
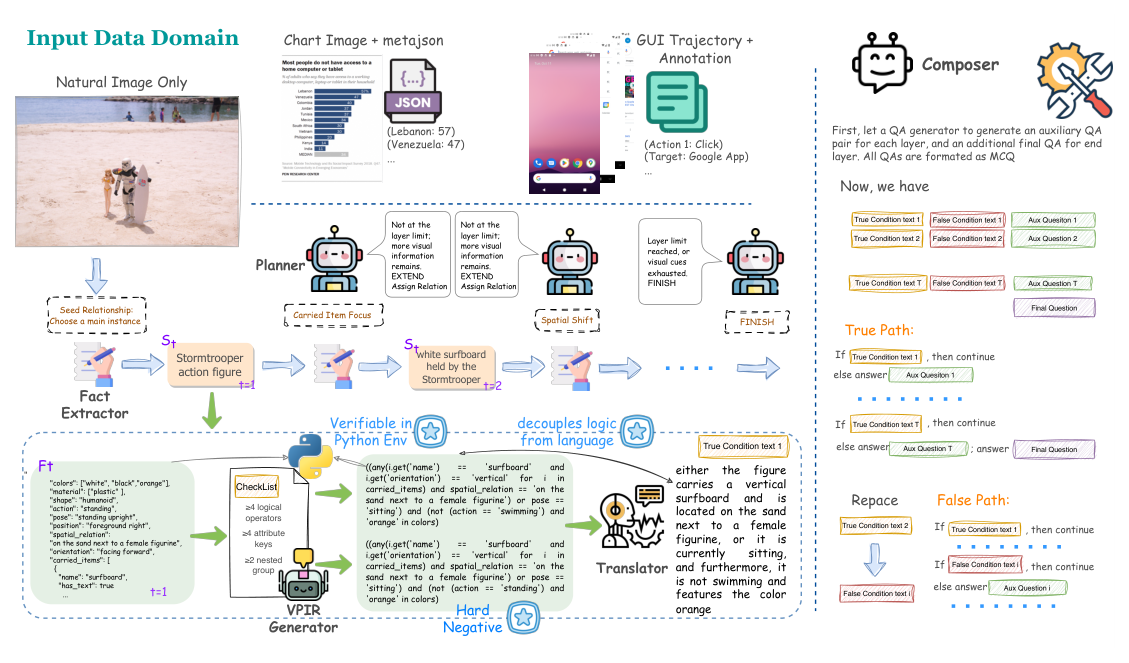 Figure 2: Overview of the MM-CondChain agentic synthesis pipeline.
Figure 2: Overview of the MM-CondChain agentic synthesis pipeline.
. 이 Pipeline은 논리 구성과 자연어 렌더링을 분리하여, 각 계층의 조건이 구조화된 시각적 사실에 대해 기계적으로 검증될 수 있도록 합니다.
이 Pipeline은 세 가지 주요 구성 요소로 작동합니다. 첫째, Planner 는 계층별로 조건부 생성을 조율하고, Verifier 는 품질 관리를 수행하여 생성된 조건이 시각적으로 Grounded되고 논리적으로 일관적인지 확인합니다. 둘째, VPIR 은 각 계층의 조건과 최소한으로 Perturb된 Counterfactual을 모두 표현하여, Hard Negatives 를 자동으로 생성할 수 있게 합니다. 셋째, Composer 는 검증된 계층을 True-path와 False-path Instance로 조합하여, 모델이 모든 조건을 정확하게 확인하고 실행 경로를 따르도록 유도합니다.
MM-CondChain 은 Natural Images, Data Charts, GUI Trajectories 세 가지 시각적 도메인에 걸쳐 구축되었으며, 최첨단 MLLM 들에 대한 광범위한 실험을 수행했습니다. 실험 결과, 가장 강력한 모델인 Gemini-3-Pro 조차 평균 53.33 Path F1 에 불과한 성능을 보였습니다
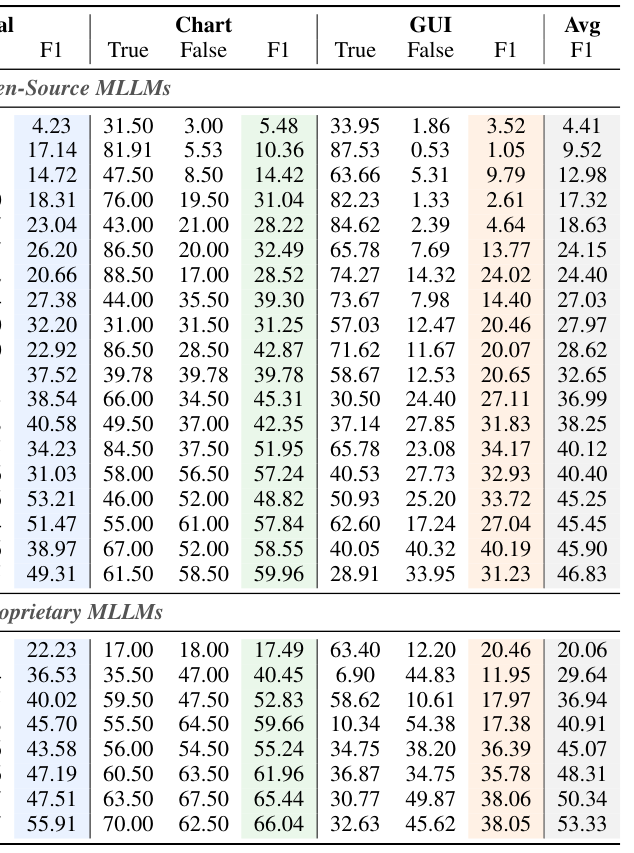 Table 3: Main results on MM-CondChain across domains.
Table 3: Main results on MM-CondChain across domains.
. 특히, False-path Hard Negatives 에서는 성능이 급격히 하락했으며, Reasoning Depth와 Predicate Complexity가 증가함에 따라 정확도가 더욱 감소했습니다. 예를 들어, Depth가 2에서 6으로 증가할 때 Path F1 이 약 29-33% 상대적으로 하락했으며, Predicate Complexity가 증가할 경우 27.7-36.0% 의 성능 저하가 관찰되었습니다. 이는 Deep Compositional Reasoning 이 현재 MLLM 에게 여전히 근본적인 도전 과제임을 시사합니다.
4. Conclusion & Impact (결론 및 시사점)
이 논문은 MM-CondChain 이라는 새로운 벤치마크를 통해 MLLM 의 시각적으로 Grounded된 Deep Compositional Reasoning 능력을 평가하는 데 중요한 기여를 합니다. 기존 벤치마크의 한계점을 극복하여, 다단계 제어 흐름과 Hard Negatives 를 통한 정밀한 평가를 가능하게 합니다. 제안된 VPIR 기반의 Agentic Synthesis Pipeline은 벤치마크 구축의 확장성과 기계적 검증 가능성을 보장하며, 논리 구성과 자연어 렌더링을 효과적으로 분리합니다. 실험 결과는 현존하는 최첨단 MLLM 조차 MM-CondChain 에서 낮은 Path F1 점수를 보이며, 특히 Depth 및 Predicate Complexity 가 증가할 때 성능이 크게 저하됨을 명확히 보여줍니다. 이는 시각적으로 Grounded된 조건부 추론이 여전히 MLLM 의 중요한 병목 현상임을 의미하며, 이 벤치마크는 모델의 약점을 진단하고 향후 더 견고한 Multi-modal Reasoning 연구를 촉진하는 데 귀중한 자원이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
- [논문리뷰] ShutterMuse: Capture-Time Photography Guidance with MLLMs
- [논문리뷰] P3D-Bench: Benchmarking MLLMs for Parametric 3D Generation and Structural Reasoning
- [논문리뷰] Towards One-to-Many Temporal Grounding
- [논문리뷰] MementoGUI: Learning Agentic Multimodal Memory Control for Long-Horizon GUI Agents
Review 의 다른글
- 이전글 [논문리뷰] LookaheadKV: Fast and Accurate KV Cache Eviction by Glimpsing into the Future without Generation
- 현재글 : [논문리뷰] MM-CondChain: A Programmatically Verified Benchmark for Visually Grounded Deep Compositional Reasoning
- 다음글 [논문리뷰] Multimodal OCR: Parse Anything from Documents
댓글